Twitter—now rebranded as X—remains one of the richest sources of public opinion data, with over 500 million tweets posted daily according to Internet Live Stats. Whether you’re tracking brand sentiment, monitoring competitors, or building datasets for research, extracting this data manually isn’t practical.
But the challenge is that Twitter’s API has become increasingly restrictive. Following the 2023 pricing changes reported by Wired, basic API access now costs $100/month for just 10,000 tweets—a 100x increase from previous tiers. For researchers and businesses needing larger volumes, enterprise plans run $42,000/month or higher.
In this article, you’ll find everything you need to start scraping data from Twitter—tweets, comments, hashtags, and profiles—without writing a single line of code. Setup takes under 5 minutes.
Quick summary: Twitter data scraping methods in 2025
| Method | Coding required | Cost | Best for |
|---|---|---|---|
| Octoparse templates | No | From $99/month, no per-tweet fees | Marketers, researchers, recurring scrapes |
| Official X/Twitter API | Yes | Free (1,500 tweets/month); $100/month for 10K | Small-scale or real-time streaming |
| Python (Playwright/Selenium) | Yes | Proxy costs only | Developers with custom needs |
| Third-party APIs (Bright Data, Apify) | Minimal | Per-record pricing; costs vary | Enterprise scale |
Is Scraping Data from Twitter Legal?
Scraping publicly available data is generally legal in the United States, following the Ninth Circuit’s 2022 ruling in hiQ Labs v. LinkedIn, which affirmed that scraping public data doesn’t violate the Computer Fraud and Abuse Act.
However, you should:
- Only collect publicly available information
- Respect Twitter’s Terms of Service regarding data usage
- Comply with privacy regulations like GDPR if collecting data on EU citizens
- Avoid scraping private accounts or direct messages
For commercial use, review Twitter’s Developer Agreement to understand what’s permitted with scraped data. When in doubt, consult legal counsel; this guide isn’t legal advice.
You can also read more about the web scraping legacy problem to learn more about “Is Web Scraping Legal?“
If you still feel at risk about the legality or compliance, you can try Twitter API. It offers access to Twitter for advanced users who know about programming. You can get information like Tweets, Direct Messages, Spaces, Lists, users, and more.
We Tested the Top Twitter Scrapers: Here’s What We Found
Testing methodology: All tests run in December 2025 using a Standard account on each platform.
- Query type: keyword-based search.
- Sample size: same 10-tweet search query across tools. Results recorded from run logs.
Speed claims vary wildly across Twitter scraping tools. We ran actual tests to see what you’re really getting.
Apify Tweet Scraper V2 – Tested December 2025

Their marketing claims 30-80 tweets per second.
Our test run: 10 tweets in 4 seconds = 2.5 tweets per second. That’s roughly 3% of the advertised speed.
Cost also differed from advertised rates. The $0.40 charge for 10 results works out to $40 per 1,000 tweets – not the “$0.30-0.40 per 1,000” shown on their pricing page. Apify’s own comparison table includes a disclaimer that “recorded speeds and costs may differ and might not accurately reflect the real metrics.”
