It can be time-consuming to find, copy, and paste various images from Reddit. But have you ever thought about building a Reddit image scraper using Octoparse, the powerful web scraping tool? Let’s find out how to do it.
What Is a Reddit Image Scraper and How Does It Work?
This article will introduce particularly how to build a Reddit image scraper, but let’s start with what a Reddit image is.
A Reddit Image Scraper is a tool or script that automatically downloads image files from Reddit — whether from posts, Subreddits, or user profiles — and saves them to your computer or cloud storage. It works by detecting image URLs within Reddit content, fetching the images, and organizing them for convenient access or analysis.
How a Reddit Image Scraper Works
- Source selection: The scraper targets specific Reddit areas such as Subreddits, post threads, or search results, depending on your scope (e.g., r/pics, a particular Subreddit, or keyword-based searches).
- URL extraction: It analyzes the page or uses Reddit’s API to collect direct image links (JPEG, PNG, GIF, or other supported formats).
- Filtering and deduplication: Many scrapers let you filter images by file size, format, or domain, and skip duplicates or broken links, which can help conserve storage and maintain data quality.
- Downloading and storage: Images are saved to local or cloud storage, often organized by Subreddit or date. Some tools also log download progress and errors for record-keeping.
- Responsible usage: Ethical scrapers respect Reddit’s terms of service, rate limits, and robots.txt rules, avoiding excessive server requests. They often include built-in delays or options to pause or limit scraping activity.
What’s the Common Approaches and Tools Used to Scrape Reddit
- API-based scrapers: These use Reddit’s official API (via OAuth) to retrieve posts and extract image URLs. This method is more stable and compliant but requires API credentials and adherence to rate limits.
- Web-scraping solutions: Browser-based or headless-browser tools crawl Subreddit pages and parse the HTML (DOM) to find image links. This approach is useful when API access is restricted or certain content isn’t available through the API.
- No-code/low-code tools: Visual tools with pre-built Reddit scraping workflows allow image extraction without coding. They simplify setup but may come with usage limits.
- Cross-host handling: Since Reddit posts may include images hosted both on Reddit and on third-party platforms (like Imgur), good scrapers handle both sources and correctly resolve redirects to the actual image files.
Any Ethical and Legal Considerations Involved When Scraping Reddit
- Respect privacy and copyright: Many Reddit images belong to their creators. Always obtain permission before downloading or reusing images, especially for commercial purposes.
- Comply with Reddit’s terms: Review Reddit’s API documentation and user-content policies to ensure your scraping activities stay within permitted use.
The steps to make an Reddit Image Scraper basically include:
- Scraping Image URLs from any particular website and storing them in an Excel file
- Using the URLs to download images with some Chrome plugins
How to build an Image Scraper?
There are several ways to build a Reddit Image Scraper. If you have a technical background and are familiar with programming languages, you can create one by writing your own code.
But even if you’re not into coding, don’t worry — there are user-friendly software options like Octoparse that let you build a custom Reddit Image Scraper without any programming. Y
ou can even get started instantly using prebuilt templates in Octoparse, which automate most of the setup for you. I’ll explain the two no-code approach to scrape Reddit Images.
Use Web Scraping Tool to Scrape Reddit Images (Without Coding)
And if you are someone who doesn’t belong to any technical background, there are plenty of Scraping Software out there that will eventually help you with image scraping in minutes.
So, Let me introduce to you one here which has an easy-to-use and easy-to-understand interface. i.e., Octoparse.
Octoparse is a scraping software that offers a free plan including up to 10 tasks, 10,000 rows per export, and 50,000 rows per month for local runs.
In addition to the free services, the Octoparse community offers a large number of tutorials and articles for real-world scraping scenarios like scraping Reddit posts.
To build a successful Image Scraper, you will also need to add a Chrome extension that allows instant image downloads from a list of URLs. For this tutorial, I am using the “Tab Save” Chrome plugin. You can watch the video below on bulk downloading images first.
