List crawling is the single most common web data extraction task; 70%+ of web data extraction tasks involve lists. Pricing, competitor monitoring, lead generation — they all follow repeatable patterns that can be crawled systematically..
The fastest way to succeed is to identify listcrawl-friendly sites, apply one set of extraction rules across every item, and design around pagination, rate limits, and anti-bot defenses from the start. This guide shows you exactly how.
List Crawling VS General Web Crawling
List crawling is focused and structured. Instead of visiting every page, you target a specific set of pages that share the same layout — for example, a product category, job board, or review list — and extract the same fields from each item (title, price, description, etc.).
General web crawling, on the other hand, is about visiting as many pages as possible and indexing their content — like how Google crawls the internet to build search results. It’s broad, shallow, and designed to discover pages.
Think of it this way:
General crawling = “Find me everything.”
List crawling = “Collect this exact type of data from every item in this list.”
List crawling also usually involves handling pagination, infinite scroll, and repeated patterns, whereas general crawling just follows links without worrying about data structure.
What Types of Websites Are Best Suited for List Crawling?
After crawling thousands of sites, I’ve found certain characteristics predict success consistently.
TL;DR: Where Listings Show Up Most
| Category | Examples | Why They Matter |
|---|---|---|
| Social Media | Instagram profiles, LinkedIn employee directories, Twitter hashtags | Competitor research, influencer marketing, talent mapping |
| E-commerce | Amazon product variations, eBay completed listings | Pricing intelligence, market research |
| Professional Data | AngelList funding rounds, GitHub repos | Investment research, recruiting |
| Local/Maps | Google Business listings | Local SEO audits, competitor monitoring |
1. E-commerce and Product Catalogs
When I visit sites like manufacturer product pages or marketplace listings, I look for
- Consistent data fields across items.
- Price, title, description, and images appear in the same locations with minimal variation.
- Clear pagination patterns and predictable URL structures make systematic extraction straightforward.
Amazon product pages represent the gold standard for list crawling.
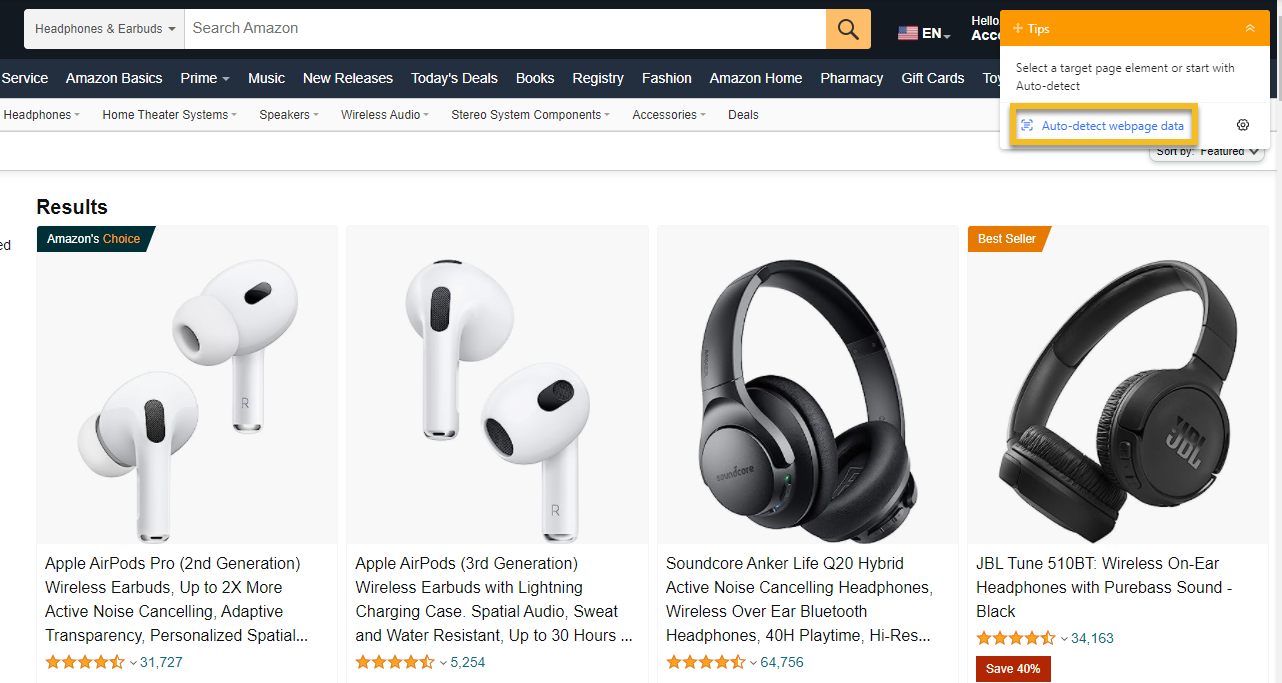
Every product listing follows the same template, pagination works predictably, and the data structure remains consistent even when visual designs change.
