You don’t need coding or paid software to grab every image from a website.
I have tested three free image extractors that let you:
- Extract all images from any webpage in one click.
- Preview and filter by size, format (JPG, PNG, WebP), or type (standard / CSS).
- Download images in bulk directly to your device.
- Work on any browser or OS — no installation required for online tools.
However, you would find it a little difficult to extract the images alone from the website as there are many other media on the website. Therefore I will also show you the advanced methods, not just download image from urls but also from dynamic pages, and extract images from PDFs, WordPress sites, and social media pages.
3 Free Images Extraction Tools Online
1. Image Extraction Tool
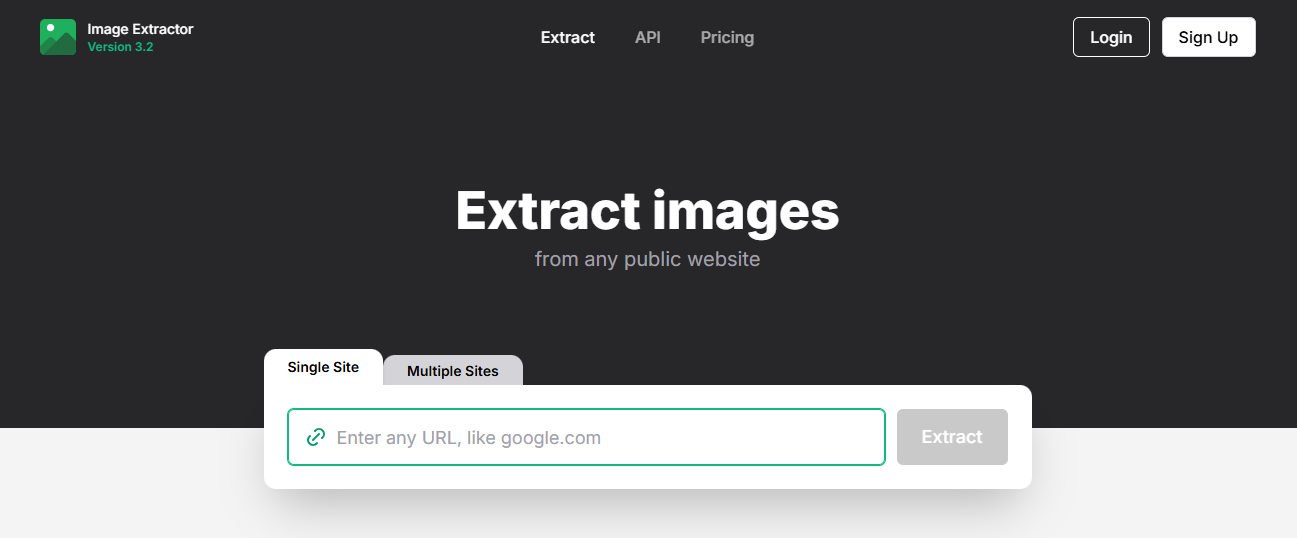
Image Extraction Tool is a free, browser-based tool that instantly scans any webpage and lists all the image files it contains.
How to Use
Just paste your URL(s) into the “Single Site” or “Multiple Sites” tab, click “Extract,” and you’ll get a full preview gallery of found images, each shown with the original size and format.
No signup, no software install, and you can download them all at once as a ZIP. Perfect for anyone who needs to grab full-quality visuals quickly from the web without the usual right-click hassle.
