Scraping data from today’s dynamic websites isn’t always straightforward, especially if you’re not a programmer. AJAX, JavaScript, infinite scrolling, and dynamic updates can make life tough for anyone who wants to extract web data for analysis, research, or business.
As a data analyst and inhouse developer for 7 years in Octoparse, I’ve collected the most asked questions from our clients about web scraping AJAX and JavaScript Websites and I will show your how to tackle them with least hussle.
What is AJAX?
AJAX (Asynchronous JavaScript and XML) lets parts of a website update instantly , without refreshing the full page.
This means information loads in the background, often triggered by scrolling, clicking “Load More,” or responding to user actions. This means the data you want to crawl or collect isn’t in the HTML source right away.
Why Is AJAX Crawling/Scraping Challenging?
Dynamic content loads asynchronously after the page initially appears. This means:
1. The data you want might not be in the first page source.
2. You need to simulate user actions (clicks, scrolls) to trigger more data loading.
3. Timing is important — the scraper must wait for content before extracting.
4. Handling pagination or infinite scroll requires setting up loops and triggers carefully.
Most-Asked Questions About Web Scraping Dynamic Content
Below are the common questions I researched through web scraping forums and Octoparse’s own customer data. The solutions are for people with certain level of coding. If you would like to know about no-code methods for handling dynamic content, kindly browse ahead.
1. How do I crawl an infinite-scrolling AJAX website?
Here’s the thing nobody tells you: you probably don’t want to actually scroll.
Yes, you can use Selenium or Puppeteer to simulate scrolling, and sometimes that’s your only option. But it won’t be long till you realize that’s the slow, fragile way. Here’s what I do instead:
Open your browser’s DevTools (F12), go to the Network tab, and start scrolling. Watch what happens. Nine times out of ten, you’ll see XHR or Fetch requests firing off to endpoints like /api/products?offset=20 or /search/results?page=2. That’s your goldmine.
Instead of automating a browser to scroll for 20 minutes, just hit that API directly. Write a simple loop that increments the offset or page number. You’ll scrape in seconds what would’ve taken minutes, and your code will be 10x more reliable.
When you actually need to scroll: Some sites (like certain social media platforms) are smart enough to validate that scrolling happened. They check scroll position, timing, even mouse movements. In those cases, yes, use Playwright or Puppeteer. Add random delays between scrolls (2-5 seconds), vary your scroll distances, and for the love of all that’s holy, add a maximum scroll limit so you don’t accidentally trigger a memory leak.
2. How do I scrape data that’s behind a “Load More” or “Next” button?
This one’s my bread and butter. I’ve debugged thousands of these cases.
The quick answer: Click the button, wait for content, repeat. But let me save you some pain:
First, check if there’s a pattern. Click “Load More” a few times while watching the Network tab. If you see requests with incrementing parameters, congrats; you don’t need to click anything. Just request those URLs directly.
If you must click, here’s what actually works:
- Use explicit waits, not
time.sleep(). Wait for a specific element to appear or a loading spinner to disappear. - Always check if the button still exists before clicking again. Some sites remove it on the last page.
- Count your results before and after clicking. If the count doesn’t change, you’ve hit the end.
- Some buttons require scrolling into view before they’re clickable (yes, really).
Note:
Some sites use pagination buttons that look like they load new content but actually just filter existing content client-side. You’ll click 50 times and get the same 20 items. Always verify you’re actually getting new data.
3. How do I handle AJAX-heavy sites like Gumtree or Facebook?
Facebook is tough. They have entire teams dedicated to stopping you. Their DOM changes constantly, they use aggressive anti-bot detection, and they’ll ban your account faster than you can say “data collection.” If you’re scraping Facebook, you need:
- Residential proxies (datacenter IPs get flagged instantly)
- Real browser fingerprints
- Human-like timing and behavior
- Multiple accounts you’re willing to lose
- But honestly? Consider if the data’s worth it. I’ve seen companies spend $50K building Facebook scrapers that break every month.