2. Business Directories and Service Listings
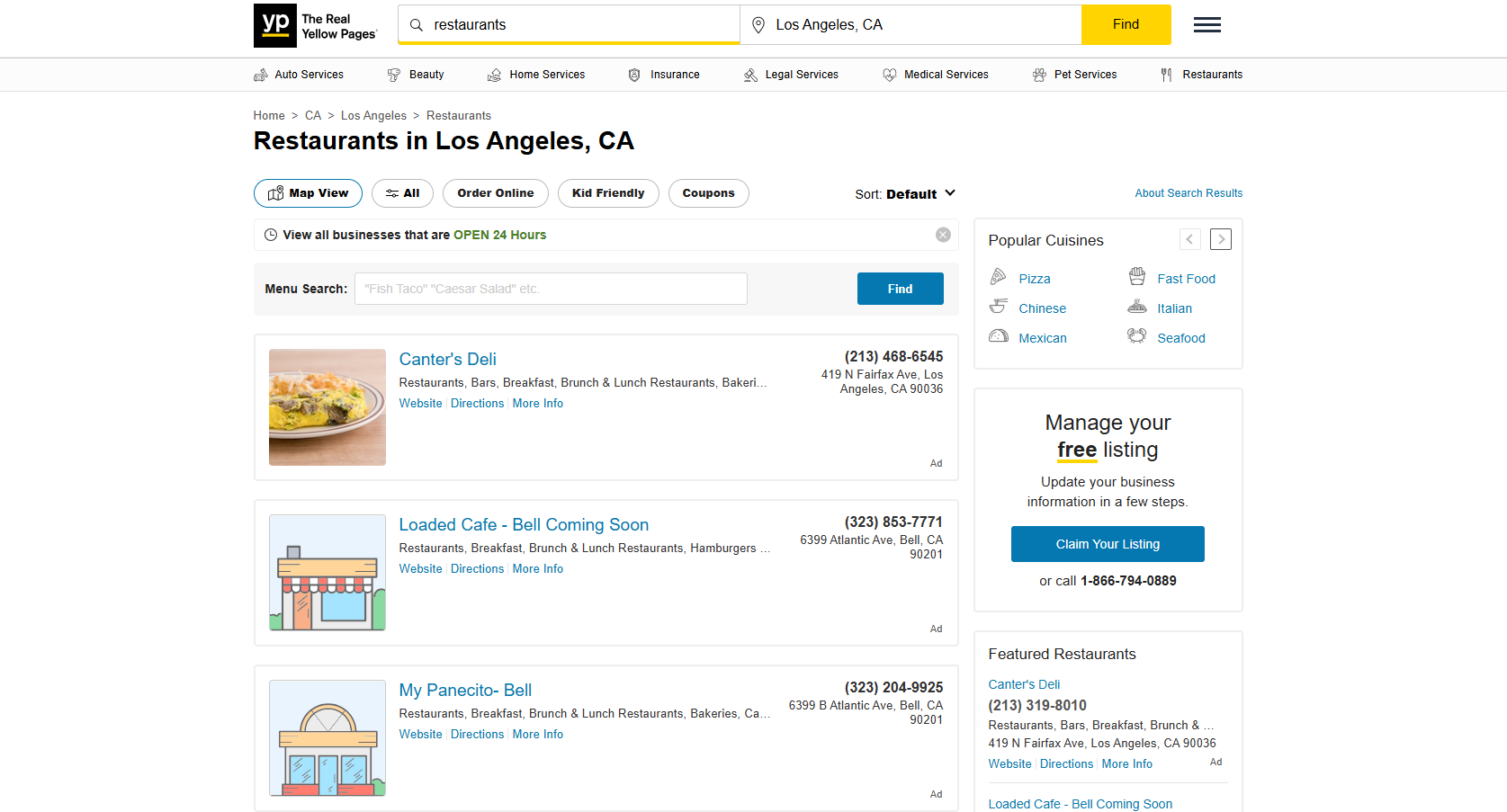
Listing sites like Yelp, Yellowpage.com, or industry directories organize company information in a standardized and easy-to-browse format. Each listing typically includes consistent fields like contact details, hours of operation, and review data.
When I analyze these directory sites, I check that business listings include the same information fields and that the organization remains logical. Other than that, geographic filtering and category browsing should work predictably across the entire site.
3. Job Boards and Career Sites
Job posting sites use standardized formats that make extraction reliable. Salary information, location data, company details, and posting dates appear consistently across listings.
