Python is the most common and popular programming language for web scraping. Many online shop owners have been scraping Amazon data with Pytho to improve their business strategies. However, it is hard for those who have no knowledge base about coding. Then, choose another no-coding web scraping tool will be a better choice.
In this article, we’ll walk you through how to use Python to scrape Amazon and collect Amazon data more effortlessly with a no-coding Amazon scraper.
How to Scrape Amazon Data with Python
Python is a widely used programming language for web scraping because many web frameworks are written in Python nowadays. Many Python libraries like BeautifulSoup and Selenium make parsing HEML and scraping dynamic websites easier, and people can use them to automate scraping tasks and processes through scripts.
How to Scrape Amazon With Python
Step 1: Install the library Requests to get the HTML content, and BeautifulSoup to parse the HTML content.
Step 2: Use the Requests library to send a GET request to the Amazon page you want to scrape. Then you’ll get the HTML of the page.
Step 3: Pass the HTML to BeautifulSoup to create a soup object. It’ll allow you to parse the HTML.
Step 4: Find the data you want to scrape from HTML. For Amazon products, you might need product titles, descriptions, prices, ratings, review counts, etc.
Step 5: Extract the text and attributes from the HTML elements with BeautifulSoup.
Step 6: Store the extracted data in a data structure such as a list, dictionary, or Pandas DataFrame.
Here is a sample of how to scrape Amazon product titles from a page using BeautifulSoup:
The process of this Amazon scraper is to send a GET request to the Amazon search page for laptops and retrieve the HTML content. Then use BeautifulSoup to parse it and extract the product titles using a CSS selector.
Although Python scripts are relatively simple and readable compared to other languages, building an Amazon data scraping with Python is challenging for people who have no experience in coding. That’s where no-coding Amazon scrapers come in.
No-coding Alternative: Scrape Amazon Data Within a Few Clicks
If you prefer not writing Python scripts, you can also build an Amazon scraper with a few clicks. Octoparse is an easy-to-use web scraping tool that anyone can use regardless of their coding skills. Also, Octoparse has powerful features like bypassing cloudflare and CAPTCHAs that can help web scraping be more effortless and automatic.
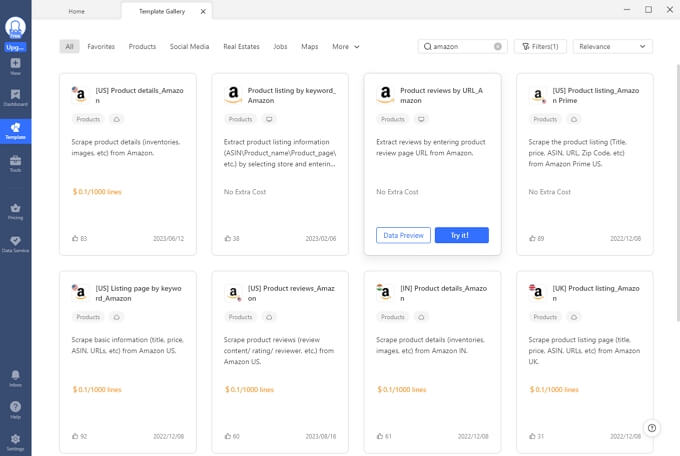
Preset templates
Octoparse now offers more than 100 preset templates for scraping data from particular websites. Templates allow you to extract data with zero setups by entering a couple of required parameters. For Amazon, there are several templates to scrape prices, reviews, ratings, etc., from different regions. You can search “Amazon” in the Template Gallery on Octoparse to find the scrapers that meet your needs. Or try the online Amazon product data scraping template below directly.
https://www.octoparse.com/template/amazon-product-details-scraper
Related Reading: How to scrape product data with Octoparse easily?
Auto-detect webpages data
However, you might have more specific needs, so you’ll need a customized crawler. In Octoparse, building a scraper is simplified into several steps. You can create a task to scrape product details, reviews, prices, etc., within clicks rather than writing scripts.
Auto-detection is the key feature to make building scrapers easier and effortless. This feature will let Octoparse scan the page and detect extractable data automatically. So users can get wanted data fields in seconds but not bother to read HTML files and local data by hand.
Related Reading: Scrape Amazon reviews without any coding skills
Schedule run and automatic data export
Amazon product data is ever-changing. Getting up-to-date information on Amazon can help you stay ahead of competitors. It contributes to competitive pricing strategies, insightful market research, in-depth sentiment analysis, etc. Octoparse offers schedule scrapers and automatic data export to help you keep an eye on competitors and the market around the clock.
With these features, you can set up an Amazon scraper in one go and schedule it to pull the latest data from webpages weekly, daily, or even hourly, and export scraped to databases or as local files automatically.
Related Reading: How to build an Amazon price tracker with web scraping tools?
Cloud servers
Octoparse is equipped with a cloud platform that can maximize scraping efficiency. Cloud servers can process scraping tasks 24/7 at a faster pace. When tasks are run in the cloud, there are no hardware limitations. During operation, you can shut down the app even their computers without missing a row.
Building Amazon scrapers with such powerful features only needs several clicks on Octoparse. You can even explore more with XPath, regular expressions, API access, IP proxies, etc., to improve the efficiency of scrapers. To have a try on all these features, download Octoparse for free and have a trial of 14 days.
Final Thoughts
Leveraging the power of Python and libraries like BeautifulSoup and Selenium can unlock valuable data from Amazon to analyze and gain actionable insights. This technique requires some coding knowledge and experience, and the HTML structure of pages can break the scraper.
If you are looking for an easier and more convenient alternative, Octoparse should be on the shortlist. It does not need coding skills and provides a beginner friendly solution for automatic web scraping.
Besides these options, you can also check the top list of Amazon scrapers to find one that can meet 100% of your needs.
Common Questions About Scraping Amazon With Python
1. What are the legal and ethical considerations when web scraping Amazon or other shopping sites?
Scraping means using computer programs to collect data from websites like Amazon.
- If information is public and you just look at things like prices or reviews, that’s usually okay.
- But if you try to get private info, break the website’s rules, or use tricks to get around protections, you could get banned or face legal problems.
Ethically, scraping should not overload websites or steal data people expect to be private. It’s best to check each site’s rules before scraping and only collect data you truly need.
If you want to learn more from about web scraping legality:
Is It Legal to Scrape Amazon?
Is Web Scraping Legal?
2. How many major web frameworks are implemented in Python versus other languages?
Python has around 10–25 major web frameworks, including Django, Flask, Pyramid, CherryPy, and FastAPI, while other languages such as JavaScript, Java, Ruby, and PHP each have 5–20 recognized major frameworks, according to recent breakdowns from industry and educational sources.
3. How do Python scraping tools compare with services like Octoparse for scale and legality?
Python scraping tools (like BeautifulSoup and Selenium) are flexible and let you control everything.
But to handle lots of data, you must set up computers or servers yourself. Octoparse uses cloud servers that can do big tasks faster and easier.
For legality, neither option is totally safe if you break a website’s terms. Commercial services sometimes have built-in protections, but users are still responsible for following the site’s rules.
4. How do Amazon’s anti-bot systems work, and what recent changes make scraping harder?
Amazon uses smart tools to find and block bots. They look for patterns like lots of requests from one computer, odd mouse movements, or repeated actions that real people don’t do.
If Amazon thinks a bot is at work, it can show a CAPTCHA puzzle, block access, or require a login. Lately, Amazon has added new ways to spot advanced bots, such as checking browser fingerprints and making bots solve tough challenges. These updates make scraping much harder unless you act like a regular user.