How much do you know about web scraping? Don’t worry, even if you are new to this concept. In this article, we will brief you on the basics of web scraping, and teach you how to assess web scraping tools to get one that best fits your needs. Last but not least, we present the 10 best free web scraping tools for Windows, Mac, and browser extensions for your reference.
What Is Web Scraping and How It Is Used
Web scraping is a way of gathering data from web pages with a scraping bot, hence the whole process is done in an automated way. The technique allows people to obtain web data at a large scale quickly. In the meantime, instruments like Regex (Regular Expression) enable data cleaning during the scraping process, which means people can get well-structured clean data one stop.
How does web scraping work
- Firstly, a web scraping bot simulates the act of human browsing the website. With the target URL entered, it sends a request to the server and gets information back in the HTML file.
- Next, with the HTML source code at hand, the bot is able to reach the node where the target data lies and parse the data as it is commanded in the scraping code.
- Lastly, (based on how the scraping bot is configured) the cluster of scraped data will be cleaned, put into a structure, and ready for download or transference to your database.
How to choose a web scraper
There are ways to get access to web data. Even though you have narrowed it down to a web scraping tool, tools that popped up in the search results with all confusing features still can make a decision hard to reach.
There are a few dimensions you may take into consideration before choosing a web scraping tool:
- Device: If you are a Mac or Linux user, you should make sure the tool supports your system, as most web scrapers work on Windows only.
- Cloud service: Cloud service is important if you want to access your data across devices anytime.
- API access and IP proxies: Web scraping faced a list of challenges and anti-scraping technologies. IP rotation and API access will help you never get blocked.
- Integration: How you would use the data later on? Integration options enable better automation of the whole process of dealing with data.
- Training: If you do not excel at programming, better make sure there are guides and support to help you throughout the data scraping journey.
- Pricing: The cost of a web scraper shall always be taken into consideration, and it varies a lot among different vendors.
10 FREE Web Scraping Tools in 2025

(Feel free to use this infographic on your site, but please provide credit and a link back to our blog URL using the embed code below.)
Now you may want to know what web scraping tools to choose from. In this part, we list 10 free web scrapers based on different platforms. Some of them are desktop-based, so you need to download and install them, but they always have more powerful functions than those based on web extensions or cloud services. The lists below are the best web scraping tools free or at a low cost and would satisfy most scraping needs with a reasonable amount of data requirement.
4 Web Scraping Tools for Windows/Mac
1. Octoparse – the best free web scraper
Octoparse is an easy-to-use web scraping tool that is designed for almost all website scraping needs. It has an AI-based auto-detecting mode so that you can handle your scraping needs without any coding skills. Also, Octoparse provides advanced functions to customize your web crawler. It’s free to use for all basic scraping needs, and several advanced features ask for pricing if you have large scraping needs.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Online Data Scraping Templates
Octoparse provides preset templates for non-coding users to turn web pages into structured data instantly. On average, it only takes about 6.5 seconds to pull down the data behind one page and allows you to download the data to Excel. Check out what websites are most popular and their easy scraping templates. What’s more, you can use these templates online without downloading the software, just visit Octoparse Scraping Templates or click the link below to have a try.
https://www.octoparse.com/template/contact-details-scraper
If you have some coding knowledge, you can find more advanced functions in Octoparse, including a cloud service for scheduled scraping, set AJAX, pagination, or cookies to handle complex website for massive data.
2. ScrapingBot
Scraping Bot is a great tool for web developers who need to scrape data from a URL, it works particularly well on product pages where it collects all you need to know (image, product title, product price, product description, stock, delivery costs, etc.). It is a great tool for those who need to collect commerce data or simply aggregate product data and keep it accurate.
ScrapingBot also offers several APIs specializing in various fields such as real estate, Google search results, or data collection on social networks. It is free to test out with 100 credits every month. Then the first package at 39€, 99€, 299€ then 699€ per month. You can test live by pasting a URL and getting the results straight away to see if it works.
