If you have ever tried to log in to a website, there’s a good chance that you have been asked to enter some characters that are not easy to read. The illegible characters are called CAPTCHA. They are a little bit annoying for users and often drive people who are using web scrapers crazy as they are hard to deal with by scraping bots.
In this article, we will cover everything you need to know about CAPTCHA, why it’s used, the challenges it presents to web scraping, and how to ethically bypass CAPTCHA.
What is CAPTCHA
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a challenge-response test designed to determine whether the user is a human or a machine. Websites use CAPTCHA as a security measure to protect against bots that try to automate tasks such as data scraping, brute-force attacks, or spam submissions. Especially for e-commerce sites like Amazon, CAPTCHAs show when purchasing products online.
CAPTCHA tests typically require users to solve a puzzle or identify images, text, or objects that are difficult for machines to understand but easy for humans. The most common form of CAPTCHA asks users to identify and enter distorted characters from an image or select images containing specific objects.
General Types of CAPTCHA
There are several types of CAPTCHA that websites use to prevent automated access.
Text-Based CAPTCHA
A text-based CAPTCHA test is made up of two parts: a randomly generated sequence of letters and/or numbers that appear as a distorted image, and a text box for input. To pass the test and prove your human identity, simply type the characters you see in the image into the text box.
Simply showing the characters are not that difficult for bots. To increase the difficulty, there is mathematical CAPTCHA, which involves a basic math problem with easy-to-read numbers, and 3D CAPTCHA, which displays the characters with a 3D effect.

Image CAPTCHA
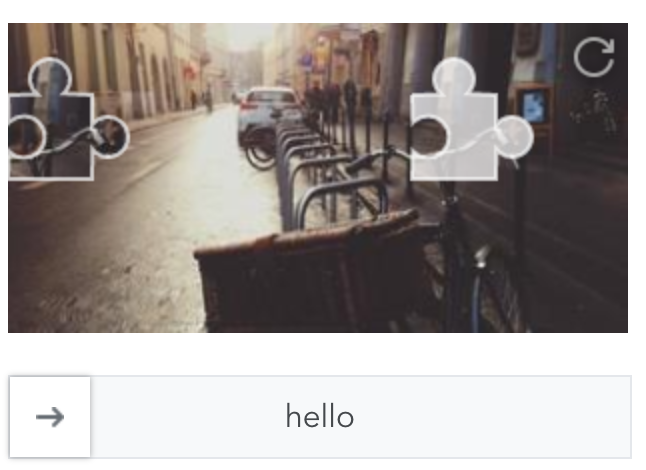
Image-based CAPTCHA usually provides users with images of objects, animals, people, or landscapes, instead of distorted text, to distinguish a human from a computer program. Users are required to select the correct images that they are asked to identify or drag a block into an image to make it complete.

Audio-based CAPTCHA
Audio-based CAPTCHA utilizes random words or numbers drawn from recordings, combines them, and even adds some noise to them. The users are required to enter the words or numbers in the recording. Sound CAPTCHAs are harder to deal with compared with content and picture CAPTCHAs as it is not easy to let a scraping bot learn to listen.
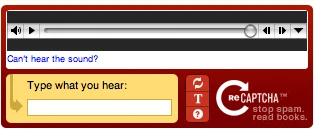
Invisible CAPTCHA
A more sophisticated version, often used by Google reCAPTCHA, where the system invisibly analyzes user behavior (like mouse movements or time spent on the page) to determine if the user is human without requiring visible interaction.
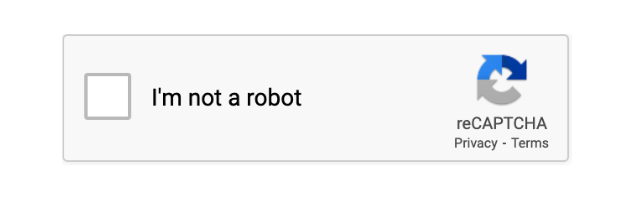
Puzzle CAPTCHA
It requires users to solve simple puzzles, such as identifying images that contain a specific object or sliding a puzzle piece into place, to prove you are human.
How Does CAPTCHA Work
CAPTCHA systems work by presenting challenges that are easy for humans to solve but difficult for automated bots. They typically rely on:
Pattern Recognition: Bots struggle with interpreting images, especially distorted or obscure ones, making image-based CAPTCHAs effective.