Step-by-step Guide to Build a Reddit Image Scraper with Octoparse
Let us take an example of making a Reddit Image scraper using Octoparse.
For this tutorial, We are scraping images from this Webpage of Reddit. Let’s get started with these simple steps:
- Download Octoparse and sign up.
- Create New Task: Copy the link to the website where you want to scrape images. On the very left corner of the homepage, click on the “+New” button and choose the “Advanced Mode” option from the drop-down as shown below.
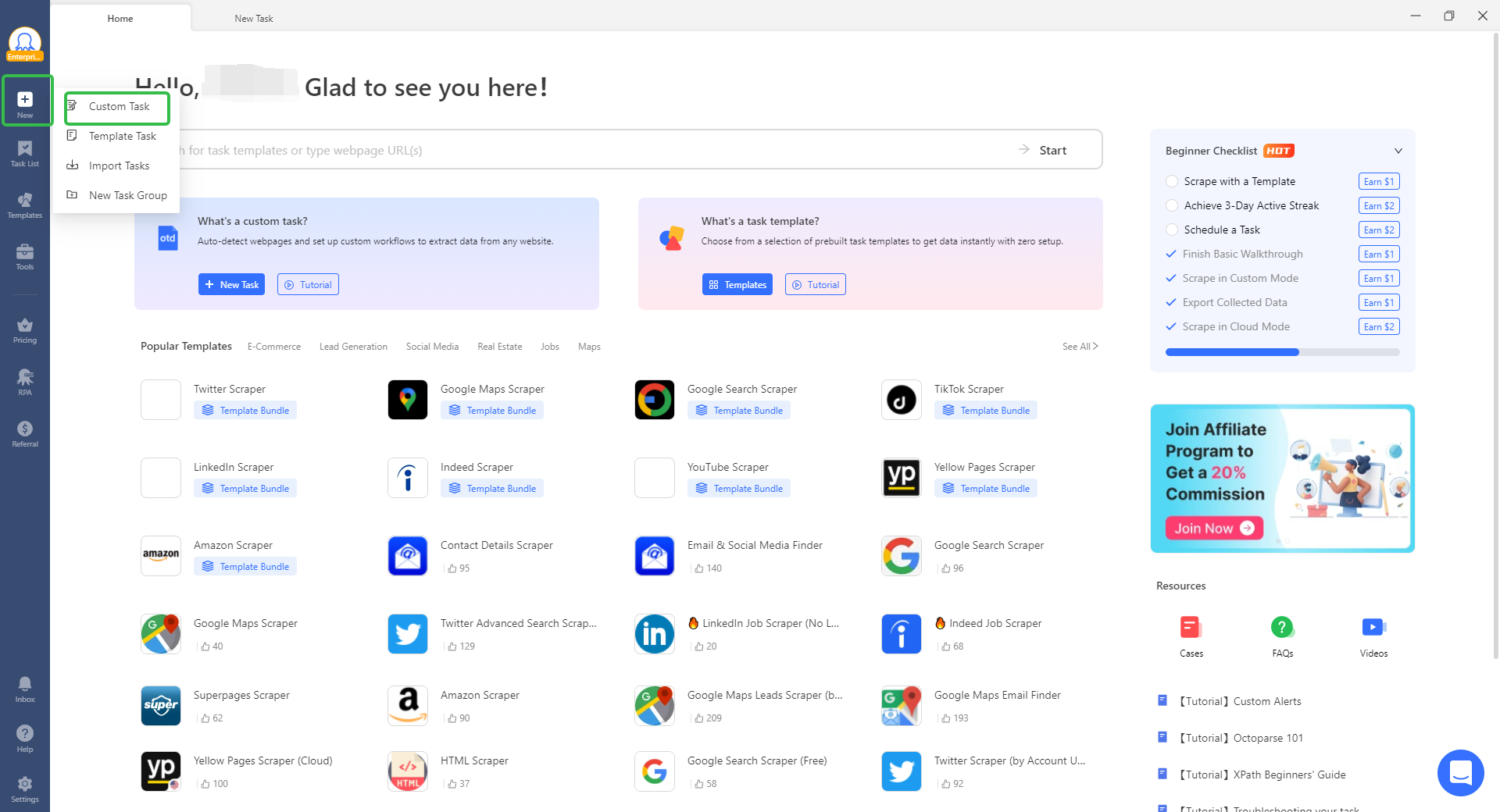
- Paste URL & Save: After that, you will see another interface showing space for the URL. Just paste the copied URL in the specified space like below and click on “Save” to move ahead.