2. Download All Images
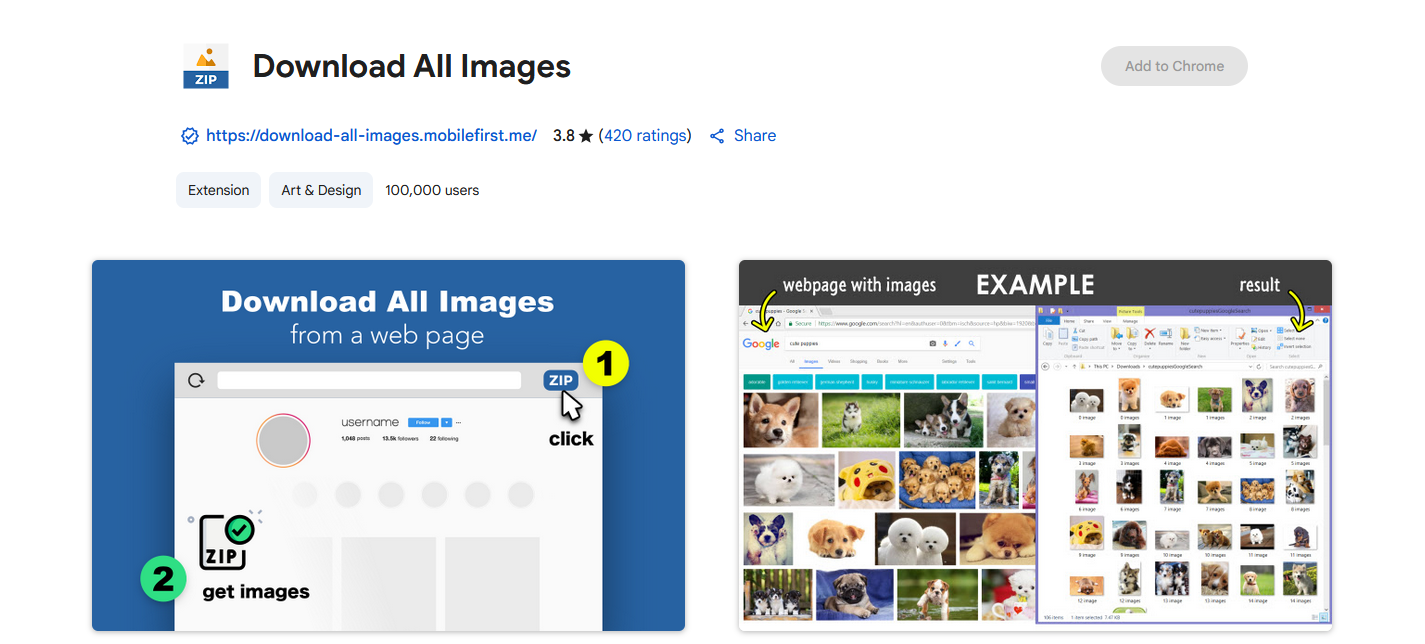
If you just need something quick and simple, Download All Images works well. It’s a browser extension that does exactly what its name says.
How to Use
After installation, open a page and click the icon. All available images appear in a list within seconds. You can preview them first and see the file sizes before downloading. That helps if you only want the high-resolution ones.
Pros & Cons
It runs smoothly on most regular websites and feels very lightweight. It works in Chrome and Edge and supports common formats like JPG, PNG, and WebP. For saving pictures from blogs, portfolios, or research pages, it’s fast, reliable, and requires no sign-up or setup. But Dynamic pages such as e-commerce sites may not always show every image.
It’s a great pick if you want a quick browser-based solution without installing extra software.
3. OWIDIG
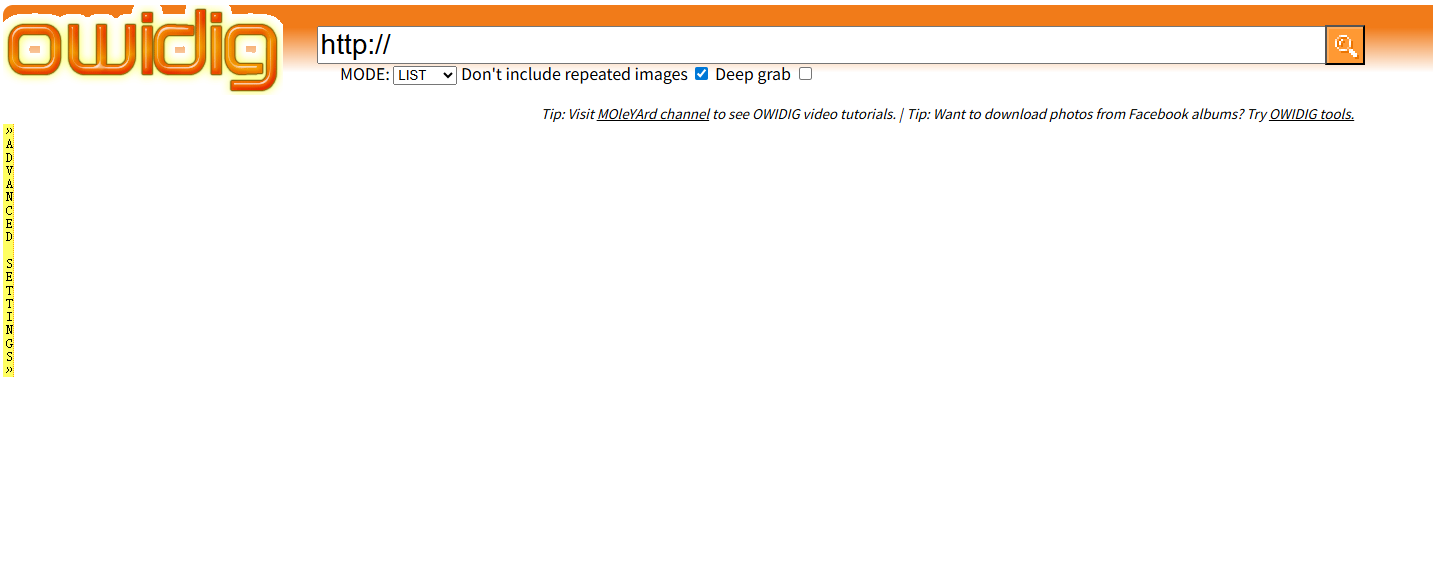
If you want a web-based option without installing an extension, OWIDIG is worth trying. It’s an online image extractor that automatically collects all images from a target URL and lets you filter or download them directly from the browser.