Behavioral Analysis: Invisible CAPTCHA systems analyze mouse movements, clicking patterns, and time spent on the page to determine whether the user is human.
Human Cognitive Ability: Certain tasks, such as recognizing objects in images or understanding distorted text, require human cognitive abilities, which are still difficult for machines to replicate.
Once a user successfully completes a CAPTCHA challenge, they are granted access to the website. This helps websites ensure that their data is being accessed by legitimate users and not automated bots.
Why CAPTCHA is a Challenge for Web Scraping
For web scraping, CAPTCHA poses significant obstacles. Bots, including those used for scraping, often face difficulties solving CAPTCHAs because they require human-like reasoning and perception. Here’s why CAPTCHA is a challenge for web scraping:
Interrupts Automation: CAPTCHA forces scrapers to halt their automation process and interact manually or use third-party services to solve it.
Limits Scraping Efficiency: Frequent CAPTCHA challenges can disrupt continuous scraping tasks and delay data collection, especially for large-scale web scraping projects.
Requires Human-like Interaction: Some CAPTCHAs require simulating human behavior (such as clicking images or recognizing patterns), which can’t be easily achieved through traditional scraping tools.
Therefore, bypassing CAPTCHA is essential for efficient web scraping, but it needs to be done ethically and responsibly.
Is It Legal to Bypass CAPTCHA
While bypassing CAPTCHA may be necessary for scraping, it’s essential to consider the ethical side. Web scraping should be done with respect to website owners and users:
Respecting Terms of Service: Most websites outline in their terms of service whether scraping is permitted. Bypassing CAPTCHA without permission may violate these terms, leading to potential legal issues.
Impact on Website Servers: Excessive scraping can overload servers, especially if done rapidly and without delays. Using proxies and limiting the frequency of requests helps minimize the impact on a website’s server resources.
Data Privacy: Avoid scraping private or sensitive data without proper authorization. Always adhere to privacy regulations, such as GDPR, when collecting personal data.
Ethically bypassing CAPTCHA means scraping responsibly and ensuring compliance with the website’s policies and data privacy laws.
Tips to Deal With CAPTCHA for Web Scraping
CAPTCHA can easily break down the crawlers you set up once it shows in the process of extraction, so dealing with it is quite essential for web scraping. Here are some tips for dealing with CAPTCHA challenges during web scraping.
1. Use CAPTCHA-Solving Services
Services like 2Captcha, Anti-Captcha, and DeathByCaptcha allow you to send CAPTCHA challenges to humans or AI systems that solve them for you. Integrating these services into your scraping tool can save time and effort.
2. Implement Proxy Rotation
Rotating IP addresses using proxies helps prevent detection and blocks by websites. By using multiple IPs, you reduce the likelihood of triggering CAPTCHA systems that are based on excessive requests from a single IP.
3. Use Web Scraping Tools with Built-in CAPTCHA Solvers
Some advanced web scraping tools, like Octoparse, come with built-in capabilities to bypass CAPTCHA challenges automatically using proxy rotation and integration with CAPTCHA-solving services. The data scraping templates and cloud scraping functions provided by Octoparse can also help you avoid CAPTCHA issues during web scraping.
Read the tutorial to set the CAPTCHA bypass solution in Octoparse: Resolve CAPTCHA during scraping with Octoparse.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
4. Delay Requests
Avoid sending too many requests in a short period. Slowing down the frequency of your scraping requests can reduce the chances of triggering CAPTCHA systems.
5. Use Browser Automation
Tools like Selenium allow you to simulate human-like interactions with websites, such as solving CAPTCHAs manually or using CAPTCHA-solving services in an automated way.
Final Thoughts
Bypassing CAPTCHA is a critical task for web scrapers looking to collect data from websites without interruptions. While CAPTCHA serves as a vital security feature for websites, it can pose challenges for scraping tasks. The methods outlined in this article, including proxy rotation, CAPTCHA-solving services, and automated tools like Octoparse, can help you bypass these obstacles efficiently.
Remember, ethical scraping is important. Always respect the website’s terms of service, ensure you’re scraping responsibly, and use data in a compliant manner. With the right approach, you can bypass CAPTCHA and continue your web scraping efforts smoothly.
Download Octoparse and start smooth web scraping without any coding now.