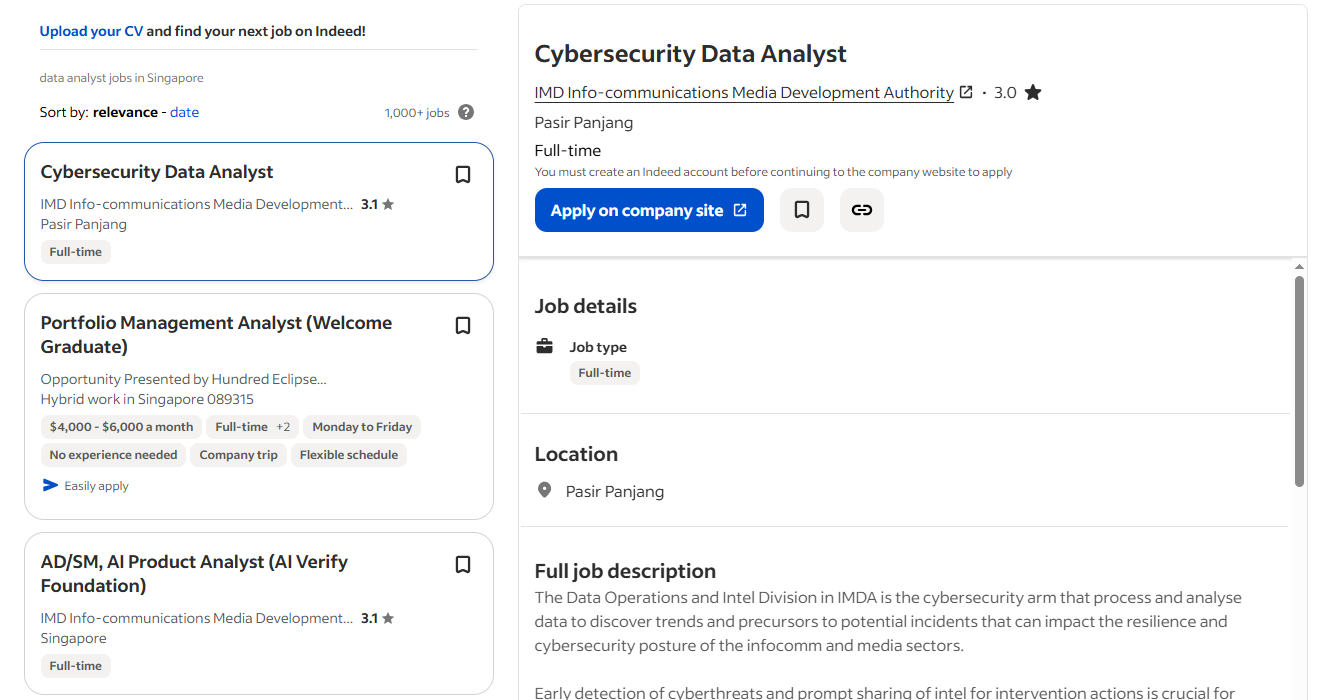
I’ve had excellent crawling results with sites like Indeed or company career pages because they depend on users being able to compare similar positions quickly. This business requirement forces consistent data presentation, which makes it perfect for crawling.
4. Review and Content Platforms
Review sites present user feedback in uniform structures with consistent rating systems and temporal organization.
News aggregators and content platforms, like Feedly or Google News, use standardized article previews with publication metadata.