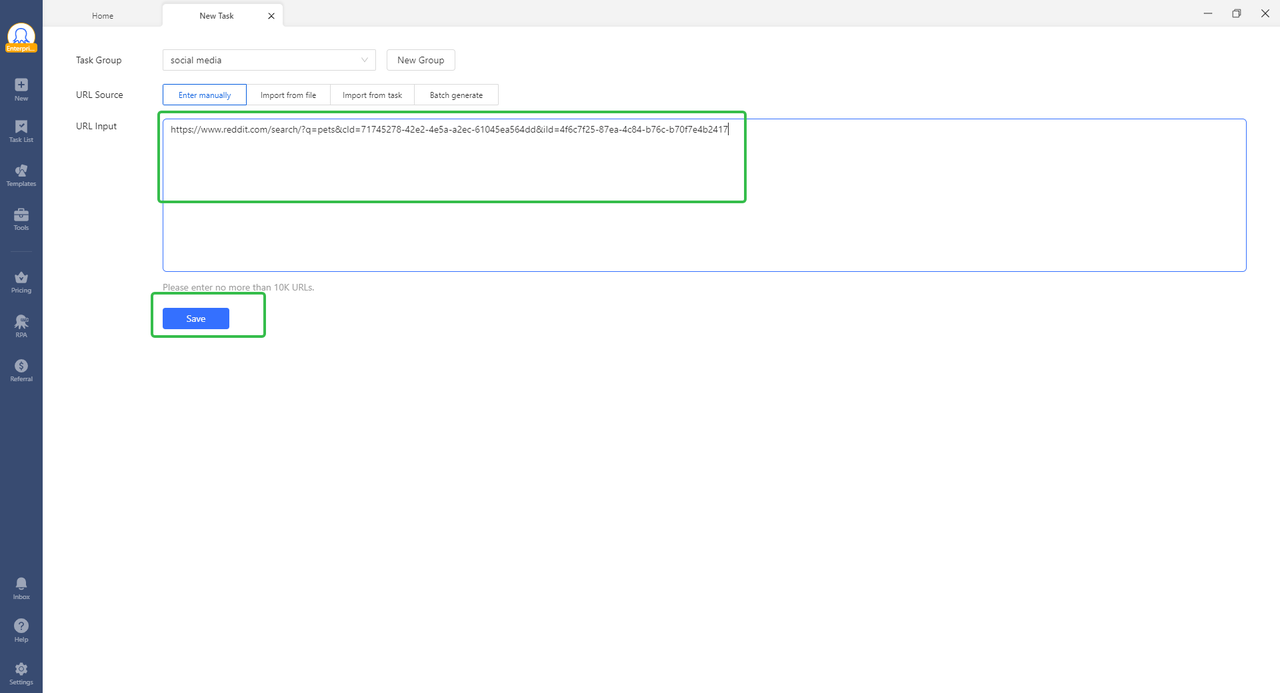
- Log in to Your Reddit Account: Clicking on the “Save” button will take you to the next interface which will look like the image below divided into three sections. Other than the “Workflow” and “Data preview” sections, the upper right contains the interface of the website that you want to scrape. You can even manually select elements and browse here as well as you do on the browser by switching the “Browse” toggle in the upper right corner. When the “Browse” mode is on, you can log in to your Reddit account in light of the page instructions.