Sites like Gumtree are more reasonable. Here’s my workflow:
- Open DevTools first, scrape second. I cannot stress this enough. Spend 15 minutes understanding how the site loads data before writing any code.
- Look for the API. Clear your Network tab, refresh the page, and filter by XHR/Fetch. You’ll usually find endpoints serving JSON. That’s what you want.
- If there’s no clean API, use Playwright (my personal favorite) or Puppeteer. Selenium’s fine but feels dated in 2025. Set up proper waits:
- Handle rate limiting gracefully. AJAX sites often have aggressive rate limits. Add delays (2-3 seconds minimum between requests), rotate user agents, and for the love of everything, catch and handle 429 status codes.
4. Can I scrape paginated content that loads on demand?
Absolutely, and this is actually one of the easier patterns once you understand it.
There are basically three types of pagination:
Type 1: URL-based pagination (?page=2, ?offset=20)
This is a gift. Just loop through the parameters. Check the last page to find your upper limit, then iterate. Done in 10 lines of code.
Type 2: POST-based pagination
The page sends POST requests with pagination data in the body. Slightly trickier, but just replicate those POST requests. Copy the headers (especially Content-Type and any auth tokens), copy the payload structure, and loop through.
Type 3: Cursor-based pagination
Each response includes a next_cursor or token for the next page. You need the previous response to get the next one. Keep a cursor variable and update it with each response until it’s null.
Real talk: After doing this for years, I always start by trying to find URL parameters. Check the page source, look at <a> tags for pagination, inspect form submissions. If you can find a pattern, you can skip 90% of the complexity.
5. Is it possible to scrape JavaScript-driven websites?
Yes, and if someone tells you otherwise in 2025, they’re stuck in 2010.
JavaScript rendering is expensive. It uses more memory, more CPU, and it’s slower. Way slower. If you’re scraping 10 pages, fine. If you’re scraping 10,000 pages, you need a different strategy.
My hierarchy of approaches:
- Find the API (always try this first)
- Use a lightweight renderer like requests-html for simple JS
- Use Playwright/Puppeteer for complex interactions
- Use a rendering service (Octoparse, ScraperAPI) if you need scale and don’t want to manage infrastructure
I’ve built scrapers that process millions of pages. The ones that use headless browsers for everything are the ones that cost $3K/month in server costs. The ones that use APIs directly cost $50/month. Choose wisely.
6. Does Octoparse support scraping dynamic and interactive elements?
I’ve evaluated pretty much every scraping tool on the market, and here’s my honest take:
Yes, Octoparse absolutely handles dynamic content, and it does it well. It has AJAX detection, pagination workflows, infinite scroll support, click automation, and sophisticated scheduling capabilities. More importantly, it’s built specifically to handle the kind of JavaScript-heavy, dynamic websites that give basic scrapers headaches.
Here is how Octoparse handle dynamic content:
- Supports sites that update content dynamically using AJAX/JavaScript.
- Offers clicks, scrolls, paginations, wait, and retry actions.
- Visual, no-code setup helps target interactive and nested UI elements—great for “Load More” buttons, menu expansions, multi-level navigation, and more.
- Also handles infinite scroll, lazy loading images, and scrolling news feeds, provided appropriate extraction settings, waits, and retries are configured.
Handle AJAX and JavaScript Sites Without Coding.
There are countless news sites that combine infinite scrolling with “Load More” buttons. It sounds complicated to extract their data, but here’s how straightforward it actually is.
First you can try a free trial with Octoparse.