3. ParseHub
Parsehub is a web scraper that collects data from websites using AJAX technologies, JavaScript, cookies, etc. It supports Windows, Mac OS X, and Linux system. Parsehub leverages machine learning technology which is able to read, analyze and transform web documents into relevant data. It is not fully free, but you still can set up to five scraping tasks for free. The paid subscription plan allows you to set up at least 20 private projects.
4. Import.io
Import.io is a SaaS web data integration software. It provides a visual environment for end-users to design and customize the workflows for harvesting data. It covers the entire web extraction lifecycle from data extraction to analysis within one platform. And you can easily integrate into other systems as well.
Top 4 Web Scraping Plugins and Extensions
5. Data Scraper (Chrome)
Data Scraper can scrape data from tables and listing-type data from a single web page. Its free plan should satisfy most simple scraping with a light amount of data. The paid plan has more features such as API and many anonymous IP proxies. You can fetch a large volume of data in real-time faster. You can scrape up to 500 pages per month, you need to upgrade to a paid plan.
6. Webscraper.io
Web Scraper has a Chrome extension and a cloud extension. For the Chrome extension version, you can create a sitemap (plan) on how a website should be navigated and what data should be scrapped. The cloud extension is can scrape a large volume of data and run multiple scraping tasks concurrently. You can export the data in CSV, or store the data in Couch DB.
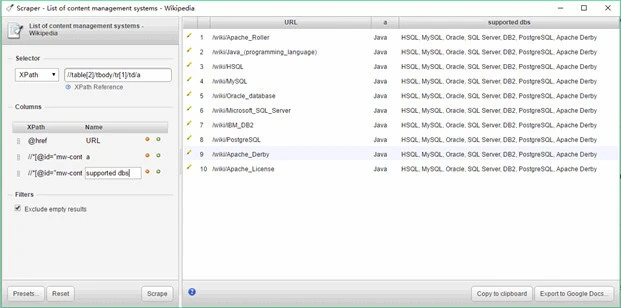
7. Scraper (Chrome)
The scraper is another easy-to-use screen web scraper that can easily extract data from an online table, and upload the result to Google Docs. Just select some text in a table or a list, right-click on the selected text, and choose “Scrape Similar” from the browser menu. Then you will get the data and extract other content by adding new columns using XPath or JQuery. This tool is intended for intermediate to advanced users who know how to write XPath.
8. Outwit hub (Firefox)
Outwit hub is a Firefox extension, and it can be easily downloaded from the Firefox add-ons store. Once installed and activated, you can scrape the content from websites instantly. It has outstanding “Fast Scrape” features, which quickly scrapes data from a list of URLs that you feed in. Extracting data from sites using Outwit hub doesn’t demand programming skills. The scraping process is fairly easy to pick up. Users can refer to their guides to get started with web scraping using the tool.
2 Web-based Scraping Applications
9. Dexi.io
Dexi.io (also known as Cloud scrape) is intended for advanced users who have proficient programming skills. It has three types of robots for you to create a scraping task – Extractor, Crawler, and Pipes. It provides various tools that allow you to extract the data more precisely. With its modern feature, you will be able to address the details on any website. With no programming skills, you may need to take a while to get used to it before creating a web-scraping robot. Check out their homepage to learn more about the knowledge base.
The freeware provides anonymous web proxy servers for web scraping. Extracted data will be hosted on Dexi.io’s servers for two weeks before being archived, or you can directly export the extracted data to JSON or CSV files. It offers paid services to meet your needs for getting real-time data.
10. Webz.io
Webhose.io enables you to get real-time data by scraping online sources from all over the world into various, clean formats. You even can scrape information on the dark web. This web scraper allows you to scrape data in many languages using multiple filters and export scraped data in XML, JSON, and RSS formats. The freeware offers a free subscription plan for you to make 1000 HTTP requests per month and paid subscription plans to make more HTTP requests per month to suit your web scraping needs.
Final Words
After learning about the top 10 free web scrapers for different systems and their main features, you can choose the most suitable one according to your needs. Octoparse will always be the best choice if you want to get any data from any website without coding, especially its data scraping templates can help you save more time and energy.