- Try Auto-detection: Then you’ll see there are two steps listed on the “Tips” panel as well: Set up Auto Login, Auto-detect Webpage Data. Here we recommend you to try the latter. Then you’ll find all is done without any manual setup as it can create a workflow on its own.
If you want to select elements from a webpage selectively manually, you can manually create workflows by clicking the element you want to scrape. I am hereby illustrating steps on “Edit task workflow manually”.
- Select All Images: The “Tips” panel will pop up on clicking the very first image. Then choose the “Select all” option to select all the images listed on the web page.
- Extract Image URLs: Now look at the image below, you must be seeing some pretty differences. Just after selecting all the images, it listed all the links for images in the “Data preview” Section. The “Tips” panel has listed some options to choose from. In order to extract image URLs, select the first option i.e., “Extract image URLs”.
- Verify Links: To see which image link has been scraped, click on that link in the “Data Preview” Section. You will get to see some highlights on the browsing interface.
- Configure Scrolling Settings: If only a few images load, double-click the “Go to Web Page” step in the Workflow, enable scroll-down or load-more (set repeats & wait time) to load more images.
- Set Loop & Extract Options: Update the “Loop Item” in the Workflow; ensure “Extract data in the loop” is selected under the “Extract Data” settings.
- Save & Run the Task: Use the “Save” and “Run” buttons at top of the Workflow panel once settings are ready. If you are using a free plan, run the task on your device. Cloud services are only available for other plans. It will scrape the list of image links for you in just minutes. It scrapes 51 links in just 1 min 12 seconds. Isn’t it pretty cool!!
- Export the Data: Click “Export Data” and choose your format (CSV, Excel, JSON) to save the scraped URLs. This is how scraped URLs will look in a structured format.
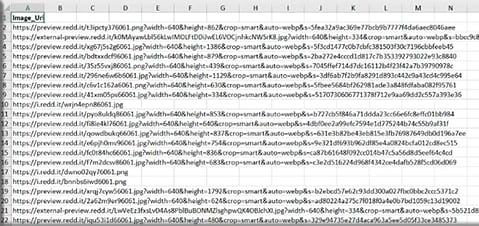
- Download Images via Extension: The next step is to download the images, since you have all the links in one place, simply copy-paste the links to the Tab Save Chrome extension. Start downloading the files by clicking the download icon at the bottom.
Just following these steps, you can build your own Reddit Image Scraper in just a few minutes. So, what are you waiting for? Go and Scrape. Take use of this software and this tutorial as much as you can.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Try Reddit Scraper Template for Images for Fast & Effortless Data Collection
If you want to skip the manual setup and get straight to data collection, you can use Octoparse’s Reddit Post Comments Scraper Template to extract Reddit image links, post titles, post URLs and more by inputing Reddit URLs.
What you can collect:
- Images: direct image URLs from Reddit posts or embedded media.
- Post content: titles, post URLs, and timestamps for context.
- Engagement data: upvotes, comment counts, and author info.
- Comments: detailed comment threads for sentiment or community analysis.
How you can use the data:
- Content inspiration: Gather popular memes, visuals, or designs to inspire your own social media or creative projects.
- Market research: Identify trending topics, products, or visuals that gain the most attention.
- Community insights: Analyze user engagement or sentiment to understand how Reddit audiences react to visual content.
- Dataset creation: Build training datasets for AI image recognition, natural-language analysis, or machine-learning experiments.
Simply open the template, enter your target Subreddit or Reddit URL, and hit Run. Octoparse will automatically fetch all the structured data — including the images — without any coding or setup effort. Once the data is ready, export it in your preferred format (Excel, CSV, JSON, etc.) and use it however you need.
Try it below for fast Reddit image scraping!
https://www.octoparse.com/template/reddit-post-comments-scraper
Conclusion
Reddit Image Scrapers offer a convenient way to collect large volumes of images for research, archiving, or creative projects.There are API-based, browser-based, or no-code tools. Just choose the right approach depends on your technical comfort and project goals. Just remember to use these tools responsibly — follow Reddit’s rules, respect copyright, and ensure your scraping practices remain ethical and compliant.
