Bottom Line Up Front
Web scraping is a powerful and efficient way to gather valuable data from popular websites like Amazon, LinkedIn, and eBay.
This blog explores the top scraped websites, the kinds of data they offer, common challenges, and how no-code scrapers like Octoparse make scraping accessible to everyone.
Not all websites for web scrapingare the same and not every scraper has the same goal. If you’re a developer learning the craft, you need scrapable practice sites — free sandboxes with no legal risk and predictable structures. If you’re a business analyst, you need the real thing: Amazon for pricing data, LinkedIn for talent intelligence, Zillow for property trends.
In this article, we’ll explore the top 15 most scraped websites, the types of data they provide, and the challenges associated with extracting it. From e-commerce giants like Amazon to social platforms like LinkedIn, we’ll uncover why these websites are so popular for scraping and how you can effectively navigate the process.
Best Web Scraping Tool for Anyone
Before starting, we’d like to introduce an easy-to-use web scraping tool. Octoparse, which is designed for both non-coders and coders. With its auto-detecting function and preset scraping templates, you can scrape any popular website without coding. What’s more, you can customize the crawler with its advanced functions, such as cloud scraping, proxies, IP rotation, etc.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
What is an Octoparse task template? For programmers, to scrape the web, they can write scripts and run them in Python or whatever way. A task template is like an already written script and the only part you have to do is to figure out what data you want and enter the keywords or URLs on our task template interface. You can find the data scraping template both online and on the desktop software, try the general one below to make your web scraping easy.
https://www.octoparse.com/template/contact-details-scraper
What Types of Websites are Popular for Scraping
When it comes to web scraping, certain types of websites are more frequently targeted due to the valuable data they offer. These websites typically provide large volumes of publicly available information, making them ideal for businesses, researchers, and marketers. In this section, we’ll explore the types of websites that are most commonly scraped and why they attract so much attention.
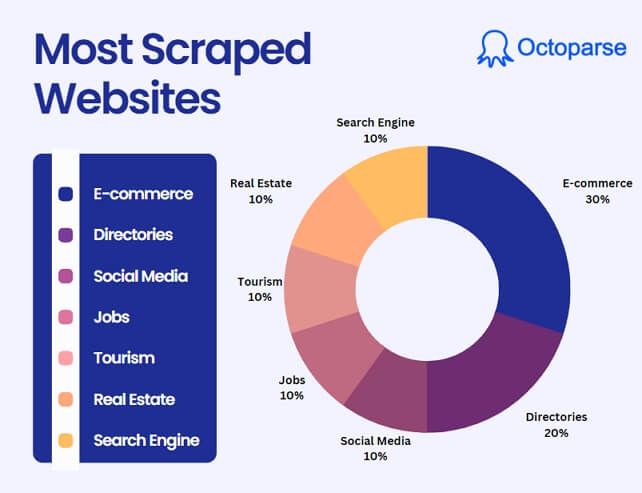
E-commerce sites
E-commerce sites are the most scraped category, both in frequency and data volume. As online shopping becomes the default, demand for pricing data, product intelligence, and review sentiment has exploded. Online sellers, retailers, and market analysts all depend on e-commerce data.
Most E-commerce websites use a hierarchical structure, such as Amazon, one of the most visited websites on the world (according to SEMRush report, Amazon has more than 2.6 billion visits per month). Users browse products in lists sorted by categories and filters. They then open pages with detailed information about each product.
The most common scraping method for e-commerce websites is list crawling: start on a category or search results page, extract all product URLs, then visit each one for detailed data. Top e-commerce targets in 2026: scraping Amazon, eBay, Etsy, Walmart.
Directories sites for leads
Directories sites earn the second rank in the race, and this isn’t surprising at all. Directories sites organize businesses by categories and thus serve as a functional information filter which is a good pick for efficient data collection.
In terms of site structure, directories show organized business lists. The homepage and category pages help users filter results. Each listing includes contact details and business info.
Many are scraping directory sites for extracting emails, phone numbers and other contact information to boost their sales leads.