How to Use
- Enter a webpage URL into the OWIDIG site and start the extraction.
- The tool quickly lists all detected images with basic details like size, type, and filename.
- You can filter them by dimensions, format, or URL, and decide whether to include both standard and CSS images.
- Once you’ve reviewed the results, you can download selected images or share them directly to social platforms.
Pros & Cons
OWIDIG is accessible on any device with a browser and works with both HTTP and HTTPS sites. The filtering options are detailed and help you narrow results when a page contains many visuals.
However, it may take longer to process pages with a large number of images, and preview quality can be inconsistent. For users who want flexible filtering without installing anything, it’s a practical and easy-to-use choice.
Comparison
Compared with Download All Images, OWIDIG feels slower but more flexible. It’s better if you need to filter images precisely or work from different devices.
However, it lacks the one-click speed and convenience of browser extensions. If you often grab images from many pages in one session, the extension still feels smoother. If you only need to extract from a few URLs and prefer not to install anything, OWIDIG is the simpler way to go.
How to Extract Images from PDFs, WordPress Sites, and Social Media Pages
Sometimes you don’t just want images from regular webpages. PDFs, WordPress sites, and social media pages each store images differently, and that’s where most free browser tools start to struggle. Here’s what actually works in each case.
1. Extracting Images from PDFs
If you only need a few pictures from a PDF, upload the file to iLovePDF. It can pull out every embedded image in seconds, no setup needed.
For higher-resolution results or large PDFs, try PDF24 Creator on desktop. It keeps the original image quality, which most online tools compress.
If you deal with PDFs regularly (for example, product catalogs or reports published online), you can use Octoparse to scrape all the PDF links from a site, download them automatically, and then extract the images in bulk. This saves huge amounts of time when you have dozens or hundreds of documents to process.
2. Extracting Images from WordPress Sites
Most WordPress sites store images under /wp-content/uploads/. If you add that path after the site’s domain, you can often browse and download the images directly.
When that doesn’t work or when you want images from specific posts only, tools I mentioned above like Download All Images or OWIDIG still do a decent job.
If you need a more rounded database, Octoparse lets you build a simple task to crawl all post URLs, open each one, and download the featured and in-content images automatically. You can even include the post title or category next to each image in your export file.
3. Extracting Images from Social Media Pages
This is where browser extensions usually fail. Platforms like Instagram, Twitter/X, or Reddit load content dynamically, which means images appear only as you scroll.
If you only need a few images, you can use simpler tools like 4K Stogram for Instagram or Download All Images for public pages, but Octoparse is more reliable for ongoing or large-scale collection for downloading images from dynamic pages.
Check out our blogs on how to scrape Reddit images without coding.
In Short

- Use online extractors for one-off PDFs.
- Use browser tools for small WordPress pages.
- Use Octoparse for anything dynamic, repetitive, or large-scale — especially social media and forums.
Best Image Scraper to Extract Pictures No Limits
If you’ve tried tools like Download All Images or OWIDIG, you already know they work well for simple one-off tasks. But when you need to collect images regularly, or from multiple sources such as social media or forums, those extensions quickly hit their limits
Octoparse goes beyond browser-based image extractors. It can help you extract images from web without any limits, and it’s a full web-scraping platform that lets you schedule, automate, and scale data collection from virtually any site. As a web scraper, Octoparse is easy-to-use and don’t ask for any coding skills, available for both macOS and Windows systems.
You can easily bulk extract information including images from websites, no matter you’re experienced or inexperienced. Just by clicking, you can get webpage images download to your local devices within several minutes.
3 Steps to Extract Images From Webpage
You can build a web crawler from scratch with the “Custom Task” in Octoparse to scrape data, or use the auto-detecting mode to create a workflow within two simple clicks.
