Bottom Line Up Front
1. To gather table data from the web, start with simple scraping if tables are static.
2. For dynamic, JavaScript-heavy sites, use browser-based tools like Octoparse.
Do you know? Around 30-35% of popular and well-trafficked web pages include one or more HTML tables with actual data.
But, if you want to crawl and extract the data for your use, it could be quite challenging. This is because the data is embedded inside the HTML which is unavailable to download in a structured format like Excel or CSV.
Web scraping is the easiest way to obtain table data on your local computer. In this guide, I will walk you through 4 easy ways to scrape table data from a website and export it into an Excel, CSV file, or to your database.
What is the Basic Structure of HTML Tables
Standard HTML tables used on websites are made up of these main elements:
- <table>: the container for the whole table
- <tr>: table rows
- <th>: header cells (usually the top row, column titles)
- <td>: data cells, the contents of the table
- <thead>, <tbody>, <tfoot>: optional groups to separate header, body, and footer sections of the table
Most simple or static tables, including many Wikipedia tables, follow this classic structure.
There Are 5 Types Of HTML Tables
1. Static HTML Tables
Tables fully present in the page source, fully formed using the above tags. These are easiest to scrape since the full data is retrievable with a basic HTTP request and HTML parser.
2. Nested Tables
Tables that contain other tables inside cells (<td> contains <table>). This adds complexity for extraction but still uses standard HTML.
3. Styled or Responsive Tables
Styled Tables use CSS or JavaScript to control visibility or layout but they still have a clear HTML <table> structure.
4. Dynamic / JavaScript-Rendered Tables
Common on modern stock sites like Yahoo Finance. These tables are often populated or modified using JavaScript after the initial page load, so the raw HTML from an HTTP request might not contain the actual data rows.
5. Non-Table Data Presented as Tables
This type of data is styled with <div> elements or grids to look like tables but lacks of semantic HTML table tags. Scraping these requires different strategies like XPath or CSS selectors focused on div classes.
Method 1:Scrape Table Data Without Coding
Octoparse is an easy-to-use web scraping tool that could help extract data at scale without any coding.
It is easy to get started with the auto-detecting function, just wait automatically and use drag and drop to make some customization. You can also build a workflow with advanced functions to get more accurate information you need from any website.
Octoparse also provides preset templates for popular websites so that you can extract data within a few clicks, such as this yahoo finance scraper:
https://www.octoparse.com/template/yahoo-finance-scraper
Below I will show you how I used Octoparse for collect HTML table data within 5 minutes.
4 steps to scrape a table from a website with Octoparse
Step 1: First, you need to download Octoparse and launch it, create an account, and try it for free.
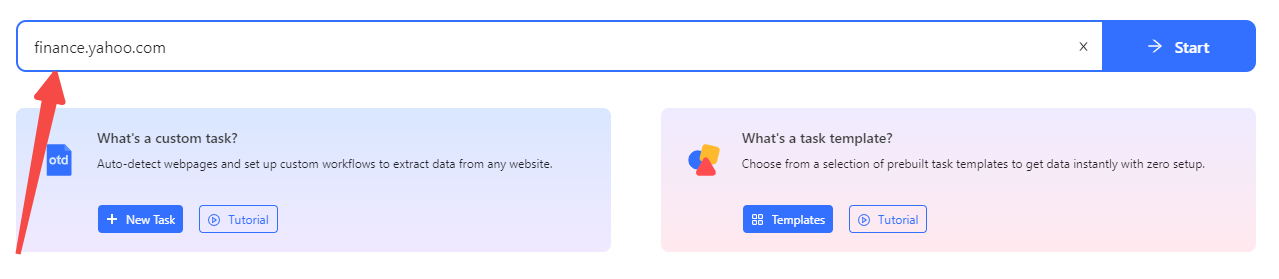
Step 2: Enter the target URL into the box and click the Start button to open the website in Octoparse built-in browser.
Say I want to scrape Yahoo Finance for financial analysis:
Step 3: Click the table data fields you want to scrape, and follow the “Tips panel” it gives to create pagination, loop, AJAX, and more to customize your workflow.