Apify “Twitter Scraper Unlimited: No Limits” – Tested December 2025
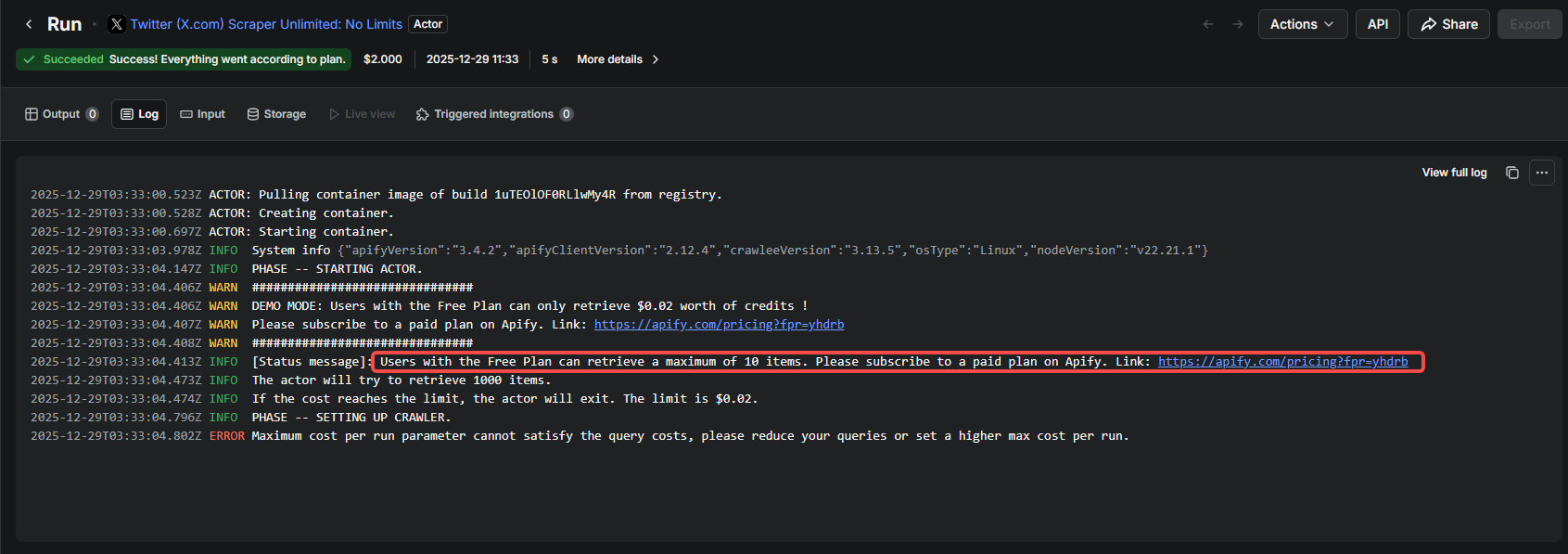
Despite the name, this scraper returned zero results while charging $2.00.
The log showed Free Plan users are capped at 10 items maximum, and the run exited with “Maximum cost per run parameter cannot satisfy the query costs” before extracting any data.
Additional restrictions we noted across Apify’s Twitter scrapers:
- Maximum 1 concurrent run
- Minimum 50 tweets per query required
- Single-tweet fetching “strictly forbidden”
- Monitoring use cases prohibited
Octoparse Twitter Templates – Updated November 2025
Twitter/X Advanced Search Scraper Current speed: 500+ tweets per minute.
https://www.octoparse.com/template/twitter-scraper-by-keywords
Cost: All Twitter/X templates included with Standard ($99/month) and Professional ($249/month) plans. No per-tweet fees. Usage draws from your plan’s task and cloud-run limits rather than per-template charges. Free trial available with limited runs.
One pattern worth knowing before you choose: when a popular free scraping template was upgraded to a paid version with better reliability and broader coverage, monthly user count dropped 44%—even though the paid version performed better in every measurable way. Free-and-adequate consistently beats paid-and-better for a meaningful slice of scraping users. If cost is a factor in your evaluation, that tradeoff is worth factoring in.
For users running regular scrapes – weekly competitor reports, ongoing hashtag monitoring, recurring audience research – the subscription model eliminates cost uncertainty. You’re not calculating whether each query justifies the per-tweet expense, or debugging why a “no limits” scraper returned nothing while charging you.
| Tool | Advertised | What we paid |
|---|---|---|
| Apify Tweet Scraper V2 | ~$4 per 1K | ~$400 per 1K |
| Apify “Unlimited” | Pay per result | $2 for nothing |
| Octoparse Standard | $99/month | $99/month (templates included) |
Bottom line: Pay-per-result pricing looks attractive at advertised rates, but verify actual costs with a test run before committing to large-scale extraction. Claimed speeds in marketing materials don’t always match production performance.
