Amazon, being the biggest eCommerce company in America, has the largest variety of products in the world. Data like product prices, ratings, reviews, styles, promotion information, etc., play a key role in the success of an online business.
However, there might be a misunderstanding about data extraction: people who have no idea about writing code can not scrape data from Amazon but can only use “Ctrl C + V”. Things have changed since web scraping tools appeared.
This article introduces a free Amazon product scraper that can help you collect Amazon product data without any coding to boost your online business. Also, you can learn other methods to help you scrape product data from Amazon quickly.
Why Scraping Amazon Product Data Is Important
So, here comes the question of why it is important to scrape product information from Amazon into structured data. Before starting with the how-to steps, you can learn about the benefits of scraping Amazon data and the difficulties you may have.
What data could you get on Amazon
Almost everything about products is available for scraping on Amazon. On product listing pages, you can scrape product information, including:
Take WATCH as an example, here is a sample of scraped data. On a sheet, you can see the product name, sponsored state, ASIN, rating, current price, etc. After that, with some other visual analysis tools, you can analyze the product quickly, and then you can optimize your products to attract more customers.
However, this sample only shows a small part of Amazon product data. With the help of Amazon product scrapers, you can add the details you want and have a brief view of different products to generate histograms or other diagrams with tracking data.
Benefits of scraping Amazon data
Monitor your competitors to keep competitive
Always keeping an eye on your competitors on Amazon will help you stay one step ahead in the market. Scraping and analyzing data on competitor products like pricing, description, reviews, and ratings can contribute to real-time market intelligence, so that you can identify what’s working for them and your target consumers, then adapt your own product listing accordingly.
Catch the market trends
The market is ever-changing nowadays. By collecting and analyzing data from thousands of Amazon products over time, you can get valuable insight into emerging trends, popular brands, engaging keywords, changes in consumer demand, etc., and use this info to determine if you need to launch products or improve services to meet shifting market needs.
Optimize your Amazon marketing strategy
Improving search position is important not only on Google, but also on Amazon. To improve Amazon search positions and marketing strategies, you still need the help of Amazon product data. Product titles and descriptions from your competitors’ listings can reveal what keywords and strategies are most effective. Pricing strategies, promotion techniques, key phrases, images, etc., can all drive sales. You can analyze such data to compare your KPIs, and adjust accordingly to improve click-through and conversion rates.
Improve your products and services
Consumers’ feedback is a mirror that reflects how they think about the products they buy and the services they enjoy. By paying attention to their reviews and feedback on similar Amazon products, you can learn what they want most and improve your offerings accordingly. Also, Amazon data scraping reveals specific feature requests, complaints, and competing product strengths that you can incorporate to enhance your value proposition.
Difficulties and Solutions in Scraping Amazon
While using product scrapers to pull data from Amazon, you might meet some difficulties, because they have put anti-scraping measures in place to deal with scraping needs on different scales. However, these are very common on a lot of platforms. To maximize your chances of successfully harvesting all the data you need on an ongoing basis, you’ll need to have an understanding of these measures and what anti-scraping approaches you can use to solve these problems.
| Difficulties | Solutions |
| IP blocking | IP proxy service provides rotated and residential IPs |
| CAPTCHA | Implemented CAPTCHA-solving solution |
| Page-structure change | Scraping from Amazon API |
Besides the difficulties above, you might face more complicated situations while scraping Amazon data. Below are some other approaches you can consider:
- Switching from user agents
- Using a cloud platform with cloud servers and storage
- Setting up a data monitoring system to notify you when data volumes dramatically change
- Hiring somebody to maintain the scraper once anything goes wrong
Don’t be intimidated by the complicated solutions listed there. If you scrape a top 100 product under one category just a few times, you might not need it. You might happily get the data without any problems, and you have a range of tools to choose from.
But if you need high-frequency data with a huge amount of data volume or your desired data points are rarely popular, you might need to consider more comprehensive features.
If you want to learn more about Amazon web scraping legacy and difficulties, you can keep reading this article: Is It Legal to Scrape Amazon Data.
3 Methods to Scrape Amazon Product Data
Next, you can learn three different ways to extract product data from Amazon, no matter coding or no-coding. Choose the one that is most suitable for you.
Method 1: Scrape Amazon Data by Programming
If you are a programmer and want to communicate with Amazon.com with a script, there are multiple APIs you could utilize to get Amazon data. What you need is just to code to connect to the API and easily download the data.
Amazon Product Advertising API is one of them. It is a web service and application programming interface that gives application programmers access to Amazon’s product catalog data. It is officially provided by Amazon and free to use. This API opens the doors to Amazon’s databases for users to retrieve detailed product information, reviews, and images so that they can take advantage of Amazon’s sophisticated e-commerce data and functionality.
