Web scraping is an essential technique for extracting data from websites, and it is widely used for tasks such as market research, competitor analysis, and price tracking. However, one of the biggest challenges web scrapers face is CAPTCHA. CAPTCHA is a security measure designed to block bots and automated tools from accessing a website. It is one of the most popular anti-scraping techniques implemented by website owners. So, solving CAPTCHA is the most important thing you need to do while web scraping.
In this guide, we’ll show you how to bypass CAPTCHA effectively with both coding and non-coding methods, so you can continue your scraping tasks without disruption.
What is CAPTCHA and Its Role in Web Scraping
CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart. It’s a test designed to differentiate between human users and bots. Websites use CAPTCHA to prevent automated access to their data by requiring users to complete tasks that are easy for humans but difficult for bots, such as identifying distorted text, selecting images with specific objects, or solving puzzles. There are many different types of CAPTCHAs including text, images, GeeTest, Cloudflare, etc. The techniques of CAPTCHA are also developed to protect the websites.
In web scraping, CAPTCHAs can disrupt the process, causing scraping tasks to fail. This is because web scraping tools are seen as automated bots, triggering the CAPTCHA system to block access. As a result, bypassing CAPTCHA is essential for successful data extraction.
How to Solve CAPTCHA without Coding
Though CAPTCHA is a big challenge for web scraping, there are many tools to solve this problem easily. Octoparse is such a no-coding web scraping tool to help you bypass CAPTCHA automatically. It provides many ways to solve CAPTCHAs such as proxies rotation, cloud scraping, manually bypassing CAPTCHA, etc.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Steps to solve CAPTCHA without coding
Step 1: Set the scraping workflow
At the beginning, you need to copy and paste the target URL into Octoparse. And starting auto-detection to create a workflow.
Step 2: Select CAPTCHA type you need to bypass
Once you’ve created the workflow for your scraping task, click on the Add Step button and select Solve CAPTCHA option from the dropdown list.
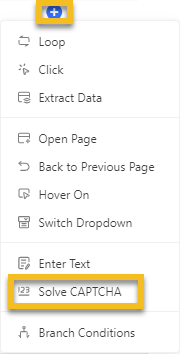
Next, click on the Solve CAPTCHA Type option to choose the CAPTCHA type you encounter. For example, you can choose ReCAPTCHA v2 or v3 to solve.
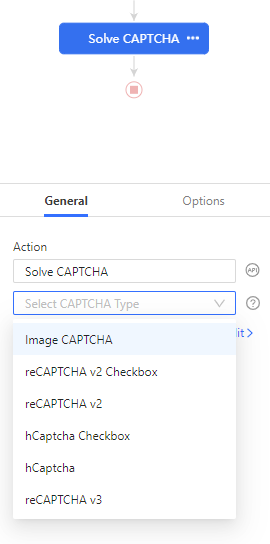
Finally, click on the Apply button to save the settings. Other CAPTCHA types like Image CAPTCHA can also be solved with similar steps.
Step 3: Run the crawler and bypass CAPTCHA
Check the data fields and other settings, and click on the Run button to start scraping. And Octoparse will help you bypass CAPTCHA when you running the task.
Still have questions about bypassing CAPTCHA with Octoparse? Move to read the detailed guide: How to Bypass CAPTCHA with Octoparse.
How to Bypass CAPTCHA with Python
For more advanced users, Python provides flexibility in bypassing CAPTCHA through libraries and integrations. Here’s a basic guide to bypass CAPTCHA while scraping using Python.
Steps to solve CAPTCHA in web scraping with Python
Step 1: Install the Necessary Libraries
You’ll need to install libraries like Selenium, 2Captcha, and requests for CAPTCHA-solving:
Step 2: Set Up Selenium for Browser Automation
Selenium is a browser automation tool that can simulate human behavior, which helps bypass CAPTCHA challenges.
Step 3: Solve CAPTCHA Using 2Captcha
You can integrate 2Captcha or other CAPTCHA-solving services to automatically solve CAPTCHA challenges.
Step 4: Complete the CAPTCHA Challenge
Once the CAPTCHA is solved, submit the result back to the website.
Step 5: Continue Scraping
After solving the CAPTCHA, you can continue scraping data from the site by interacting with the page elements using Selenium.
Tips to Prevent CAPTCHAs from Interrupting Scraping
1. Use rotating IP proxies, rotate user agents, and clear your cookies. Octoparse provides you with options to configure these. Normally, the website triggers an integrated anti-scraping detection service when the same IP starts hitting the servers aggressively. If you use thousands of proxies and rotate them, you may escape facing CAPTCHAs.
2. Obey the Robots.txt file. This file contains the rules about website preferences. For example, rules state whether the website allows you to scrape it or not. If yes, which URLs it does not want you to scrape?
3. Use headless browsers if you’re writing your web scraper, tools like Octoparse automatically take care of this, as they are smart browsers.
4. Try using headers, and referrers in your requests to the server if you’re not using a full-scale browser.
5. Beware of invisible honeypot traps on the websites. These are the elements or links that are not visible, so if you’ve written a crawler that scrapes these links, the website gets to know it’s a bot as humans can’t click that link using a normal browser like Chrome or Firefox.
6. Keep random delays between consecutive requests. Especially, when you’re hitting the website with the same IP addresses repetitively.
Final Thoughts
Bypassing CAPTCHA is a critical step in web scraping to ensure seamless and uninterrupted data extraction. Octoparse provides an easy, no-code solution to handle CAPTCHA automatically, while Python gives more flexibility for advanced users who want to create custom scraping solutions. Whether you’re scraping data for market research, price monitoring, or sentiment analysis, overcoming CAPTCHA is crucial to gathering accurate and up-to-date information.
With the help of Octoparse, you can bypass CAPTCHA and get back to scraping valuable data from any website easily. Download Octoparse and have a free trial to start web scraping without any interruption now.