5 Twitter Data Scraping Templates: Match the Right One to Your Goal
Here are some tips to get started with Octoparse, the best web scraping tool offering diverse templates for you to choose from.
Different scraping tasks require different approaches. Here’s how to match the right twitter scraper templates to your goal:
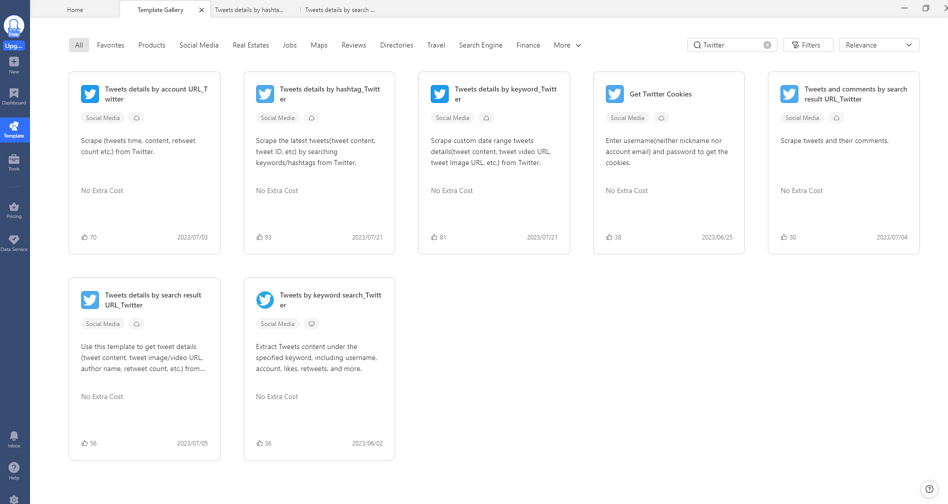
1. Scrape Comments from a Tweet
Elon Musk’s latest tweet says “Our headquarters tonight” and has almost 40k comments now. And the previous video about the new logo he tweeted has 47.5k comments already. These replies offer rich insights into public sentiment and trending discussions around the change.
With Octoparse, you can scrape replies to those tweets in two ways:
• Manually scraping all comments and replies by the Tweet URL and start a custom task
• Use a ready-made template: https://www.octoparse.com/template/tweets-comments-scraper-by-search-result-url
2. Scrape Tweets by Hashtag
You can scrape all the tweets under a specific hashtag, like #Xeet. You can find the Tweets scraper by hashtag on Octoparse, which is named Tweets details by hashtag_Twitter.
https://www.octoparse.com/template/twitter-scraper-by-hashtag
It lets you extract various information including the tweet URLs, author names and accounts, post time, image or video content, likes. Or you can scrape the tweets manually by setting up a customed workflow.
3. Scrape Twitter Search Results by Keyword
If the above tips can’t meet your needs, you can search for a keyword yourself and download the search results. Similarly, you can use a preset template provided by Octoparse, named Tweets details by search result URL_Twitter. Or you can follow the steps below to scrape tweets yourself.
https://www.octoparse.com/template/twitter-scraper-by-keywords
4. Tracking a specific account’s activity
Use the Twitter Scraper (by Account URL). Input any public profile URL and extract their complete tweet history including post content, engagement metrics (likes, reposts, replies, views), posting timestamps, and media attachments.
Best for: Competitor monitoring, influencer research, executive communications tracking
Example input: https://x.com/Octoparse
https://www.octoparse.com/template/twitter-scraper-by-account-url
5. Building follower or following lists
Use the Twitter Follower & Following Scraper (requires cookies from the Get Twitter Cookies template first). Extract complete follower/following lists with profile data for each account.
Best for: Audience analysis, lead generation, influencer vetting
Example input: https://x.com/Octoparse/followers
https://www.octoparse.com/template/twitter-follower-list-scraper
What Data Can You Actually Extract From Twitter/X?