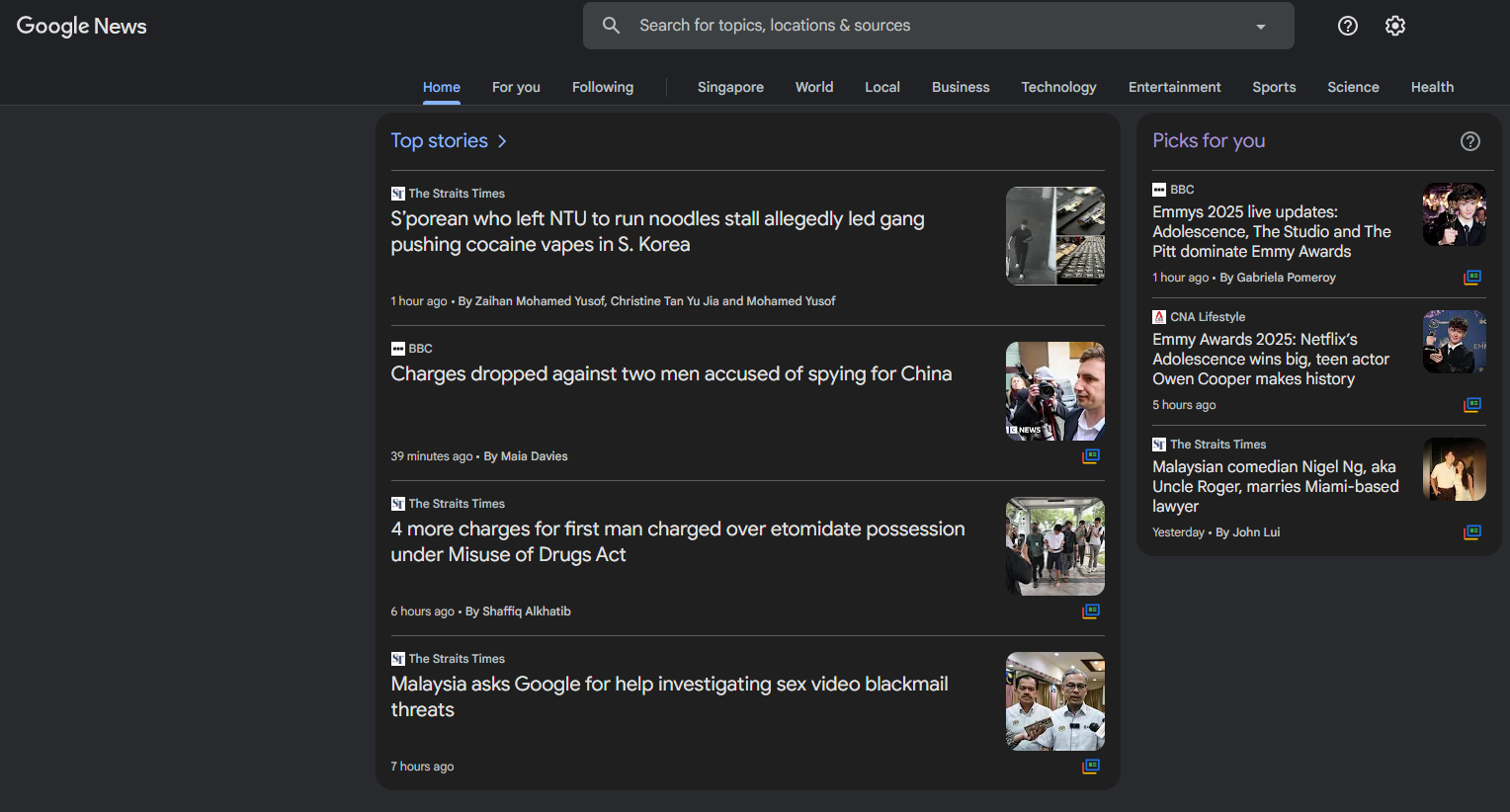
The common thread across successful listing sites: they present similar information with identical layouts. When you see the same data fields repeated with minimal variation, you’ve found an ideal list crawling site.
How To Tell if a Website’s Lists Are Crawlable?
Before I decide whether or not I can listcrawl a website, I run through a five-minute assessment. This assessment helps me decide whether the site will cooperate or fight against my extraction attempts.
1. Inspect Page Source Content
To get to the page source content you can just right-click any list item and view page source. Then, look for HTML elements containing your target data, consistent class names across similar items, and structured markup like JSON-LD.
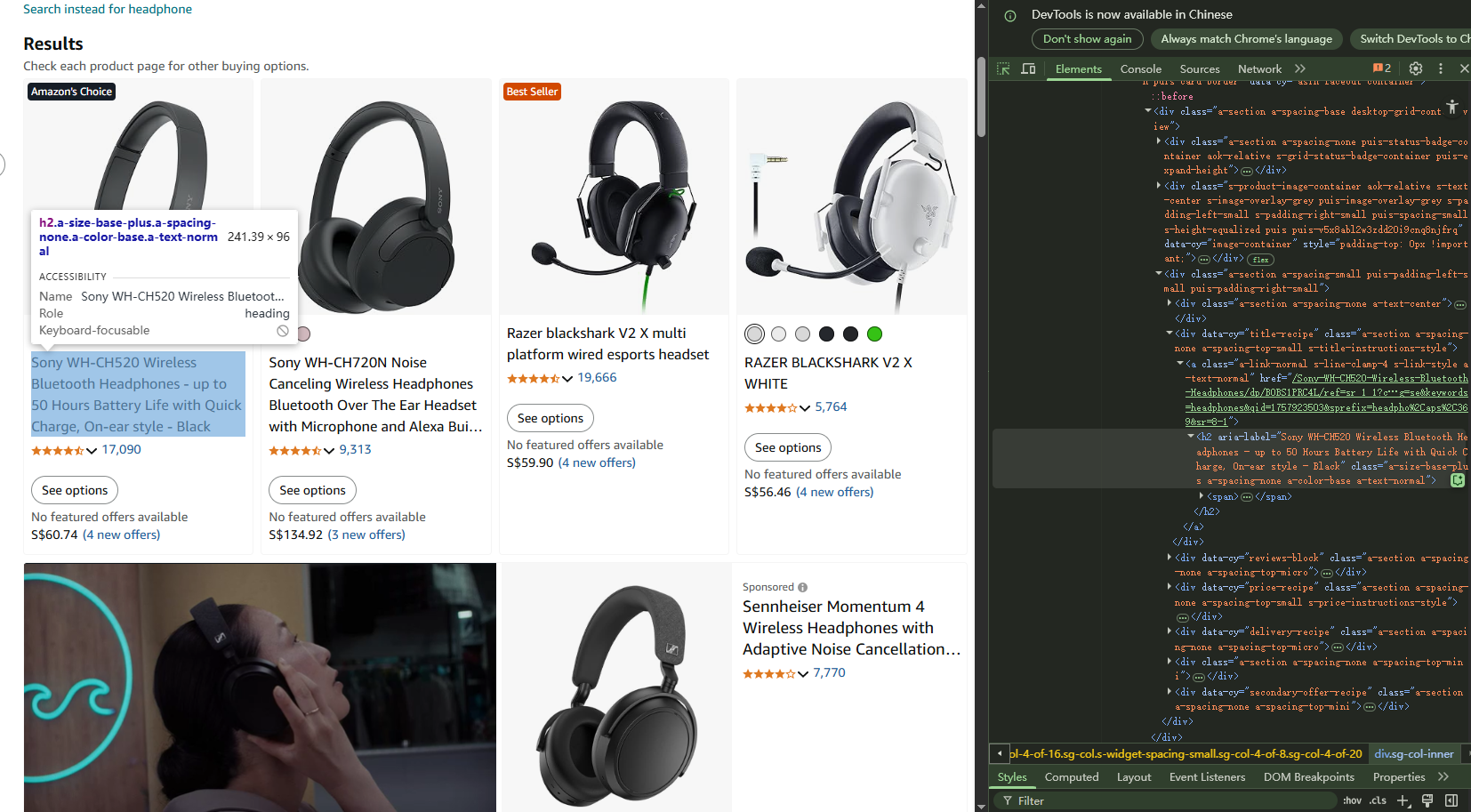
If you can see your target data clearly in the HTML source, it’s crawlable.
Note: empty divs or placeholder text that gets filled by JavaScript indicates dynamic content requiring more sophisticated techniques.
2. Check URL Structure Patterns
Crawlable lists use predictable URL patterns for navigation. I recommend looking for predictable URL patterns in pagination, such as:
- example.com/products?page=1 progressing logically to page=2, or
- category-based structures like example.com/electronics/p2.
Red flags include URLs that don’t change or have complex JavaScript-generated tokens. One time, I spent days on a site where pages all shared the same URL but different content loaded via JavaScript—pagination was fully dynamic.
3. Test Navigation Behavior
What I’d do is click through three or four pages manually.
Page numbers should work consistently, the browser back button should function properly, and list items should load immediately without delays.
When you find broken pagination, inconsistent navigation, or complex loading sequences, your web crawler configure may need some adjustment such as writing a Xpath for the pagination.
4. Check Rate Limiting Response
Open five or six pages rapidly in new browser tabs.
Pages that fail to load, display CAPTCHA challenges, or show “too many requests” messages indicate your automated crawling could be too aggressive.
List Crawling Different Type of Websites
When I don’t want to deal with coding and debugging, I’d prefer Octoparse for list crawling because it handles the technical complexity while letting me focus on getting the data I need.
You can download it free and it works on Windows (Mac version available too).
Different websites structure list data differently, so I always tailor my approach based on the type of list I’m dealing with. Here’s how I handle the three most common list structures:
1. How to Crawl Table-Based Lists
After I have assessed that the target data is table list, first thing I do is to open Octoparse. I click “Start with a URL” and paste the first page of the list I want to crawl.
The software loads the page in its built-in browser so I can see exactly what I’m working with.
