Developers
One npm install. Run web scraping locally with a bundled engine — your scraped rows never leave the machine.
The web scraping engine your team can run from a laptop, a CI pipeline, or inside the AI agent you're shipping next quarter — same binary, same contract.
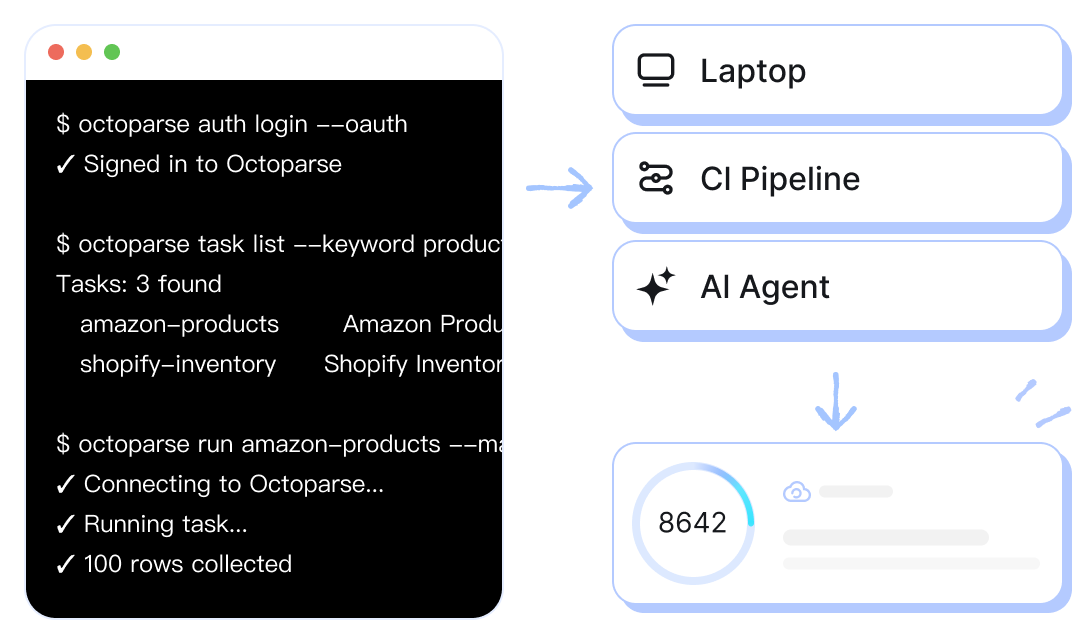
Same CLI. Same exit codes. Same JSON contract — whether it's running on a laptop, in CI, or inside an agent loop
One npm install. Run web scraping locally with a bundled engine — your scraped rows never leave the machine.
Drop the CLI into GitHub Actions, Docker, Airflow, or cron. Stable exit codes, env-var auth that never touches disk — passes security review on the first round.
Hand the CLI to Claude, Cursor, or your own agent loop. JSONL streaming lets the agent plan the next step before the run finishes.
Same binary on your laptop, your CI pipeline, or inside an agent — predictable enough to put on the on-call rotation.
A growth analyst pulls competitor pricing every morning into a Jupyter notebook. One run + one data export — fresh sheet before coffee, no Selenium to babysit.
$ octoparse run lp-pricing
✓ 248 rows → pricing.csv
A retail data team runs scheduled extractions in CI every Monday 06:00 UTC. Stable exit codes route success downstream, failures straight to on-call — zero containers to maintain.
# .github/workflows/pull.yml
- run: octoparse run $TASK --json
- run: dbt build
A vertical-AI startup exposes the CLI inside Claude / Cursor as a structured tool. JSONL streaming gives the agent row-by-row feedback so it can plan the next step before the run finishes.
tool: octoparse.run
stream: jsonl
next_action: enrich rows
Six reasons our customers pick Octoparse and stay.
200+ ready-to-run templates — Amazon, LinkedIn, Google Maps, YouTube, Yelp, HN, Reddit, and more. One REST shape, the same canonical fields, no XPath or selector maintenance.
Browser pool, proxy rotation, anti-bot, pagination, structured export — battle-tested since 2018.
Your runs, your bytes. We don't resell, redistribute, or train on the data we extract for you. Set a retention window, hit delete, gone. Every run gets a trace_id you can audit or replay.
JSON, JSONL, CSV, XLSX, XML — same canonical shape. Stream straight into Snowflake via Airbyte, dbt, Airflow, or your own ETL.
Plays native with Claude, GPT, Cursor, Cline, Dify, LangChain. JSONL streaming means your agent can plan the next step before the run finishes.
Free trial — no credit card. Transparent metered pricing after. Teams report replacing in-house scraping stacks at 1/18 the cost of headcount.
Built on eight years of scraping infrastructure — and on feedback from teams already running it in production.
"We went from a Selenium fleet on three EC2 boxes to one CLI invocation in a GitHub Action."
"Our agent loop calls it as a tool. JSONL streaming means it can plan the next step before the run finishes. Game-changer for product UX."
"Stable exit codes, env-var auth — passed our security review on the first round. That almost never happens with scraping tools."
Powering data & AI teams at
Retire the scraper. Keep the data
Free trial. No credit card. Most teams have it running in CI before the daily standup.