Step 1: Start New Task and Enter URL
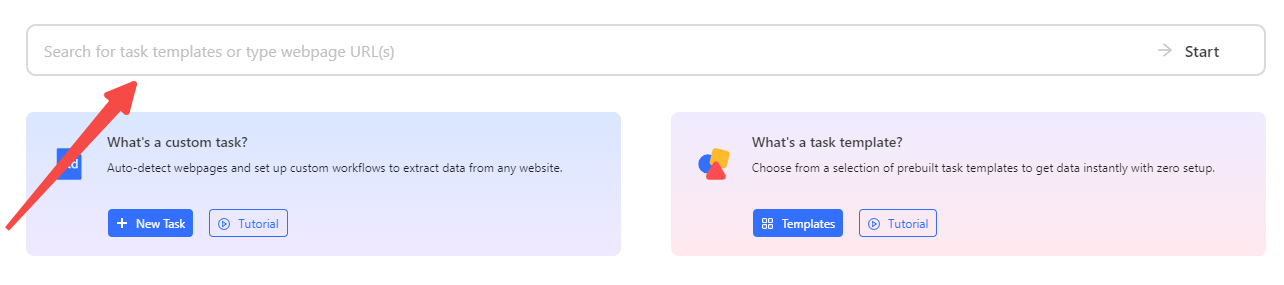
- Open Octoparse and create a new task by pasting the URL of the dynamic website you want to scrape.
- The site loads in Octoparse’s built-in browser, which fully renders JavaScript and AJAX content.
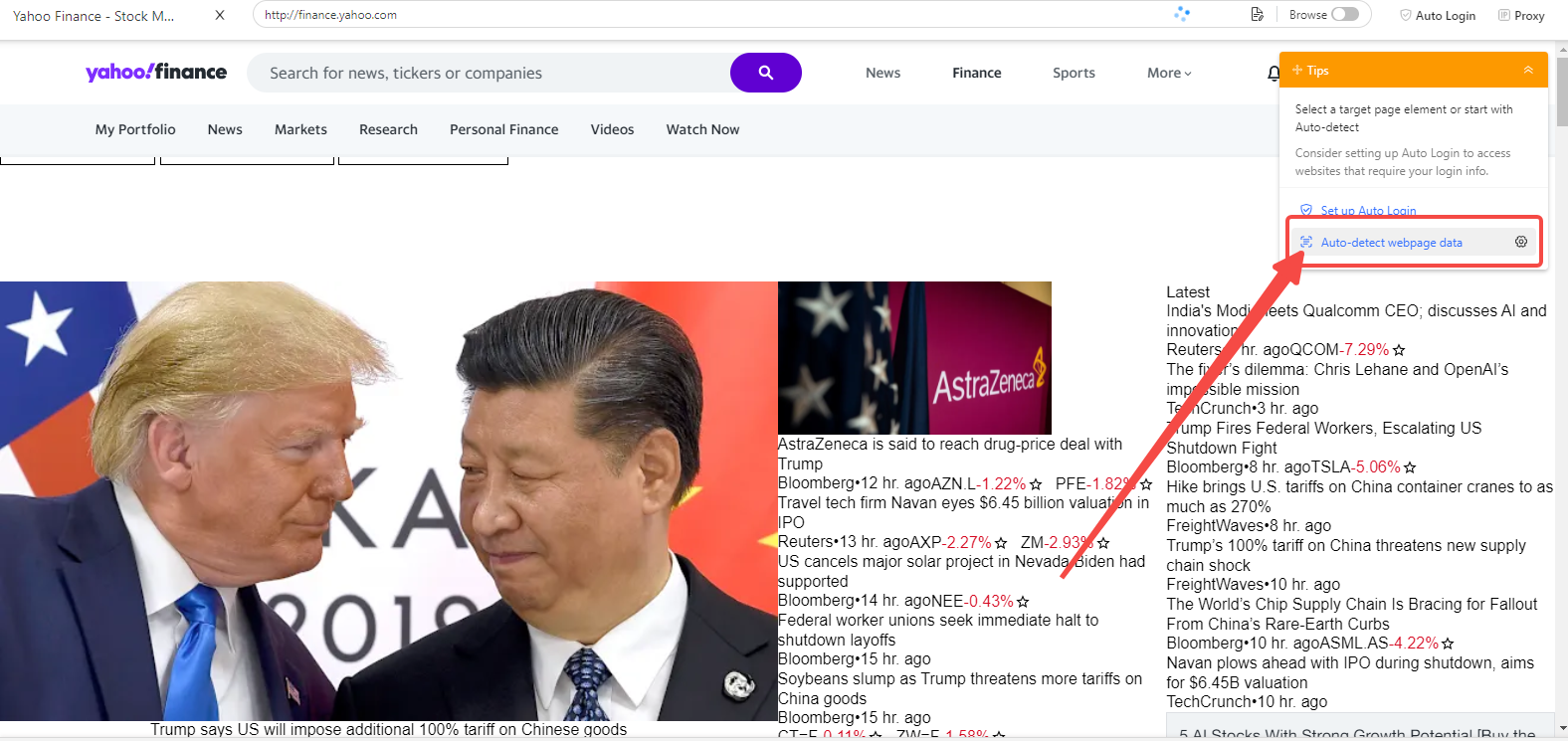
Step 2: Auto-Detect or Manually Select Data
- Use Octoparse’s “Auto-Detect Web Page Data” function to automatically find data elements on the page (product names, prices, news headlines, etc.).
- If auto-detect doesn’t find everything, manually click to select the data fields.
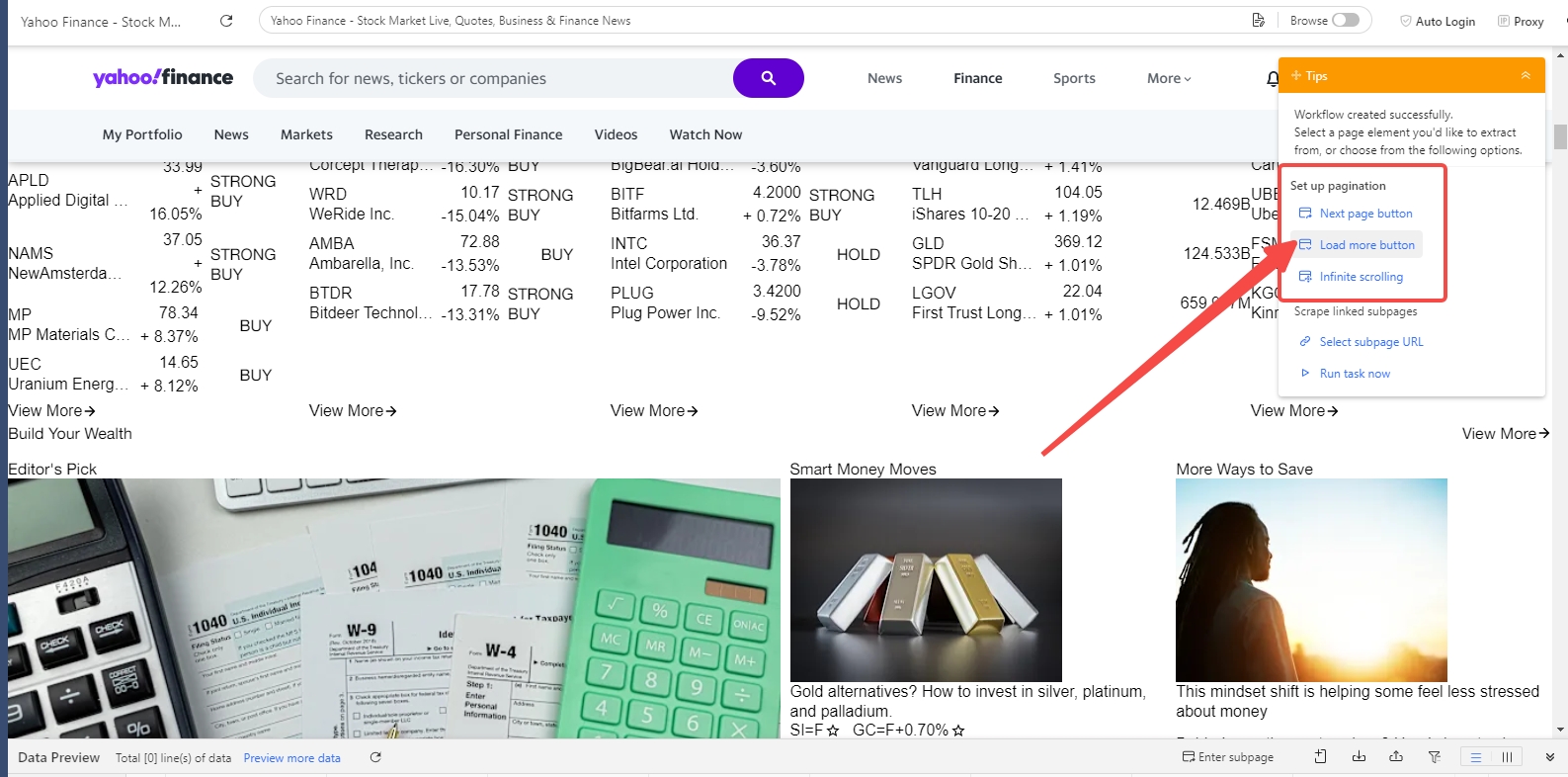
Step 3: Trigger Loading More Content (If Needed)
- For dynamic data behind “Load More” buttons:
- Select the “Load More” button.
- Add a “Click Item” action on that button.
- Set it to loop so Octoparse repeatedly clicks until the button disappears or no new content loads.
- Add a suitable AJAX timeout (e.g., 8-15 seconds) after each click for data to load.
- For infinite scroll pages:
- Add a “Scroll Page” action in the workflow.
- Set the number of scrolls and wait times to let content load completely.