Social media sites
Social media incorporates a wealth of information concerning human opinions, emotions, and daily actions. Other than that, they are often popular sites; for example, Facebook is the top 3 most visited website, gaining more than 9.6 billion visits per month.
Most social media sites feature dynamic feeds and user profiles. Content is shown in timelines or grids. Navigation sorts posts by topics, hashtags, or user connections.
Generally speaking, scraping data from social media sites is more challenging than from others. That is because many social media sites employ strong anti-scraping techniques to protect users’ privacy. Yet, social media still serves as an important source of information for sentiment analysis and all kinds of research.
Others: Jobs, Travel, Real Estate, Finance
Other sites fall into categories such as Jobs, Tourism, Real Estate, and Search Engine. People of all industries are taking advantage of the web scraping technique to exploit data value to serve their interests.
- Jobs: Indeed, Glassdoor: salary data, hiring trends, employer reviews
- Travel: TripAdvisor, Booking.com, Airbnb: hotel ratings, pricing trends, destination intelligence
- Real estate: Zillow: property prices, rental rates, neighborhood comparisons
- Search engines: Google: SERP monitoring, TDK metadata extraction, Google Maps local data
Before learning the top 15 most popular websites in detail, you should know the legality problems of web scraping. Also, you can learn the web scraping use cases for different industries.
Top 15 Most Scraped Websites
1. Amazon
Amazon is the world’s largest e-commerce platform and the most scraped website globally. With over 600 million product listings constantly updated in real time, Scraping Amazon is an unmatched data source for:
- Price monitoring and dynamic repricing strategies
- Product review and consumer sentiment analysis
- ASIN-level competitive intelligence (Best Seller Rank, seller data, buy box ownership)
- New product launch tracking across any category
- Availability and inventory fluctuation monitoring
However, scraping Amazon comes with its challenges. Amazon deploys some of the web’s most sophisticated bot detection, including behavioral fingerprinting, CAPTCHA challenges, and aggressive IP rate-limiting. Residential proxy rotation is essential for any large-scale extraction job.
| Difficulty | ⭐⭐⭐⭐ High |
| Anti-scraping | CAPTCHA · IP blocking · Behavioral fingerprinting |
| Content type | Dynamic (JS-rendered) |
Using the Octoparse Amazon template, you can gather product data like ASIN, star rating, price, color, style, reviews, and more.
https://www.octoparse.com/template/amazon-product-scraper-by-keywords
2. eBay
E-commerce websites are always the most popular websites for web scraping and eBay is one of them. eBay is another popular site for web scraping, offering a wealth of data on auctions, product listings, prices, and sales trends. The platform provides detailed information on items for sale, including product descriptions, pricing history, seller information, and bidding activity, making it a valuable resource for businesses interested in market analysis, competitive research, and tracking product pricing fluctuations.
But there are also some difficulties when scraping eBay. It uses anti-scraping measures, such as CAPTCHA and rate-limiting, to protect its servers from being overloaded by too many requests. These measures are designed to prevent bots from accessing and extracting too much data at once. Despite these challenges, with the right tools and techniques, scraping eBay’s rich database for valuable insights remains possible.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | CAPTCHA · Rate limiting |
| Best use case | Secondhand market, price history |
Octoparse’s built-in proxy rotation and IP management handle eBay’s anti-scraping defenses automatically, so you can focus on the data rather than the technical hurdles. Try the template below to start scraping eBay listings without any coding.
https://www.octoparse.com/template/ebay-scraper-store-listing
3. LinkedIn
LinkedIn, the world’s largest professional networking platform, holds a treasure trove of data on professionals, businesses, job postings, and career insights. This vast database makes LinkedIn an invaluable resource for market research, recruitment, and lead generation.