Step 1: Paste the Image Webpage Link
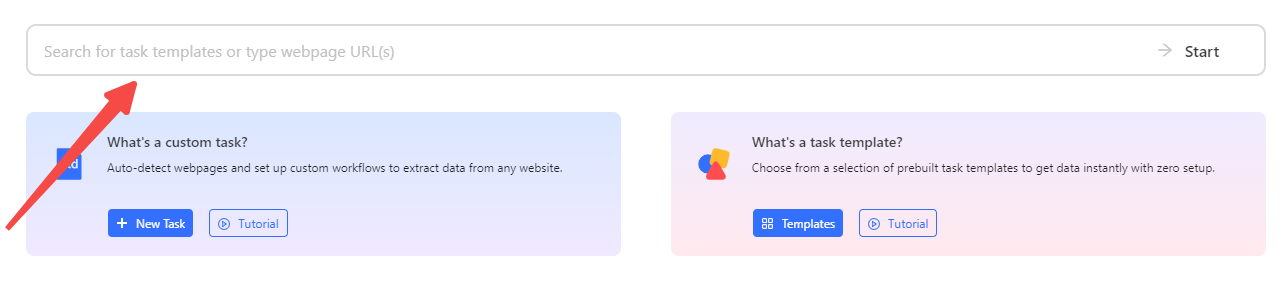
Go to the target page you want to extract images from, copy and paste the URL into Octoparse main panel after you have download and install it on your devices. The auto-detecting mode will be started and create a workflow to continue.
Step 2: Modify the image data fields
Check the data preview to see if all the images you want are included or any unnecessary data field you would like to delete.
Click on the images you need to extract, and choose the option “Extract image URLs and download linked files” on the Tips panel to add it to the extraction process.
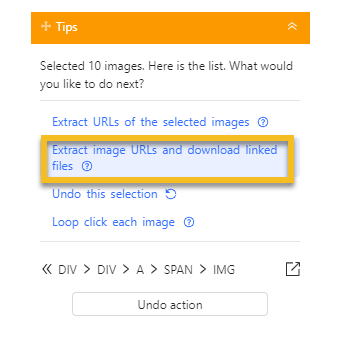
Step 3: Run the image crawler
After all changes have been checked, run the task, and you can download the images within a few minutes. If you have regular needs, you can also try the Cloud mode to set a schedule task.
You can change the download settings, and learn more details by reading the tutorial about download files and images with Octoparse.
On the other hand, Octoparse provides hundreds of ready-to-use web scraping task templates, which allow you to scrape data from popular websites directly without task configuration.
It is excellent for the beginner who has no idea about creating a crawler to scrape the data they want. All you need to do is choose a template that can help to get the target data and enter some information. The scraper will scrape the data for you. With these pre-built templates, you can extract data directly from other big sites, such as Google Maps, Google Search and more within clicks. Below are some examples:
- E-commerce & Retail platforms: Amazon, eBay, etc.
- Directories: Yellowpages, Google Maps, Crunchbase, etc.
- Online travel agency sites: Booking, TripAdvisor, Airbnb, etc.
- And more: Real estate listings, social media channels
Conclusion
Alright, hope this article is helpful to you if you want to bulk download images. You can learn more tools to scrape and download images from a list of URLs.
Welcome to try out Octoparse if you are interested and have web scraping needs. Feel free to contact us if you have any questions or provide feedback through support@octoparse.com.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
FAQs: Common Questions About Image Extraction
1. Is it legal to download images from websites?
Downloading images for personal or educational use is usually fine, but re-using them commercially can infringe copyright. Always check the site’s usage terms or look for royalty-free licenses before sharing or publishing extracted images.
2. How do I organize or rename the downloaded images?
Browser tools usually save images with random filenames. You can use bulk-rename utilities like Advanced Renamer or handle sorting automatically inside Octoparse, which can export image names, URLs, and categories in one Excel or CSV file.
3. What if the tool doesn’t capture every image?
Some pages load images dynamically as you scroll. In that case, try Octoparse’s auto-scroll and dynamic rendering options to ensure everything loads before extraction.
4. Can I export images with metadata (titles, captions, alt text)?
Yes. In Octoparse, you can extract accompanying text fields like captions, alt attributes, or post titles along with the image URLs.
5. What’s the best option for my use case?
- For quick one-time downloads: Download All Images or OWIDIG.
- For batch downloads or automation: Octoparse Cloud Mode.
- For PDF or WordPress image libraries: Octoparse with link extraction setup.
- For social media or forums: Octoparse (dynamic scrolling + login supported).