Each scrape returns structured data you can export directly to Excel, CSV, or Google Sheets. Here’s the full field list:
Tweet-level data:
- Tweet_ID, Tweet_URL, Tweet_Content
- Posted_Time (with timezone)
- Is_Quote_Status (whether it quotes another tweet)
Engagement metrics:
- Replies_Count, Reposts_Count, Likes_Count
- Views_Count, Quote_Count, Bookmark_Count
Author profile data:
- User_Handle, User_Name, UserID, Account_URL
- Intro (bio text), Location, Website
- Follower_Count, Following_Count, Posts_Count, Media_Count
- Joined_Date, Birthdate (if public)
- Is_Blue_Verified, Professional_Category, Can_DM
This level of detail supports everything from basic content analysis to sophisticated audience segmentation—data that would require Twitter’s $42,000/month enterprise API tier to access programmatically.
How to Extract Data from X Without Coding
After learning about the specific templates for Twitter data scraping, you can also try Octoparse software for free. It’s also easy to use with the AI-based auto-detecting function, which means you can extract data from Twitter without coding skills.
Octoparse also supports a wide range of advanced scraping functions, including:
- Auto-detection of web data
- Cloud-based scraping for speed and stability
- IP rotation and CAPTCHA solving
- Flexible export formats (Excel, CSV, Google Sheets, SQL, or real-time database streaming)
The public data like account profiles, tweets, hashtags, comments, likes, etc. can be exported as Excel, CSV, Google Sheets, SQL, or streamed into a database in real-time via Octoparse. Download Octoparse and follow the easy steps below to build a free web crawler for Twitter.
Step 1: Enter the Twitter URL and Log In
Each task starts with telling Octoparse what website you target. Here are several steps guiding you to do so:
- Click Start after entering the example URL into the search bar at the top of the home screen.
Direct access to followers and following lists is prohibited on Twitter unless you have first logged in.
- Switch on Browse mode and log into Twitter as you usually do in a real browser (Please use your Twitter account to log in)
- Click the Go to Web Page action to open its settings panel (located at the bottom right)
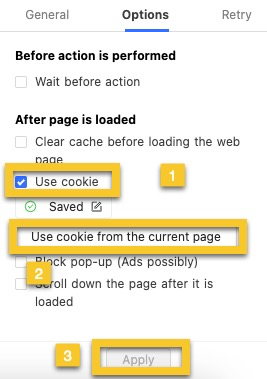
- Choose the Options tab and tick Use cookies
- Click Use cookie from the current page
- hover over Apply to save the settings
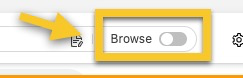
- Disable the Browse Mode
Now that we’ve successfully saved the login credentials in the task workflow, when we execute the task, our Twitter account will be logged in.
Step 2: Set up Pagination
As you can see, the website is loaded in the built-in browser. Usually, many websites have a “next page” button that allows Octoparse to click on and go to each page to grab more information.
In this case, however, Twitter applies an “infinite scrolling” technique, which means that you need to scroll down the page to let Twitter load a few more tweets, and then extract the data shown on the screen.
So the final extraction process will work like this: Octoparse will scroll down the page a little, extract the tweets, scroll down a bit, extract, and so on and so forth.
Step 3: Build a loop item
To tell the crawler to scroll down the page repetitively, we can build a pagination loop by clicking on the blank area and clicking “loop click single element” on the Tips panel.
As you can see here, a pagination loop is shown in the workflow area, this means that we’ve set up pagination successfully. Then we can start extracting data. Lets’ break down this step further:
- Extract Tweets One by One: Let’s say we want to get the handler, publish time, text content, number of comments, retweets, and likes.
- Build an extraction loop by hovering your cursor over the first tweet: When the entire tweet is highlighted in green, click to select it. Then repeat this for the second tweet. Octoparse will automatically detect and select all similar tweet elements across the page, showing its smart pattern recognition.
- Click “Extract text of the selected elements”: An extraction loop will be added to your workflow.