However, scraping LinkedIn presents its own set of challenges. The biggest hurdle is the frequent appearance of CAPTCHA challenges, which are put in place to protect the platform from excessive scraping. These measures prevent the site from being overwhelmed by high traffic and ensure that the data remains secure. But don’t worry, there are ways to bypass these barriers effectively and keep your scraping process smooth.
| Difficulty | ⭐⭐⭐⭐⭐ Very high |
| Best use case | Secondhand market, price history |
⚠️ Only scrape publicly visible profile data. LinkedIn actively pursues ToS violations. See the hiQ v. LinkedIn legal precedent for context.
https://www.octoparse.com/template/linkedin-job-details-scraper
4. Etsy
Etsy is a vibrant online marketplace known for its unique and handcrafted products, connecting millions of buyers with independent sellers worldwide. Founded in 2005, Etsy has cultivated a diverse community of artisans, crafters, and vintage collectors who offer a wide array of one-of-a-kind items, ranging from handmade jewelry, clothing, and home decor to vintage treasures and craft supplies.
Etsy provides a platform where sellers can showcase their craftsmanship and buyers can discover personalized, artisanal goods that often cannot be found elsewhere. It’s user-friendly interface and robust search functionality make it easy for users to browse through a vast selection of products, connect with sellers, and support small businesses and independent creators.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | Rate limiting · Some CAPTCHA |
You can scrape public data from Etsy, including product information like title, description, price, categories, etc., and shop details like shop name, seller information, ratings and reviews, stocks, etc. Try the online Etsy scraper below to extract Etsy product information.
https://www.octoparse.com/template/etsy-product-scraper
5. Yellowpages
According to Wikipedia, Yellowpages.com, also known as “YP”, was founded in 1996, and over decades of development, the site has developed into the most well-known directory website and hosts 60 million visitors per month.
For web scraping, Yellowpages is the perfect place to gather contact information and addresses of businesses based on location. If you are a retailer and find competitors in your area is as simple as a few clicks. If you are a salesman and looking to generate sales leads efficiently, Yellowpages is the right choice.
| Difficulty | ⭐⭐ Low |
| Content type | Static HTML — scraper-friendly |
You can scrape data from Yellowpages like shop name, rating, address, phone number, etc. With the help of a web scraping tool, these data can be exported into forms like Excel, CSV, and JSON.
https://www.octoparse.com/template/yellow-page-scraper
6. Google
Google is the most popular website around the world; according to SEMRush report, it has 98.2 billion monthly visits.
Google scraping divides into two high-value tracks:
- Google Search SERP: SEO teams scrape search results to monitor keyword rankings, gather title/description/meta (TDK) data, and benchmark competitor visibility. The most data-dense snapshot of any keyword’s competitive landscape.
- Google Maps: Extract local business data — name, category, phone, hours, ratings, coordinates. Essential for lead generation and local market research. Octoparse’s Google Maps template is one of its most-used.
| Difficulty | ⭐⭐⭐⭐⭐ Very high |
| Anti-scraping | reCAPTCHA v3 · Request fingerprinting |
In addition to Google search result extraction, Octoparse offers a template for Google Maps as well. Enter the URL of the search result page, and Octoparse will get you well-organized data on the related stores.
https://www.octoparse.com/template/google-search-scraper
7. Tripadvisor
The travel industry has seen a blow during the pandemic and now the recovery is happening. The need to scrape tourism websites could bounce up as well. More and more people scrape websites like Booking.com, TripAdvisor, and Airbnb to boost their business.
Tripadvisor is a popular platform for web scraping due to its vast collection of travel-related data, including user reviews, hotel ratings, restaurant recommendations, and local attractions. The site offers valuable insights into customer experiences, pricing trends, and travel destinations, making it a goldmine for businesses in the travel and hospitality industry, as well as those conducting sentiment analysis and competitive research.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | Rate limiting · Dynamic content |
https://www.octoparse.com/template/tripadvisor-scraper-hotel-details
8. Indeed
Indeed is one of the largest job search platforms, offering a vast amount of data on job listings, salaries, company reviews, and job seeker profiles. Scraping Indeed can be highly valuable for businesses, recruiters, and researchers looking to gain insights into the job market, track hiring trends, analyze salary benchmarks, and understand competitors’ recruitment strategies.