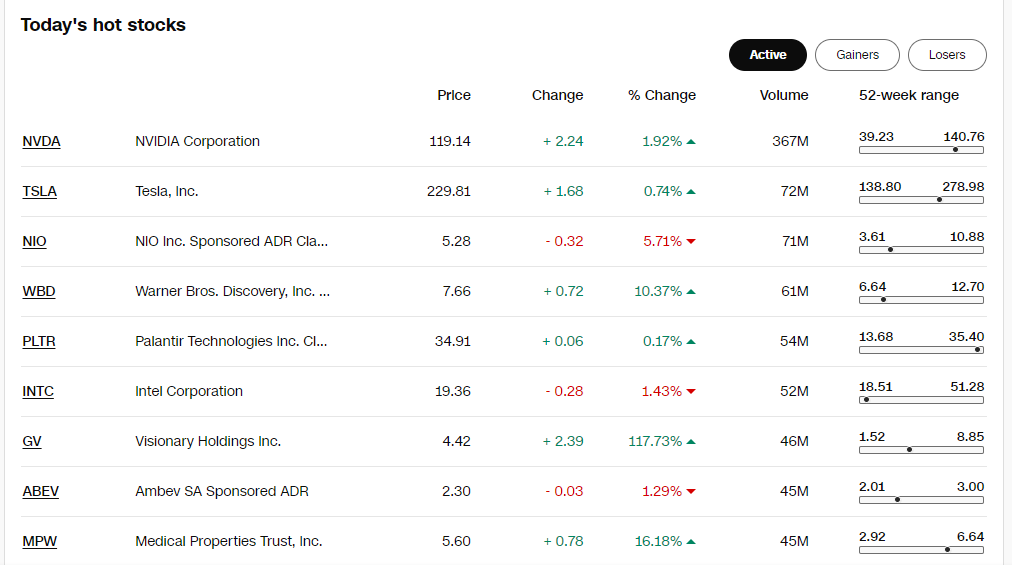
In this case, I am crawling CNN Markets, which is typical table list page.
Then, I use the Auto-detect web page data feature, which quickly scans the page and highlights the table elements, selecting rows and columns automatically.
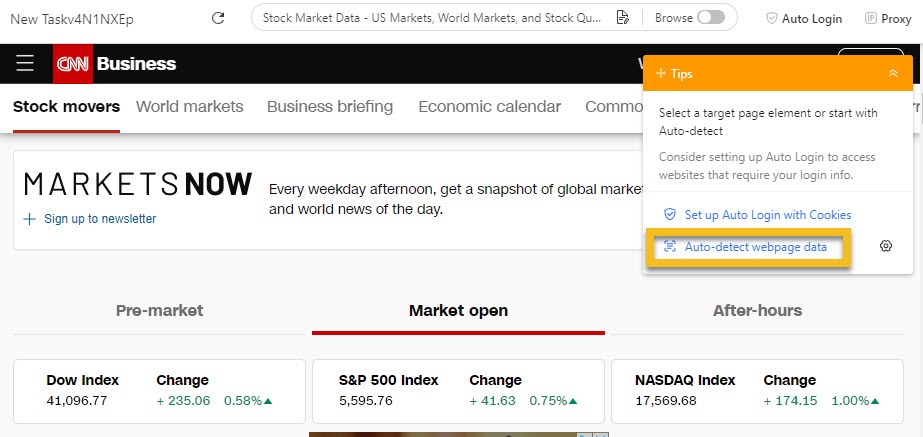
If the auto-detect misses something, I manually select the first cell of the first row and expand the selection until the entire row is highlighted. Octoparse then finds the other rows with similar structures for me.
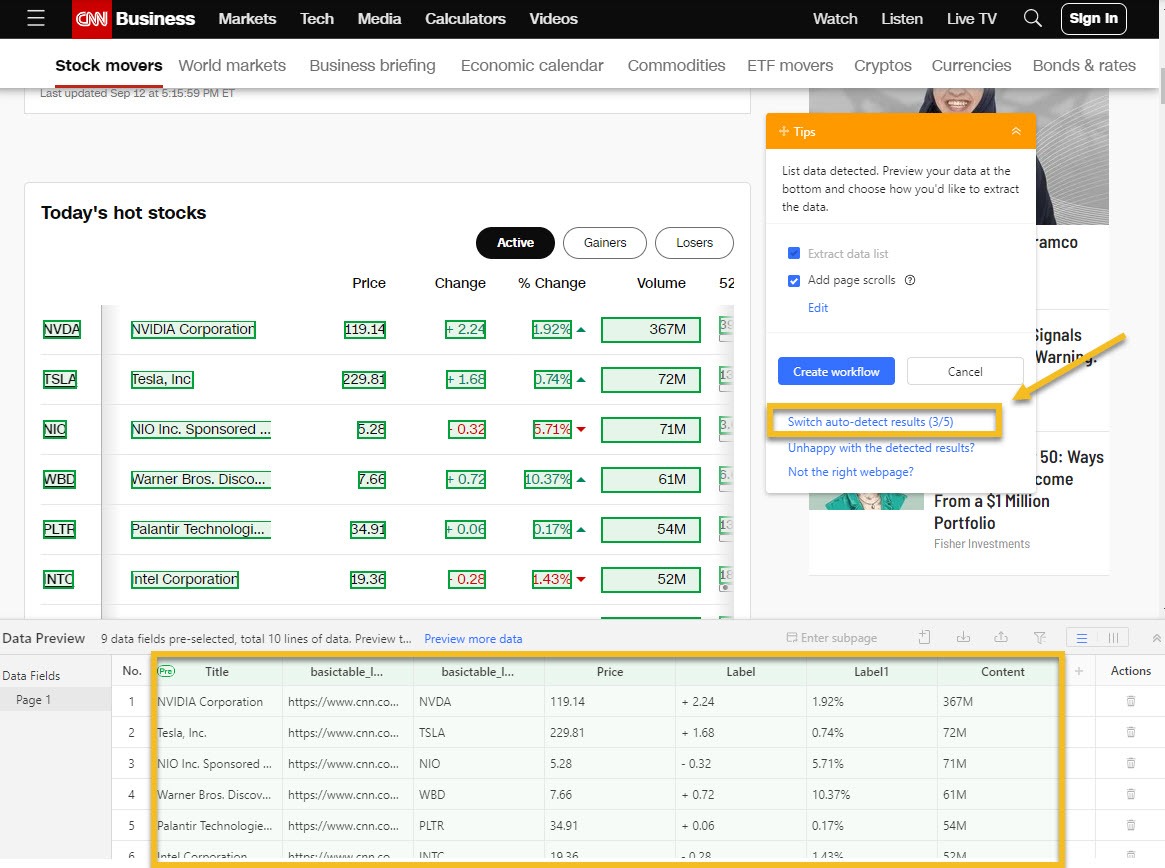
After that, I check that all the columns I want are included, rename any column headers for clarity, and remove unused fields. If the table spans multiple pages, I set up pagination by telling Octoparse how to click “Next” to crawl additional pages.
Finally, I run a test extraction to ensure all rows and cells are captured accurately before running the full list crawling and exporting the data in CSV or Excel format.
Futher Reading
You can learn more about crawling or scraping table data in Octoparse from our tutorial.
2. Crawling Data Inside Tabs or Tabbed Interfaces
Sometimes, websites use tabs to organize list data within one page—like product variants, specs, or user reviews in separate tabbed panels.
I load the webpage with tabs and set up actions to click each tab sequentially, ensuring the content within becomes visible for extraction. I then use the auto-detect feature or manual selection to capture data inside each tab.
If there are multiple tabs or nested lists, I configure looping so Octoparse dynamically visits and extracts information from every tabbed section.
A key trick is adding appropriate waiting times in the workflow when switching tabs, to let the page content load fully, especially if the tabs load data via JavaScript or AJAX.
3. Crawling Listing & Detail Page Structures
For websites that display product or article listings linking to detail pages, the crawling process involves two main steps: scraping the overview on the listing page, then clicking into each detail page to extract additional information.
I begin by entering the listing page URL into Octoparse and running the auto-detect feature to identify all items on the page. This creates a loop item extracting common data like product title, price, or summary.
