Most people think using proxies for web scraping is illegal. It’s not. The confusion comes from mixing up proxies (which are just tools) with how some people misuse them.
According to industy reports, web scraping generates $2.8 billion annually, but 73% of scrapers use proxies without understanding the legal implications. The volume, automation, and commercial intent behind proxy scraping triggers specific laws that casual proxy users never encounter.
This guide explains when proxy scraping is legal, what gets people in trouble, and how to scrape data safely without legal headaches.
The Simple Truth About Proxy Legality
Using proxies for web scraping is legal in most countries. The proxy itself doesn’t make anything illegal or legal – it’s just a tool that changes your IP address.
What matters is what you do while using the proxy. If you’re collecting public information respectfully, you’re usually fine. If you’re breaking into private accounts or stealing copyrighted content, that’s illegal whether you use a proxy or not.
The proxy scraping’s real legal issues come from:
- Ignoring a website’s terms of service
- Scraping private or personal information
- Overloading servers with too many requests
- Collecting copyrighted content without permission
Here’s what’s almost always legal:
- Scraping public product prices for comparison
- Collecting news headlines and summaries
- Gathering public social media posts (within limits)
- Research using publicly available data
In case you’d be interested in learning more about web scraping’s legality, you can learn more via this guide “Is Web Scraping Legal?”
When Proxy Scraping Gets You in Trouble
1. E-commerce price scraping is the biggest legal gray area.
Amazon, eBay, and most online stores say “no bots” in their terms of service. If you use proxies to hide large-scale price scraping, you are technically breaking these agreements.
But, thousands of companies do this daily for price comparison and market research. Because they are doing it reasonably.
When you scrape a few hundred products once a day, you are most likely fine. But if you were downloading their entire catalog every hour, ladies and gentlemen, that’s asking for trouble.
2. Social media scraping through proxies raises privacy concerns.
LinkedIn, Facebook, and Twitter have strict rules about automated data collection. Even public profiles contain personal information that’s protected in many countries.
3. News sites with paywalls are risky territory.
Using proxies to get around subscription requirements or article limits is basically theft of services. Most courts see this as clearly illegal.
4. Financial data scraping can trigger securities regulations.
Stock prices and trading data often have specific licensing rules. Large-scale collection through proxies might need legal approval.
How Websites Detect Proxy Scraping
1. Most websites know when you’re using a proxy.
They use databases that flag known proxy IP addresses instantly. Free proxies get caught immediately. Even paid proxies can be detected.
2. Your scraping behavior matters more than your IP address.
Websites look for patterns like:
- Making requests too fast for a human
- Visiting pages in an unnatural order
- Having identical timing between requests
- Accessing hidden “trap” pages that normal users never see
3. Modern detection goes beyond IP addresses.
Websites check your browser fingerprint – things like screen size, installed fonts, and how your browser renders pages. This creates a unique signature, and it can follow you across different proxy IPs.
These detection methods are designed to catch aggressive scrapers and malicious bots. So if you scrape at human speeds and respect the website’s rules, you’ll usually fly under the radar.
Companies don’t sue everyone they detect. They sue when you affect their business model or ignore warnings.
