Your Python scraper performed perfectly until request number 51 triggered a CAPTCHA, and request 60 hit a 403 Forbidden error after the server flagged your IP address. While useful for personal privacy, anonymous proxies are critical for automated data collection at scale.
Successful scraping requires both logic and network evasion. Websites use IP addresses as a primary defense against bots to protect bandwidth and data. Consequently, high-volume requests from a single local or cloud source are quickly flagged by Web Application Firewalls (WAFs).
By the end of the article, you will get a good grasp of:
- What Is an Anonymous Proxy?
- The Three Levels of Proxy Anonymity
- The Four Ways Websites Detect Your Scraper
- What “anonymous proxy detected” means and how to fix it
- Choosing an Anonymous Proxy: Five Criteria
Quick Answer
Anonymous proxies hide your real IP address from the target servers, so they can’t apply bans, CAPTCHA challenges, and rate limits that block scrapers after a few requests. Custom scripts achieve the best success rates with paid residential proxy providers. No-code platforms like Octoparse include built-in residential proxies and automatically handle rotation and header cleaning, removing the need to manage network infrastructure yourself.
What Is an Anonymous Proxy?
An anonymous proxy, also called an anonymizer or anonymizing proxy, acts as a bridge between your scraping device and the target website. By intercepting HTTP requests, it hides your IP address and removes identifying network headers before forwarding the request. Once the server responds, the proxy relays the data back to your device.
A VPN is not the same as an anonymous proxy server. A virtual private network encrypts your traffic end-to-end at the operating system level. Useful for personal privacy, but difficult to rotate programmatically at scale. A transparent proxy is also different: it serves as a gateway but voluntarily passes your original IP address to the target.
Anonymous proxies are the network layer that keeps scrapers running. IP addresses are the primary metric modern anti-bot systems use to measure request velocity, assign reputation scores, enforce rate limits, and issue bans. If you hide your origin, your scraper will be blocked immediately.
Anonymous Proxy vs. VPN: Key Differences
| Feature | Anonymous Proxy | VPN |
| IP masking | Per-request or per-session | All traffic, system-wide |
| Encryption | None by default (HTTPS proxies encrypt) | Full end-to-end encryption |
| Rotation support | Native — rotate per request or per session | Difficult to rotate programmatically |
| Scraping suitability | High — designed for per-request control | Low — not built for high-volume rotation |
| Performance overhead | Low | Higher (encryption adds latency) |
| Best for | Large-scale scraping, geo-targeting | General privacy, secure browsing |
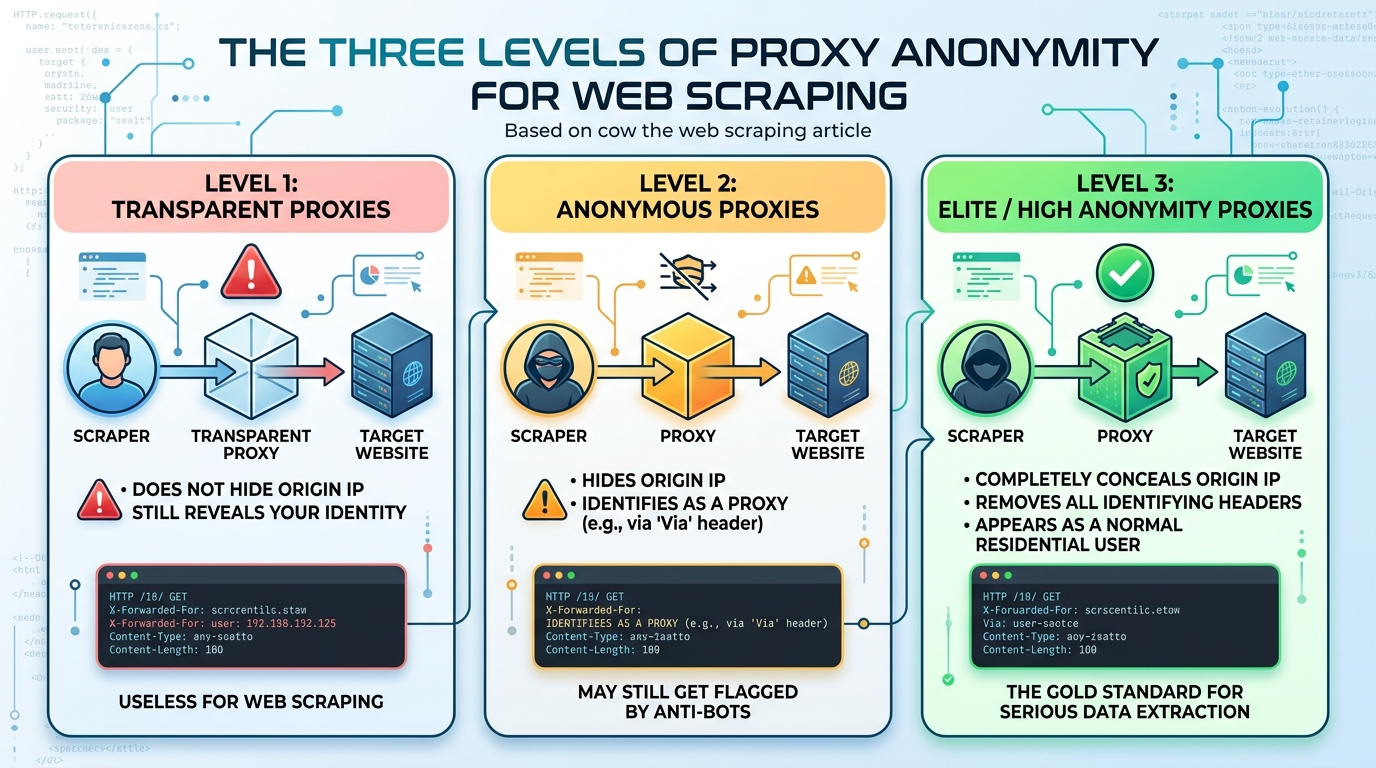
The Three Levels of Proxy Anonymity
Not every proxy is made equally. Writing effective selectors is only one aspect of building a scraping pipeline, another is comprehending proxy tiers. Based on how they handle HTTP headers, particularly the X-Forwarded-For and Via headers, proxies can be broadly divided into three strict categories.