But like most APIs, the API doesn’t provide all the information on the product page. To get those data or to realize other scraping needs such as price monitoring, you can program your own customized Amazon web scraper using Python or other languages.
Building a web scraper needs professional coding knowledge and is also time-consuming. For non-coders or programmers who want to save time, web scraping extensions and software are better choices.
Method 2: Extract Amazon Data with Web Extensions
There are many Google web scraping extensions helping people get data from web pages. Extensions are often easy to use and really leverage your browser. By using just a browser and a Chrome extension, you do not need any special software or programming skills.
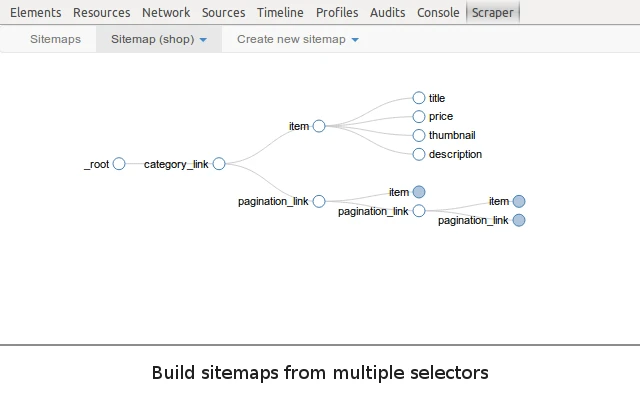
Webscraper.io is such a popular extension for extracting data from dynamic web pages. You can create a sitemap showing how the website should be traversed and what data should be extracted. With these sitemaps, Web Scraper will navigate the site anyway you want and extract data which can be later exported as a CSV.
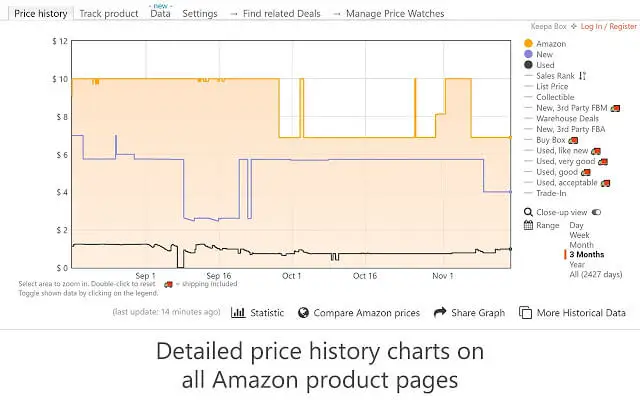
Some extensions are specially designed for scraping Amazon data. For example, Keepa is an extension used for Amazon price tracking and comparing. It can show the price history in a chart and notify you once the product dropped below your desired price.
Method 3: No Coding Amazon Product Scraper (Recommend)
The extensions do not scale well if you need lots of data or the data field is hidden deeply. For such cases, web scraping software is a better and more economical option. Web scraping software is also simple to use but quite powerful to deal with complicated scraping needs, such as scraping behind the login, infinite scroll, etc.
Octoparse is a fast and scalable web scraper. The point-and-click interface makes it easy for everyone to build their own scraper. Tons of ready-to-use scraping templates even allow you to scrape data with only several parameters entered. Octoparse also offers cloud service helping you to scrape 24/7 with faster scraping speed.
Easy Steps to Scrape Amazon Product List Using Octoparse
Steps 1: Paste Amazon product page URL to Octoparse and start auto-scraping
Download, install, and sign up for an account for free in Octoparse. Then copy the Amazon product page URL you need to scrape and paste it to the main interface of Octoparse, the auto-detect mode will start.
Steps 2: Customize the data fields
Create a workflow after the quick auto-detect. You can make more customized options like Pagination, Loop, and modify the data fields. Just finish all operations by clicking and dragging-and-dropping.
Steps 3: Download Amazon product data in Excel
Once you have selected all wanted data fields and ensured the workflow works well, click on the “Run” button and select a running mode for your task. Finally, you can export the scraped data as local files like Excel, CSV, HTML, etc., or to databases like Google Sheets.
You can check out more details from the How to Scrape product information from Amazon tutorial if you still have any questions. What’s more, Octoparse provides Amazon product data scraping templates, and you can get the data within a few clicks. Find them in the Task Template panel after you download Octoparse.
Final Words
Amazon is a gold mine of data. Scraping product data from Amazon can help you understand the market, trends, and your competitors. It can be the key to your business success. Using web scraping tools like Octoparse, anyone can create Amazon product scrapers and use the data without having any coding knowledge. You should give Octoparse a try if you own or plan to own an online business. Start here and get the right data for business growth.