FAQs about Reddit Image Scrapers
- Which Subreddit image scraper works best?
There’s no one “best” scraper for all cases — but here are strong options:
Top recommendations:
- Octoparse – No-code visual scraper supporting Reddit workflows, image URL extraction, and full export.
- Chat4Data – AI-powered scraper with natural-language interface for fast image scraping from Reddit without setup.
- Outscraper – Cloud-based, supports Reddit sub-reddit scraping including image extensions and bulk export.
- Axiom – Browser-bot/Chrome-extension tool for no-code Reddit scraping; good for simple image capture tasks.
How to pick:
- Want fast setup with minimal coding? → Octoparse or Chat4Data.
- Need heavy volume or external hosts + metadata? → Outscraper.
- Prefer browser extension approach? → Axiom.
Key checks:
image URL support, pagination/infinite scroll handling, export formats, cost model & maintainability.
- How to download Reddit images with Python? No universal “best” script—choose based on your trade-offs. Here are some factors you can consider:
- API vs Web-scraping
- API: Clean, structured, usually more compliant. Requires credentials, may have limitations.
- Web-scraping: More flexibility (can scrape content API may miss), but more brittle and may raise legal/terms risks.
- Media handling
- Ensure your script handles Reddit’s media formats and external hosts (galleries, Imgur, etc).
- Storage & metadata
- Organise downloads by Subreddit/date/post, log metadata (post id, author, timestamp), use a manifest to avoid duplicates.
- Robustness & maintainability
- Include retry logic, error-handling, and deduplication to avoid re-downloading the same image. Basic workflow includes:
A. Register a Reddit app (if using API) – get client ID/secret.
B. Fetch posts (via API or web-scrape), filter for image posts, extract image URLs.
C. Download images to local folders, name them consistently.
D. Maintain a log of downloaded items to skip duplicates.
E. Extend with parallel downloads, config file, metadata export if needed.
- Can I automate Reddit image scraping legally?
Yes—but only if you obey Reddit’s terms and applicable laws. Automation itself isn’t banned; how you do it matters. Key legal & compliance factors:
- Read and follow Reddit, Inc.’s User Agreement and Data API Terms: e.g., you may not “[a]ccess, search, or collect data from the Services by any means (automated or otherwise) except as permitted” in the Terms.
- Copyright & image ownership: Images posted by users often have copyright; download/use must respect rights.
- Privacy & deletion rights: If a user deletes content, using it may violate rights or Reddit policy.
- Usage scope & commercial use: If you use API for research, commercial applications, or large-scale training, Reddit may require a specific agreement.
Best practices:
- Prefer official Reddit API when possible.
- Add request delays, avoid over-loading servers, respect robots.txt where applicable.
- Provide attribution if required, and maintain transparency of data source.
- Keep records of permissions, data usage, logs in case of future issues.
- How to handle pagination when scraping Reddit images?
Pagination ensures you don’t miss content beyond the first page—critical for thorough scraping. There are some approaches for efficient pagination:
- API pagination: Use Reddit’s JSON endpoints; each response returns an “after” token you use to request the next batch. Loop until “after” is null or you hit your target.
- Web-scraping pagination: If the UI uses “load more” buttons or infinite scroll: simulate scrolls or clicks in your scraper, extract items per page, then move on.
Implementation notes:
- In API flow: set a limit (e.g., 100 posts), send request, extract image URLs, read “after” token, repeat.
- In web flow: after each scroll/page load, extract new items, then trigger next load; loop until no new items appear or max pages reached.
Tips for reliability:
- Use a delay between page loads to avoid blocks.
- Maintain a list of already-scraped image IDs or URLs to avoid duplicates.
- Define a termination condition: e.g., “after” is null, or you’ve scraped N images/pages.
- Store metadata (post id, page number) alongside URLs so you can trace source if needed.