Transparent Proxies
A transparent proxy relays your traffic but does not attempt to conceal your identity. It passes your original IP address in the X-Forwarded-For HTTP header. The server is aware of the proxy usage and knows your identity exactly. Transparent proxies are used in corporate content caching and network filtering. In web scraping, transparent proxies are useless.
Anonymous Proxies
An anonymous proxy conceals your IP address by substituting it with the proxy server’s IP address. It also appends the Via header (or other cache-control headers) to the request. This informs the server, “I am serving on behalf of a user, but I won’t tell you who they are.” Since WAFs are aware that bots rely heavily on proxies, getting caught with an anonymous proxy is a standard failure mode. When websites use proxy-detection scripts, they check for these exact headers. If they are found, your request is probably due for a CAPTCHA.
Elite / High Anonymity Proxies
This is the best way to extract data. High-anonymity proxy software removes the X-Forwarded-For and Via headers from the request body entirely. It sends absolutely no identifying information. To the server, a high-anonymity proxy appears exactly like a regular residential user accessing the web. This level of proxy is an absolute necessity for any bigger scraping operation.
The Four Ways Websites Detect Your Scraper
Without anonymous proxies, your scraper exposes four distinct attack surfaces that anti-bot systems exploit in sequence.
- IP velocity: The system applies rate limiting via its middleware when it detects excessive request traffic from a single IP address over a brief period. Octoparse’s internal tests against a mid-tier e-commerce target showed that a static datacenter IP address returned a 403 Forbidden error after the 18th request. The residential IP address handled more than 300 requests, triggering a CAPTCHA. The difference stems from IP reputation, which affects the scraper’s performance rather than its actual code.
- Header leakage: Your proxy will allow Cloudflare to identify its network via the X-Forwarded-For and Via headers, which it keeps unchanged. Elite proxies strip these headers entirely; standard anonymous proxies do not.
- Datacenter IP ranges: The system identifies requests from known cloud-hosting IP blocks, including AWS, DigitalOcean, and GCP, using its anti-bot database before they reach their destinations. Secure sites implement access controls to block datacenter IPs after users make 10-20 requests to the website.
- HTTP 429 errors, CAPTCHA, and honeypots: The three problems in the system manifest as these three issues. Your tool will damage scraped datasets through its interaction with honeypots, which are hidden links and data fields that exist on the page.
Anonymous Proxy Detected: What It Means and How to Fix It
“Anonymous proxy detected” means the target server identified your connection as coming from a proxy and blocked it. Every developer who has ever run a scraper has seen this error. It is not a rare edge case. It is the most common failure mode after the first few dozen requests.
Understanding why it happens is the first step to preventing it.