Step 4: Set AJAX Timeout and Wait Settings
- After clicks or scrolls, configure wait times or choose “Wait until element appears” to make sure Octoparse extracts data only after AJAX content finishes loading.
- Adjust timeouts based on site loading speed.
Step 5: Configure Pagination Loop (If Applicable)
- If the site paginates with “Next” or page number buttons, select those elements.
- Add a click-and-loop action to navigate through pages until all data is scraped.
Step 6: Preview and Extract Data
- Use Preview Mode to confirm that all content loads as expected and data is fully extracted.
- Refine selections, waits, or loops if some data is missing or duplicates appear.
Step 7: Run Task and Export
- Run the scraping task locally or in Octoparse Cloud for scale and speed.
- When it’s done, export your complete article list to CSV, Excel, or directly to your database.
As you can see, Octoparse covers every aspect of dynamic content scraping in its features. That is why as a no-code web crawler/scraper it stood for so long in the web scraping industry.
Conclusion
Look, I need to be transparent here—I work for Octoparse, so take my recommendations with that context in mind. But after seven years in this industry, I’ve tested pretty much everything on the market, and I genuinely believe no-code tools have their place, especially for teams without dedicated developers.
If you’re comfortable coding, by all means, build custom scrapers using Playwright or Puppeteer. You’ll have complete control, and for certain complex scenarios, that’s absolutely the right call. But if you’re looking for a faster path to getting data (especially for large workloads) visual scraping tools can handle AJAX challenges without you needing to manage browser automation, timing logic, or infrastructure.
I’d suggest trying a few different approaches: sign up for free trials of tools like Octoparse, ScraperAPI, or others, and see what clicks for you. Compare that experience to writing the same scraper in code. The right choice depends on your timeline, technical comfort level, and how much ongoing maintenance you want to deal with.
The honest truth? Sometimes a no-code tool gets you 90% of what you need in an hour, versus spending days building and debugging custom code.