Next, I configure Octoparse to click on each listing automatically and navigate to the detail page, where I set up additional data fields to extract finer details—such as full descriptions, specifications, or reviews.
Pagination is also set up so Octoparse loads and extracts data from multiple listing pages. After confirming everything works smoothly in a test run, I execute the full crawl. This approach allows me to build rich datasets combining summary and detailed information efficiently.
Futher Reading
You can learn in greater details about crawling detailed page data with this brief tutorial.
Why I Love This Layered Approach
Breaking the process down by list type keeps things straightforward for beginners while allowing technical readers to dive deeper if they want. Plus, Octoparse’s visual, point-and-click interface means even complex list crawls are accessible.
If you want to learn more about any of these techniques, I’ve linked to detailed tutorials that walk you through them step-by-step.
Common List Crawling Issues and How to Fix Them
1. No Data or Partial Data Extracted
This usually means the page didn’t load fully or the selection missed elements. To fix this:
- Increase the timeout for the “Go to Web Page” step to give pages extra load time.
- Sometimes, adding a scroll action ensures the entire list loads before extraction.
- I add short wait times between steps, especially when handling dynamic content.
2. Pagination Skips Pages or Misses Data
Misconfigured pagination often leads to data loss. I:
- Verify the XPath for the next-page button is precise and stable.
- Test pagination manually inside Octoparse to ensure it clicks through pages sequentially.
- Sometimes extending the AJAX load timeout helps pages load fully before moving on.
3. Duplicate Rows in Exported Data
Duplicate data often results from pagination errors like Octoparse clicking the same page twice or looping incorrectly. My fixes include:
- Tightening pagination XPath or switching loop modes.
- Relying on Octoparse’s automatic duplicate removal on cloud runs.
- Adding logic steps to detect and skip duplicate pages if needed.
4. Task Stucks or Freezes Mid-Run
Dynamic websites or heavy JavaScript can cause hang-ups. You should:
- Check the event log and error log to locate the problem.