By scraping job listings and descriptions, businesses can gather data on required skills, job demand, and salary information. Additionally, extracting company reviews can provide insights into employee satisfaction and company culture. This enables businesses to make data-driven decisions and gain a competitive advantage in the recruitment process.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | Dynamic content · Some rate limiting |
https://www.octoparse.com/template/indeed-job-listing-scraper
9. X (Twitter)
X (formerly known as Twitter) has between 586 million and 666 million monthly active users worldwide. It has become more than just a social platform for communication, but also a powerful tool for branding and marketing. The massive user base makes it an ideal source for gathering data across various sectors.
Many scrape Twitter data for purposes such as industry research, sentiment analysis, and customer experience management. It does offer a vast array of data including tweets, user profiles, hashtags, mentions, and trends. Businesses often scrape Twitter to track public opinion, monitor brand mentions, and analyze customer feedback in real time.
| Difficulty | ⭐⭐⭐⭐ High |
| Anti-scraping | API throttling · Login wall · Dynamic JS |
You can extract public data from Twitter in many ways, no matter coding or non-coding. But pay attention to user privacy and other legacy problems before scraping. Or, you can try the Twitter scraping templates below to get data within several clicks.
https://www.octoparse.com/template/twitter-scraper-by-account-url
10. Craigslist
As one of the largest classified ads platforms, Craigslist offers a wealth of data on various categories, including real estate, jobs, services, and products. This vast database makes Craigslist an invaluable resource for market research, competitive analysis, and price comparison.
However, scraping Craigslist comes with its challenges. The biggest hurdle is the site’s anti-scraping measures, including CAPTCHAs and IP blocking, which prevent excessive data extraction. These measures are designed to protect the platform from being overwhelmed by too many scraping requests. But don’t worry, Octoparse can help you work around these barriers and effectively scrape Craigslist data without running into issues. Try the template below to get Craigslist data without any coding.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | CAPTCHA · IP blocking · Behavioral fingerprinting |
| Content type | Mostly static HTML |
https://www.octoparse.com/template/craigslist-scraper
11. Walmart
As Amazon’s largest US competitor, Walmart hosts over 500 million product SKUs spanning groceries, electronics, apparel, and home goods. Scraping Walmart is essential for e-commerce price parity analysis — many Amazon sellers benchmark their pricing against Walmart in real time to maintain competitiveness.
Data available: product name, price, category, reviews, availability, seller info. Walmart’s product data structure is consistent and well-organized, making it easier to extract at scale than Amazon.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | Bot detection · JS rendering required |
| Content type | Mostly static HTML |
12. Google Maps
While Google Search focuses on SERP data, Google Maps deserves its own entry. Extracting local business listings — name, category, phone, hours, ratings, reviews, GPS coordinates — is a core use case for local SEO, territory mapping, and sales lead generation. Google Maps holds structured data on hundreds of millions of businesses worldwide.
| Difficulty | ⭐⭐⭐⭐ High |
| Anti-scraping | reCAPTCHA · Dynamic JS · API limits |
Octoparse’s Google Maps template is among its most popular, allowing users to enter a search result URL and extract all listed business data in minutes.
https://www.octoparse.com/template/google-maps-advanced-scraper
13. Reddit
Reddit’s 57 million daily active users generate raw, unfiltered discussion across every niche imaginable. Scraping Reddit subreddits provides early-stage consumer sentiment, product feedback, and emerging trend signals — often weeks before those trends appear in mainstream media or review platforms.
Data available: post titles, body text, comments, upvotes, awards, flairs, user data, post timestamps. Its structured content and largely public data make Reddit one of the more accessible major platforms to scrape.
| Difficulty | ⭐⭐ Low–Medium |
| Anti-scraping | Rate limiting · API restrictions (2023+) |
https://www.octoparse.com/template/reddit-post-comments-scraper
14. Glassdoor
Where Indeed gives you job listings, Glassdoor gives you what happens inside the company: employee reviews, salary ranges, CEO approval ratings, interview processes, and company culture scores. Together, Indeed and Glassdoor form a complete employer intelligence dataset for HR teams, recruiters, and competitive analysis.