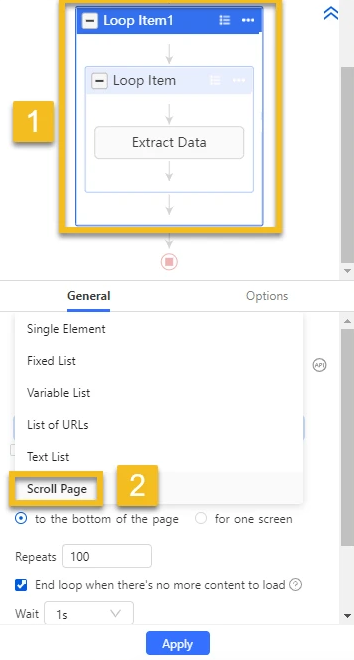
But we want to extract different data fields into separate columns instead of just one, so we need to modify the extraction settings to select our target data manually. It is very easy to do this:
- Go into the “action setting” of the “extract data” step.
- Click on the handler, and click “extract the text of the selected element”. Repeat this action to get all the data fields you want.
- Once you are finished the steps above, delete the first giant column which we don’t need, and save the crawler.
Now, our final step awaits.
Step 4: Modify the pagination settings and run the Twitter crawler
We’ve built a pagination loop earlier, but we still need a little modification on the workflow setting:
- Go to the AJAX Timeout setting and set it to 5 seconds. This ensures Octoparse waits for Twitter to load the content after each scroll.
- Set Scroll Repeats to 2 – this makes the bot scroll down two screens per cycle.
- Set Wait Time to 2 seconds – the bot will pause 2 seconds after each scroll to allow content to load.
- Go back to the Loop Item setting.
- Set the Loop Count to 20, meaning Octoparse will scroll the page 20 times in total to load more tweets.
The entire process takes under 5 minutes for setup. Actual scraping time depends on volume—expect roughly 1,000 tweets per 10 minutes on cloud execution.
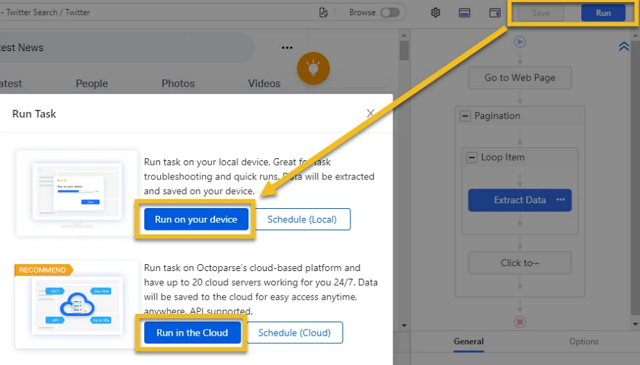
You can now run the crawler on your local device to get the data, or run it on Octoparse Cloud servers to schedule your runs and save your local resource.
💡 Note: If some fields appear blank in your extracted data, it usually means there was no corresponding content on the page for that field — so nothing was scraped.
How to Download a Twitter Dataset for Analysis
Once you’ve scraped your data, Octoparse lets you export it directly as a structured dataset—no additional formatting needed.
Supported export formats:
- CSV or Excel — for spreadsheet analysis in Google Sheets or Excel
- JSON — for developers piping data into ML pipelines or databases
- Google Sheets — live sync for team dashboards
- SQL / real-time database streaming — for production data pipelines
Each exported dataset includes all tweet-level fields (content, timestamp, engagement metrics) plus author profile data (handle, follower count, verification status). This is the same data structure you’d access through Twitter’s enterprise API tier—at $42,000/month—without the cost.