- Add longer timeouts, scroll delays, or manual step breaks.
- Consider breaking large crawls into smaller chunks.
5. Encountering CAPTCHAs or Blocks
CAPTCHAs can completely stop crawling. I handle these by:
- Using Octoparse’s CAPTCHA solving step for common types like ReCAPTCHA.
- Implementing proxy rotation and varying request headers to appear less bot-like.
- Slowing crawl speed and adding random delays between requests.
To Sum Up
| Issue | Likely Cause | Quick Fix in Octoparse |
|---|---|---|
| No or partial data | Page not fully loaded | Add scroll or longer wait time |
| Pagination skips pages | Unstable XPath | Use “Auto-pagination” or re-select button |
| Duplicate rows | Looping same page twice | Enable “Remove Duplicates” in workflow |
| Task freezes mid-run | JavaScript-heavy site | Add delays or split crawl into smaller tasks |
| CAPTCHAs appear | Overly fast requests | Use proxy rotation + random wait times |
How I Clean and Prepare My Scraped Data
After scraping a list of data, it’s normal to find some problems that can make your analysis harder later on. For example, you might see:
- Duplicate rows showing the same item more than once.
- Missing information in some records.
- Dates, prices, or categories written in many different ways.
- Random HTML tags or strange symbols in text fields.
Here’s what I do to get my data in good shape:
- Remove duplicate rows
Duplicates can confuse analysis and overcount items. I use tools like Excel’s “Remove Duplicates” or in Python,df.drop_duplicates()in Pandas to clean them out. - Fill or remove missing data
If prices or dates are missing, I try to fill gaps with average values or similar entries. If there’s too much missing data, I might delete those rows. - Make formats consistent
I make sure all dates follow the same format and prices use the same currency style. For example,$19.99and19.99 USDboth become19.99. - Clean text fields
Sometimes descriptions include leftover web code or weird symbols. I remove HTML tags and extra spaces to keep descriptions neat.
Tools I Use For Data Cleaning
- Excel or Google Sheets: Great for small datasets or quick fixes of messy data.
- Python with Pandas library: Perfect for larger datasets or more advanced cleaning such as removing duplicates, filling missing values, and formatting columns.
- OpenRefine: A no-code tool that helps clean messy data by clustering similar entries and fixing inconsistencies.
Here’s a simple Python example of removing duplicates and filling missing prices:
Good data cleaning saves me time down the road, improves the accuracy of my analysis, and helps me trust the insights from my scraped lists.
Common Questions About List Crawling
1. How can I handle dynamically loaded list content like infinite scroll or content inside tabs?
Many modern sites use JavaScript to load list items dynamically as you scroll or when clicking tabs. To handle this, use tools that can execute JavaScript, like Octoparse’s built-in browser or Selenium. You may need to simulate scrolling actions or tab clicks and add wait times to give content time to load before extraction.
2. How do I avoid my crawler getting blocked when scraping dynamic lists?
Use proxy rotation, slow down request speeds with random delays, rotate user agents, and respect site rate limits. Octoparse offers IP proxy support and CAPTCHA solving to minimize blocks.
3. Can I scrape data from login-protected or session-based lists?
When a website requires login to see the data you want, your crawler needs to handle the login process automatically. Here’s how I do it in simple steps with Octoparse:
- Open the login page in Octoparse’s built-in browser.
- Click the username box, choose Enter Text, and type your username.
- Click the password box, choose Enter Text, and type your password.
- Click the Sign In button, choose Click Button to log in.
- To ensure fresh login each time, clear cookies before the page loads (set this in Go to Web Page > Options).
- Save cookies after login via Go to Web Page > Options > Use Cookie from Current Page to skip login next time (valid until cookie expires).
- If CAPTCHA appears locally, enter it manually.
If you want a detailed walk through about How to Scrape Data Behind a login.
4. Can I get into trouble for crawling publicly available lists?
Generally, crawling publicly available list pages (like product catalogs or directories) is allowed.
However, some sites explicitly prohibit automated data collection in their terms of service, which can lead to IP blocking or legal challenges. I would recommedn you to always review the site’s policies and consider asking for permission when in doubt.
Futher Reading
We discussed more in detailed in our blog about Is Web Scraping Legal. Feel free to check it out.
Conclusion
List crawling is the backbone of most web data extraction today, and knowing how to grab structured data from pages loaded with lists makes all the difference.
The trick is knowing when a site is crawl-friendly, how to dodge common traps like broken pagination or CAPTCHAs, and using tools like Octoparse to make it simple—even if you’re not a coder.
And don’t forget the legal side: stay within site policies, respect user privacy laws, and only collect data you’re allowed to use.
When you master these principles, list crawling becomes a practical and powerful tool for gathering the high-quality data you need.




