Craigslist is the largest classified website in the U.S., which has been one of the most popular portals for advertising local services and items for sale. In addition to its standing in the U.S., Craigslist also covers 70 countries and serves more than 20 billion page views per month.
On Craigslist, information is easy to read but difficult to download. It can be an extremely hard thing if you want to reuse the data or gather the specific information you need. As the API used by Craigslist only allows you to post, however, you will be unable to pull read-only data.
If you want to extract data from Craigslist but don’t know how, this is the article for you. In the following parts, you can learn about why scrape Craigslist, is it legal to scrape Craigslist, and the step-by-step tutorial.
Why Scrape Craigslist Data
Craigslist gathers an extensive array of information. Without a doubt, it is definitely one of the popular websites to scrape. Why? Here are some of the most typical reasons.
1. Structure data is more convenient
Individuals can extract first-hand information about houses, cars, computers, and many more. When exported into Excel sheets, it is much easier for them to look through and compare the data.
2. Gathering sale leads
Craigslist, similar to Yellowpages, is full of potential business leads for revenue generation. No doubt that leads are important, especially qualified ones. This is probably the reason why Craigslist appeals to so many people.
3. Gain profits by reselling goods
With scraped data in a good structure, people can better analyze prices and set new ones for reselling. However, reselling is rather in the gray area, thus this might not be a good try. It’s profitable sometimes, but the consequences may not be delightful.
4. Monitor competitors
Craigslist is full of precious information covering an array of industries where people can keep track of their competitors. Being informed of their strategies in real-time will help businesses gain an edge in competition.
Is It Legal to Scrape Craigslist
As one of the most popular websites out there to scrape, Craigslist has proved to be one of the toughest ones. The reason is simple: unlike websites that provide users with APIs to get data, Craigslist API is not aimed at pulling data off. Quite on the contrary, it is used for posting data on Craigslist.
Just like Facebook and LinkedIn, Craigslist’s terms clearly state that all sorts of robots, spiders, scripts, scrapers, and crawlers are prohibited.
Craigslist has used various technologies and legal practices to prevent being scraped for commercial purposes. In fact, in April 2017, Craigslist obtained a $60.5 million judgment against 3 Taps Inc, a company that is accused of scraping real estate listings. A few months later, Craigslist reached another $31 million judgment with Instamotor, claiming that Instamotor’s car listing service was scraped from Craigslist, and they sent unsolicited emails to Craigslist users for promotional purposes.
Nevertheless, as explained in the article “10 Myths about Web Scraping“, it is illegal if you scrape confidential information for profit, but if you scrape public data discreetly for personal use, you should be fine.
How to Scrape Data from Craigslist
Method 1: Scrape Craigslist with Python
If you are a coder, you can check out this Scrapy tutorial to learn to crawl Craigslist’s “Architecture & Engineering” jobs in New York and store the data in a CSV file.
Method 2: Extract Craigslist data by preset template
But the problem with the above tutorials is obvious: they are way too complicated for non-coders. If you have zero coding experience and want a simple and quick method, here’s a catch – use an automated data scraping tool like Octoparse.
Octoparse provides a preset Craigslist data scraping template that can help you extract Craigslist data including post address, title, price, etc. Click the link below and preview the data sample, you can try it from the webpage for free.
https://www.octoparse.com/template/craigslist-scraper
Scrap Craiglist Without Coding
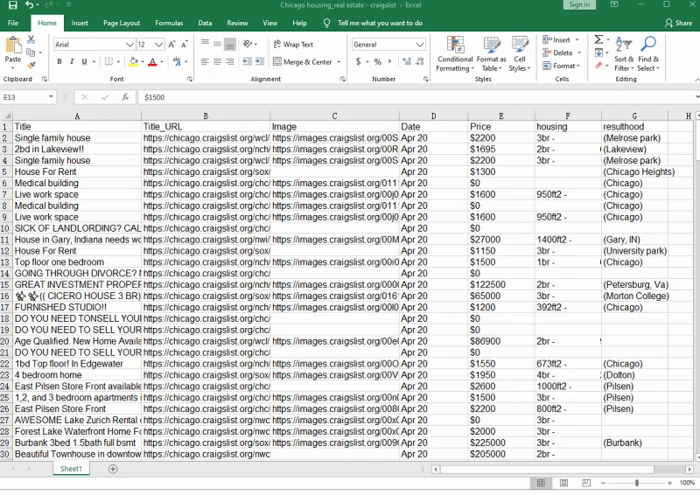
Besides the preset templates, Octoparse also provides advanced functions that allow you to customize your scraping workflow. With the power of data scraping, we can extract all the info we want from Craigslist listings within clicks and export them into Excel, CSV, HTML, and/or databases easily. In this part, you can learn how to extract Craigslist real estate listings within 3 steps using Octoparse.
In this case, let’s scrape the housing real estate for sale in Chicago. The target Craigslist URL:
https://chicago.craigslist.org/d/housing-real-estate/search/rea?lang=en&cc=gb
Before starting, please download Octoparse on your device, and launch it to create a free account.
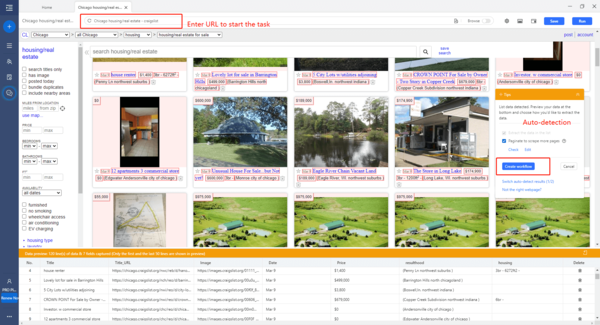
Step 1: Enter the target Craigslist URL to build a crawler
Enter the listing URL into the box, and Octoparse will start detecting the page data automatically. As you can see, the data to be extracted is highlighted in red, and the preview section below allows you to pre-edit the data fields.
Step 2: Customize the data extraction settings
After making sure that the data fields are what we want, click “Save settings” and Octoparse will auto-generate a scraping workflow on the left-hand side.
Step 3: Run the extraction to get data
Finally, you only need to save the crawler and hit “Run” to start extraction. The scraping process can be done within 5 minutes. And you can download the scraped data in an Excel or CSV file, or export to your database directly.
Conclusion
After reading this article, you’d have a general idea of scraping Craigslist now. Choose the method that is most suitable for you according to your needs.
If you want to save time and effort, Octoparse will be a better choice for you. Please note that even though this article guides you through extracting Craigslist data, you should always respect its Terms of Service and scrape at a moderate frequency.