If you’re building a dataset for sentiment analysis or training an LLM, the CSV export paired with Octoparse’s scheduled cloud runs gives you a clean, repeatable pipeline.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Video tutorial: Scrape Twitter data for sentiment analysis
Twitter Data Scraping with Python
If you prefer coding your own solution, here’s the current landscape:
Tweepy (Official API wrapper)
Still functional but constrained by Twitter’s API pricing. Free tier allows only 1,500 tweets per month. Useful for small-scale projects or when you need real-time streaming, but cost-prohibitive for bulk historical data. Documentation
Twint status in 2025
Twint, the previously popular API-free scraper, is no longer maintained and doesn’t work reliably with Twitter’s current architecture. The GitHub repository shows no updates since 2022, and most users report consistent failures. If you find guides recommending Twint, they’re outdated.
Snscrape
Another previously popular option that’s now largely broken due to Twitter’s backend changes. The project has limited maintenance and inconsistent results as of late 2024.
Current working alternatives
For Python-based scraping that works in 2025, you’ll need to either use browser automation (Playwright/Selenium with proper session handling) or third-party scraping APIs. Both approaches require handling Twitter’s anti-bot measures, including rate limiting, fingerprinting, and CAPTCHA challenges.
For most non-developers, no-code tools like Octoparse handle Twitter’s infinite scroll, anti-bot measures, and session handling automatically—removing the maintenance burden that comes with keeping a custom scraper functional as X updates its frontend.
Final Thoughts
Scraping data from Twitter doesn’t require a developer budget or an API key. For most use cases, such as sentiment tracking, competitor monitoring, and building research datasets, a no-code template gets you to structured data in under five minutes. For high-volume or custom workflows, Python-based solutions remain viable but require ongoing maintenance as X’s frontend changes.
Next Steps
Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Ready to start extracting Twitter data?
- https://www.octoparse.com/template/twitter-scraper – free trial available
- You might also be interested in “how to scrape twitter for sentiment analysis“
- Read the full template documentation for advanced configuration
For related social media scraping, see our guides on LinkedIn data extraction.
FAQs
1. Can I get the Twitter API for free in 2026?
X (formerly Twitter) offers a Free tier API, but it’s limited to 1,500 tweets per month for reading, with no access to historical data. The Basic plan costs $100/month for 10,000 tweets—a significant jump for most researchers. No-code scraping tools are a common alternative; they bypass the API entirely and have no monthly tweet caps.
2. How do I download Twitter data as a dataset (CSV or Excel)?
Octoparse exports scraped Twitter data directly to CSV, Excel, Google Sheets, or JSON. Each export includes tweet content, timestamps, engagement metrics (likes, reposts, views), and author profile data. Run the scrape, click Export, and choose your format. For recurring datasets, scheduled cloud runs can deliver fresh data to a connected Google Sheet automatically.
3. Is scraping data from Twitter legal?
Scraping publicly available Twitter data is generally legal in the United States, following the Ninth Circuit’s 2022 ruling in hiQ Labs v. LinkedIn. You should only collect public data, respect Twitter’s Terms of Service, and comply with GDPR if handling data on EU citizens. This isn’t legal advice—consult a lawyer for commercial use cases.
4. How does no-code Twitter scraping compare to API-based methods?
API methods provide official, structured data access but come with rate limits and need developer expertise. For non-technical users needing scalable public data, no-code scraping is often more practical. If you feel troublesome using the Twitter scraper API, it is a good option to use no-code Twitter scraping tools like Octoparse that allow users to extract large volumes of public Twitter data quickly and easily—no programming or API keys required.
5. Do Twint and Snscrape still work in 2026?
No. Twint has had no updates since 2022 and fails consistently against Twitter’s current architecture. Snscrape is similarly broken as of late 2024. If you find guides recommending either tool, they’re outdated. Working Python alternatives in 2026 include browser automation with Playwright or third-party scraping APIs—both require handling Twitter’s rate limiting and anti-bot measures.
6. How many tweets can I collect per day without the official API?
There’s no fixed daily cap when scraping Twitter’s web interface with a no-code tool like Octoparse. Practical limits come from your cloud execution time and the speed of the tool—Octoparse’s Twitter templates run at 500+ tweets per minute on cloud. For large-scale historical pulls, running multiple scheduled tasks in parallel is the most efficient approach.