Step 4: Scrape a table with the below clicks.
a) Click on the first cell in the first row of the table
b) Click on the expansion icon from the “Action Tips” panel until the whole row is highlighted in green color (usually the tag should be TR)
c) Click on “Select all sub-elements” in the “Action Tips” panel, then “Extract data” and “Extract data in the loop”

Step 5: The loop for scraping the table is built into the workflow. Run it to extract data in excel, CSV, or any file format you want.
And the most amazing part is, we don’t need to know anything about coding. That said, whether we are programmers or not, we can create our “crawler” to get the needed data all by ourselves.
To learn more detail about scraping data from a table or a form, please refer to the detailed tutorial on How to extract data from a table/form or 3 methods to export HTML table to Excel.
2. Google Sheets to Scrape Table Information
In Google Sheets, there is a great function called Import Html. It can scrape data from a table within an HTML page using a fixed expression: “=ImportHtml (URL, “table”, num)”.
How to use Google Sheets to extract table data
Step 1: Open a new Google Sheet, and enter the expression into a blank. A brief introduction of the formula will show up.
Step 2: Enter the URL (example: https://en.wikipedia.org/wiki/Forbes%27_list_of_the_world%27s_highest-paid_athletes) and adjust the index field as needed.
With the above 2 steps, we can have the table scraped to Google Sheets within minutes. Apparently, Google Sheets is a great way to help us scrape tables to Google Sheets directly. However, there is an obvious limitation. That would be such a mundane task if we plan to scrape tables across multiple pages using Google Sheets. Consequently, you need a more efficient way to automate the process.
3. Scrape Table with R language (using rvest Package)
In this case, I use this website, https://www.babynameguide.com/categoryafrican.asp?strCat=African as an example to present how to scrape tables with rvest.
First thing is: download R (https://cran.r-project.org/) first.
Before starting writing the codes, we need to know some basic grammars about rvest package.
html_nodes() : Select a particular part in a certain document. We can choose to use CSS selectors, like html_nodes(doc, “table td”), or xpath selectors, html_nodes(doc, xpath = “//table//td”)
html_tag() : Extract the tag name. Some similar ones are html_text (), html_attr() and html_attrs()
html_table() : Parsing HTML tables and extracting them to R Framework.
Apart from the above, there are still some functions for simulating human’s browsing behaviors. For example, html_session(), jump_to(), follow_link(), back(), forward(), submit_form() and so on.
In this case, we need to use html_table() to achieve our goal, scraping data from a table.
Steps to scrape the table data with Rvest
Step 1: Install rvest.
Step 2: Start writing codes with the below keypoints included.
Library(rvest) : Import the rvest package
Library(magrittr) : Import the magrittr package
URL: The target URL
Read HTML : Access the information from the target URL
List: Read the data from the table
Step 3: After having all the code written in the R penal, click “Enter” to run the script. Now we can have the table information right away.
4. how to web scrape a table in python
Here I will show you how to scrape HTML tables from a webpage, say Yahoo Finance, with python. HTML tables like Yahoo Finance often have consistent structures suitable for this approach.
What this code does:
- Fetches the Most Active Stocks table from Yahoo Finance.
- Extracts the HTML table from the page.
- Converts it into an easy-to-use pandas DataFrame.
- Prints the first few rows and saves as a CSV file for further use.
But the thing is some sites load data dynamically with JavaScript, and this python code only works for static table data. For JavaScript-heavy pages, consider using Selenium or other browser automation tools.
Conclusion
Scraping table data from websites can be straightforward or complex depending on the site’s structure and technology. For static HTML tables, tools like Python’s requests, BeautifulSoup, and pandas provide a quick way to extract and save data. However, many modern sites including Yahoo Finance use JavaScript to dynamically load tables, which requires more advanced techniques.
This is where Octoparse shines, since it offers a user-friendly, no-code solution that handles JavaScript-rendered tables effortlessly. By simulating a real browser, Octoparse waits for dynamic content to load fully before extracting data, thus it’s ideal for scraping stock tables, product listings, and any web page where data loads asynchronously.
Now you have multiple ways to scrape tables effectively. Choose the method that fits your skills and project needs—Octoparse is your best bet for saving time, overcoming dynamic web challenges, and scaling your data extraction without coding headaches.