Four Causes of Detection
- Blocked IP address. Your proxy IP address already appears in anti-bot reputation databases such as IPHub and Scamalytics. Many datacenter IP ranges are pre-flagged before your first request even lands.
- Identifiable datacenter IP ranges. Hosting providers own known IP blocks. Anti-bot systems maintain constantly updated blocklists of AWS, DigitalOcean, and similar ranges and flag them on contact.
- HTTP headers not stripped. Proxies that leave X-Forwarded-For or Via headers intact signal to the server that a proxy is in use. Per IETF RFC 7239, the Forwarded header was designed precisely to carry this origin information. Elite proxies remove these headers entirely; standard anonymous proxies do not.
- Behavioral signals. Bot-detection heuristics are activated by such things as a high request frequency for a single IP, consistent mechanical timing between requests, or the absence of standard browser headers (Accept-Language, Sec-Fetch-*), regardless of the proxy tier.
How to Fix It
- Switch to residential or elite proxies. ISPs assign residential IPs to real homeowners. They are the hardest tier to detect because they generate traffic that looks identical to real user browsing.
- Enable IP rotation. Per-request rotation prevents velocity signals from accumulating on any single address.
- Mimic real browser headers. Include Accept-Language, Sec-Fetch-Mode, and a realistic User-Agent string with every request.
- Use Octoparse. Because Octoparse includes built-in residential proxies, requests already originate from real ISP-assigned IPs — eliminating the detection problem at the source rather than patching around it. You do not need a separate proxy subscription, custom rotation logic, or an IP pool to manage.
Anonymous Proxy Use Cases for Scraping
Different business intelligence pipelines require different proxy approaches. Here are the most common high-value applications.
Price Monitoring and E-Commerce Intelligence
Prices change dynamically according to inventory, demand, and competitor activity. Scraping these changes means cycling through thousands of product pages every day. Anonymizing these requests with an anonymous proxy service enables you to spread them across large IP ranges, ensuring you never hit anti-bot middleware such as Cloudflare or Akamai while scraping real-time pricing information.
Search Engine Results Page (SERP) Scraping
Google and Bing do not display the same HTML to every visitor. Their results are highly personalized and geo-targeted. If you are scraping SEO rankings, you must see what a visitor in London sees versus what a visitor in Tokyo sees. Anonymous proxies enable you to target your requests through specific geographic nodes, scraping clean, localized SERP data without geo-localization bias.
Competitor Research
If your data science team is scraping a direct competitor’s site for product data or feature updates, the last thing you want is your company’s IP address popping up in their server access logs. Anonymous proxies ensure that your competitive intelligence gathering activities remain entirely confidential.
Ad Verification
Marketing agencies must ensure their programmatic ads are displayed correctly on publisher sites worldwide. By passing the verification bots through geographically diverse proxies, it is possible to check the ad spend without the restrictions of geographic filtering or redirection.

Free vs. Paid Anonymous Proxies: What the Data Says
| Criteria | Free Proxies | Paid Residential Proxies |
| IP block rate | Very high: IPs pre-blocklisted on major WAFs | Low: residential IPs indistinguishable from real users |
| HTTPS support | Often absent: exposes auth headers in plaintext | Standard |
| Average latency | High: overcrowded shared servers | Low: dedicated infrastructure |
| Uptime | Unpredictable | 99%+ SLA from reputable providers |
| Security risk | High: potential malware injection, traffic logging | Low: audited infrastructure |
| Total cost of ownership | Hidden: engineer hours rebuilding after bans | Predictable per-GB pricing |
Free anonymous proxy lists are a poor choice for any production scraping pipeline. Public, shared IPs are overused on high-value targets like Amazon, Google, and LinkedIn, and are frequently blocklisted before you ever send a request. The time spent fixing bans and rebuilding scrapers consistently outweighs the cost of a paid provider.
Choosing an Anonymous Proxy: Five Criteria
You will need a commercial anonymous proxy server when scaling. But the proxy market can be very confusing. When you are looking to purchase anonymous proxy servers, you should not only consider the price tag, but you should also consider the technical merits of an anonymous web proxy server provider in relation to your scraping requirements.
IP Pool Size and Type
Datacenter proxies are fast and inexpensive, but their IP pool is traceable to known cloud hosting companies (such as AWS or DigitalOcean), making them easily blockable by target websites. Residential proxies, on the other hand, are actual IP addresses assigned to actual homeowners by actual Internet Service Providers (ISPs). Since they are indistinguishable from legitimate browsing traffic, they are challenging to detect. For today’s web scraping, an anonymous browsing proxy server pool with residential or ISP proxies at the elite anonymity level is the minimum technical requirement.