Data available: company reviews, salary reports by role and location, interview questions, benefits data, overall company ratings.
| Difficulty | ⭐⭐⭐ Medium |
| Anti-scraping | Login wall (partial) · CAPTCHA · Rate limiting |
https://www.octoparse.com/template/glassdoor-scraper
15. Zillow
The largest US real estate marketplace, Zillow holds data on over 135 million homes — active listings, sold records, rent estimates, and Zestimate valuations. Scraping Zillow enables property price trend analysis, rental market monitoring, neighborhood comparisons, and investment opportunity identification — critical data for real estate agents, investors, and PropTech startups.
Data available: property address, price, beds/baths, square footage, days on market, price history, Zestimate, agent information, listing photos.
| Difficulty | ⭐⭐ Low–Medium |
| Anti-scraping | Some rate limiting · Occasional CAPTCHA |
https://www.octoparse.com/template/zillow-details-scraper
Bonus: Best Scrapable Websites for Practice (Free Sandboxes)
Those are the 15 most valuable real-world websites to scrape in 2026. Try to use Octoparse template, you can scrap every data you need. If you are new to web scraping, these scrapable websites are built specifically for learning — no terms of service issues, no IP bans, no legal grey areas. All are completely free.
| Site | Data available | Difficulty | Best for |
| Books to Scrape books.toscrape.com | Title, price, rating, availability | Beginner | First scraping project |
| Quotes to Scrape quotes.toscrape.com | Quotes, authors, tags | Beginner | Text extraction + pagination |
| ScrapeThisSite scrapethissite.com | Country data, hockey stats, movies | Intermediate | Table parsing, login handling |
| WebScraper Test Sites webscraper.io/test-sites | Product listings (e-commerce structure) | Intermediate | E-commerce pagination practice |
| HTTPBin httpbin.org | JSON API (posts, comments, users) | Advanced | Request debugging, anti-scrape testing |
| JSONPlaceholder jsonplaceholder.typicode.com | JSON API (posts, comments, users) | Beginner | API scraping, JSON parsing |
✅ All sites above are 100% free and safe to scrape, and it is ideal for student portfolio projects and tool testing.If you’d rather skip the code entirely, Octoparse’s auto-detect feature can extract data from any of these sites in just a few clicks. Download Octoparse for free and try it on your first practice site today.
Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Final Thoughts
In summary, web scraping is a powerful tool for gathering valuable data from frequently scraped sites like Amazon, LinkedIn, and eBay. By using the right scraping tool, such as Octoparse, you can streamline your data extraction process and gain valuable insights for your business.
Always remember to scrape ethically and comply with website terms of service. Avoid triggering CAPTCHAs and ensure your activities don’t disrupt website functionality. With the right approach, web scraping can provide immense value to your business.
Download Octoparse and have a free trial to simplify your web scraping tasks and unlock valuable data effortlessly.
FAQs
1. Is web scraping legal?
Web scraping itself is legal in most jurisdictions when applied to publicly available data. However, scraping personal data, bypassing authentication, or violating a site’s Terms of Service can create legal exposure. Always check robots.txt and ToS before scraping.
2. How do I check if a website allows scraping?
Navigate to website.com/robots.txt and look for “Disallow” rules targeting the paths you want to scrape. Also read the Terms of Service for language around “automated access” or “bots.” Octoparse respects robots.txt by default.
3. What is the easiest website to scrape for beginners?
Books to Scrape (books.toscrape.com) is the standard starting point. It’s static HTML, designed specifically for learning, with no anti-scraping measures and a consistent structure across thousands of pages.
4. Which is the best tool for web scraping?
Octoparse is one of the most popular choices for both beginners and business users — no coding required, with pre-built templates for all the major sites covered in this guide. Try it free here.