6 Simple Rules for Legal Proxy Scraping
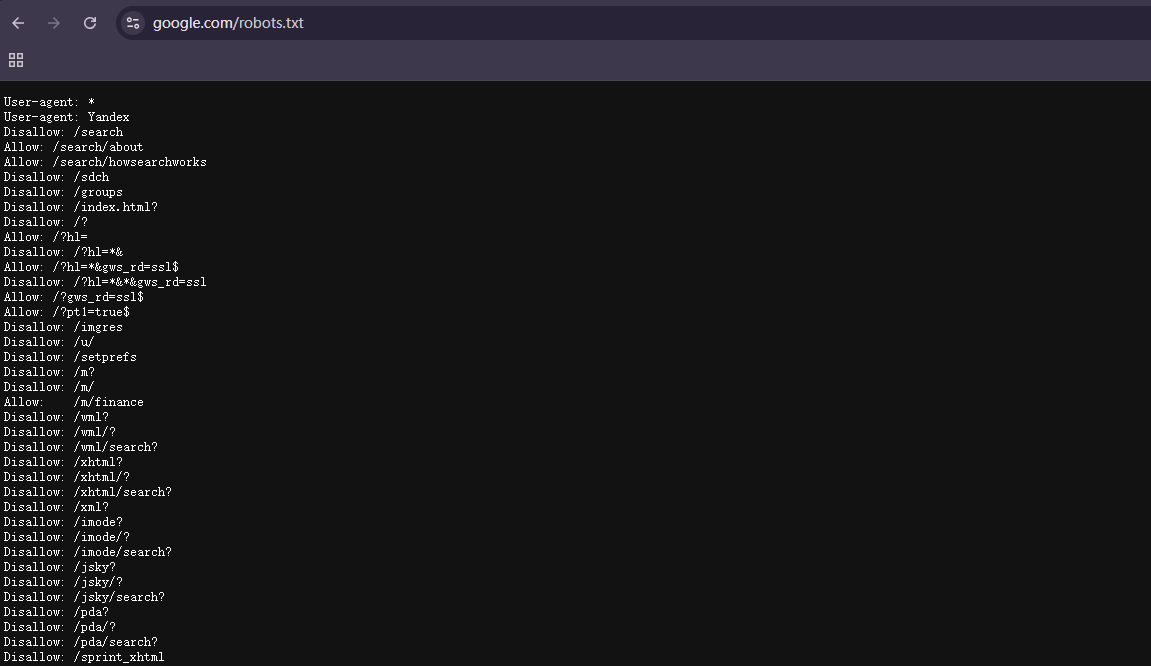
1. Check the website’s robots.txt file first.
Go to any website and add “/robots.txt” to the end (like “example.com/robots.txt”). This file tells you what the website owner is okay with bots accessing.
2. Read the terms of service.
Look for words like “automated access,” “bots,” or “scraping.” Many sites explicitly allow reasonable data collection for research or business purposes.
3. Respect rate limits and server resources.
Courts consistently distinguish between legitimate research and “server-crushing attacks.” The Meta v. Bright Data ruling noted the defendant’s respectful 2-3 second delays between requests as evidence of legitimate use.
Legally defensible rate limits:
- 1 request per 2-3 seconds (standard)
- Random delays between 1-5 seconds (better)
- Respecting 429 response codes (mandatory)
4. Stick to public information.
Don’t scrape anything behind a login, paywall, or registration form. Legally speaking, public web pages that anyone can see are much safer.
The Supreme Court’s Van Buren decision established a “gates up or down” test. Public data has gates up—anyone can access it. Authenticated data has gates down—proxies can’t legally lift them.
5. Choose legitimate proxy providers.
You should always avoid free proxies or services that promise to make you “undetectable.”
Bright Data survived multiple lawsuits because they maintain legitimate residential proxy networks through explicit user consent. Thus, I recommend picking providers that are transparent about their IP sources and have clear terms of service.
6. Document your compliance efforts.
Keep records showing you checked the robots.txt file, respected rate limits, and only collected public data. This helps if anyone questions your activities later.
How to Pick Legal Proxy Services
Good proxy providers are transparent about their IP sources. They should explain how they get their IP addresses – through partnerships with internet providers, not through malware or hacked devices.
Look for providers that support business use cases. Companies serving legitimate market research and business intelligence customers usually have higher compliance standards.
Avoid services that market themselves as “undetectable” or for “bypassing restrictions.” These often encourage breaking website terms of service.
Residential proxies from reputable providers are usually safest. They come from real internet connections and are less likely to be blocked. But they’re more expensive than datacenter proxies.
When You Need Legal Help
Large business intelligence operations should get legal review. If you’re scraping competitor data for commercial purposes, especially at scale, talk to a lawyer first.
Cross-border scraping needs special attention. Different countries have different privacy laws. What’s legal in the US might not be legal in Europe.
Personal data collection requires extra care. If you’re scraping names, emails, or any personal information, you probably need to comply with privacy laws like GDPR.
Financial or healthcare data has special rules. These industries have strict regulations about data collection and usage.
Try Using Octoparse for Compliant Scraping
The X Corp. v. Bright Data ruling specifically noted that using established tools with “legitimate business purposes” weighs against finding fraudulent intent.
Web scrapers like Octoparse reduce legal risk through built-in compliance features.
Unlike building custom scrapers with rotating proxy pools, Octoparse provides:
1. Built-in proxy management means no sketchy IP sources.
Octoparse uses legitimate proxy providers and handle rotation automatically. You don’t have to worry about accidentally using compromised IPs.
2. Rate limiting and respectful scraping are built-in.
Octoparse allows you to add delays and thus respect server resources. This adds a safe ground when you are web scraping and keeps you within legal boundaries without extra work.
3. Template-based scraping reduces legal risk.
Octoparse offers pre-built templates for popular sites have already been tested for compliance with those sites’ terms of service. Download Octoparse for a free 14-day trial today!
Conclusion
Proxy scraping is legal when done responsibly. The technology isn’t the problem – it’s how you use it that matters.
The May 2024 X Corp. v. Bright Data ruling provides the strongest protection yet for legitimate proxy use. Judge Alsup’s ruling that there’s “no affirmative duty to identify oneself with a given IP address” establishes crucial precedent.
Stay within these boundaries:
- Scrape only public data
- Respect technical limitations
- Use legitimate proxy providers
- Document compliance efforts
- Stop immediately upon receiving cease-and-desist notices
The key is being a good digital citizen. Most website owners understand that reasonable data collection is part of the internet. They just don’t want their servers overwhelmed or their private data stolen. Stay within those boundaries and you’ll be fine.
Further Reading:
Is Web Scraping Legal?
8 Best Proxy Service Providers for Web Scraping in 2025
Judge dismisses X’s web scraping case against Bright Data from PR Newswire
Global News Scraper Tool Market Size from Verified Market Reports