Rotation Mechanics
Do you need to keep a session alive to scrape data behind a login wall, or can you use a new IP for each GET request? Top providers offer configurable rotation logic, letting you choose between per-request IP rotation (great for mass scraping) and sticky sessions (which use the same IP for 10-30 minutes).
Geo-Targeting Granularity
When it comes to geo-targeted scraping, check whether the provider allows targeting IPs by country, state, city, or even ASN (Autonomous System Number).
Protocol Support
When it comes to modern-day web scraping, you need modern-day protocols. Make sure that the proxy provider supports HTTPS and SOCKS5 out of the box. The importance of SOCKS5 cannot be overstated, especially when you are scraping non-HTTP traffic or using heavy concurrency.
Success Rate SLAs
Don’t buy mindlessly. Top proxy providers such as Bright Data, Oxylabs, and Smartproxy are very open about their network success rates. You should expect a Service Level Agreement (SLA) that guarantees a success rate of >99%, and you should get a free trial to test the proxies against your target architecture.
Adding proxies to a custom Python script is easy at first, just pass a proxies={} dictionary to requests, or launch Playwright with a –proxy-server flag. That honeymoon period ends fast. Maintaining IP rotation, sticky session concurrency, header rewriting, and connection retries can add significant maintenance overhead to your codebase. If Amazon changes its bot-detection systems, you are not scraping. You are rebuilding.
No-code platforms handle proxy infrastructure differently: they remove it entirely from the user.
When You Need Octoparse with Built-in Residential Proxies
Octoparse is a no-code web scraper with built-in proxy management. It includes built-in residential proxies, so your scraping requests already originate from real ISP-assigned IPs. The same tier that proxy providers charge separately for. You do not need to purchase a proxy subscription, configure rotation logic, or manage an IP pool. The engine handles rotation, user-agent switching, and configurable request delays automatically.
For visual workflow building, Octoparse’s point-and-click interface lets you tag elements and configure pagination without writing selectors. Cloud scraping handles concurrency; you set up the workflow and collect the output.
Octoparse also works as a MCP Server, an open-standard bridge that connects AI assistants such as Claude, ChatGPT, and Cursor to its cloud scraping engine. Natural language prompts trigger scraping tasks: IP rotation, browser fingerprinting, and CAPTCHA solving run in the background. It boasts more than 600 templates covering various popular scenarios, and lets you pull structured data from Amazon, LinkedIn, Google Maps and more in seconds.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Conclusion
Web scraping projects now require anonymous proxies, as they have become essential for mission-critical data research. A network-level protection system is needed to prevent rate limiting, CAPTCHA challenges, and IP bans from stopping even the most advanced web scrapers.
If you are building your own infrastructure, invest in paid residential proxies. Requests that appear to be from real users last longer on every target. If you want to focus on the data rather than the network layer, try Octoparse: proxy rotation, header management, and CAPTCHA solving are built in, with no configuration required.
FAQs about Anonymous Proxies for Scraping
- What is the main difference between an anonymous proxy and a transparent proxy?
A transparent proxy relays your traffic but openly sends your original IP address in the X-Forwarded-For header, revealing your identity. An anonymous proxy hides your original IP address but still includes a Via or similar header, indicating that a proxy is being used.
- What is an “Elite” or “High Anonymity” proxy?
An Elite or High Anonymity proxy is the highest level of proxy anonymity. It completely removes identifying headers such as X-Forwarded-For and Via, making the request appear to come directly from a regular residential user to the target server.
- Why do websites often ban datacenter proxies before residential proxies?
IP ranges for datacenter proxies are easy to spot because they are similar to those of commercial cloud hosting providers like AWS and DigitalOcean. Websites’ anti-bot systems often maintain lists of known commercial IP ranges to block. Residential proxies, on the other hand, are IP addresses assigned by ISPs to real homeowners. They are much harder to tell apart from real user traffic.
- Are free anonymous proxies suitable for large-scale web scraping?
No. Free proxies are typically overused, already blocklisted by major WAFs, often lack HTTPS support (a major security risk), and suffer from high latency and low uptime. They are not reliable for any serious or large-scale scraping operation.
- What are ‘sticky sessions’ and when should I use them?
Sticky sessions are a type of proxy rotation setting that keeps the same IP address for a set period (e.g., 10 to 30 minutes) across multiple requests. When you need to keep a stateful session with the target server while scraping data behind a login wall, filling out multi-step forms, or doing anything else, they are very important.




