“Is there a way to scrape ALL images from a website?”
This is a frequently asked question from Reddit as pictures on Pinterest and E-commerce websites are a big treasure especially for marketing reactionaries, E-commerce owners, and even scholars.
Therefore, You need an efficient way to scrape or download images from URL lists. That’s exactly what this guide will walk you through today: to show you how to scrape and download images, with or without coding skills.
There are 6 best image scraping tools mentioned, and you can choose the most suitable one according to your needs.
What is an Image Scraper
An image scraper can extracts images from websites by accessing web pages, identifying image files, and downloading images in bulk for content aggregation, analysis, or repurposing.
Image Scraper vs Image Downloader
Compared with an image downloader, an image scraper is more versatile and automated, while an image downloader is generally simpler and more specific in its function.
For example, an image scraper can collect the metadata (eg: image URL, alt text) of the pictures while an image downloader only download the picture itself.
| Feature | Image Scraper | Image Downloader |
|---|---|---|
| Function | Automatically extracts images and metadata (URLs, alt text) | Downloads images, usually one at a time |
| Automation | Built for batch scraping across multiple pages or sites | Generally simple, manual downloads |
| Use Cases | Building image datasets, SEO analysis, market research | Personal use, individual file saving |
In the following parts, you can learn the 6 best image scrapers also some top image downloaders to collect pictures and other data in bulk.
Top 5 Image Scraping Tools You Can Choose From
1. No-coding Image Scraper (Recommended)
The first one recommended for you is Octoparse – the best web scraping tool, which is not only an image scraper but also scraping text or any other information according to your needs.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Unlike a single-page image downloader, Octoparse helps you get multiple URLs of the needed images.
You’ll likely run into a few common roadblocks when downloading images from websites. Below are the typical issues you might encounter when extracting images from websites, and how to resolve them effectively using modern scraping tools.
1. Scrape images spanning over numerous pages
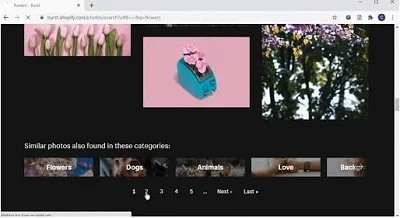
When using Octoparse to scrape images, you can add pagination to the crawler so that it can scrape down image URLs automatically over a multitude of pages.
Instead of downloading the images page by page using an extension tool, Octoparse could save you a lot of time.
2. Extract images crossing multiple screens
Unlike paginated sites, Google Images loads new results dynamically as you scroll (a design known as infinite scroll). Instead of new URLs, content appears through AJAX requests in the background.
A web crawler needs to simulate that scrolling behavior, so the page is fully loaded before you extract the data.
Octoparse can handle these AJAX-driven pages automatically — scrolling, waiting for images to render, and then capturing every loaded result
It uses a built-in browser that simulates human interactions and visually renders the page content to ensure all images are fully loaded before scraping begins.
Pro Tip: You can set the Octoparse’s built-in browser to scroll down to the bottom before starting to scrape.
3. Extract the picture separately without other information
People working on e-commerce product research won’t be satisfied with product images alone. They analyze the product’s appearance, price, and additional attributes to comprehensively evaluate its market performance.
With these two linked data sets (images and their corresponding details), you effectively build a small, structured product database ready for analysis and research.
Octoparse provides preset templates for scraping data from popular websites like Amazon, Booking, and others. You can extract both image URLs and related information—such as product details, restaurant specifics, or hotel data—in a synchronized manner.
Helpful Tip: From my own experience, it is also extremely useful if you’re working with an AI image detector, because sometimes you might need to check if these images are made by AI or not. These tools can help you analyze the product content you collected for authenticity, brand compliance, or automated categorization.
4. Bulk download thousands of images
This video is a tutorial that gives a step-by-step guide to help users scrape and download images from AliExpress with Octoparse.
When you get a hang of Octoparse web scraper, you can download images from any website without effort!
5. Batch scrape images but keep high-quality
Some websites provide low-resolution to high-resolution images in the codes. In this case, you need to figure out the right URLs first.
There would be two most-hunted issues: how to get all the image URLs in a carousel? How to make sure URLs are in high resolution?
The below articles can help you out:
How to Build an Image Crawler without Coding
How to scrape the full image URLs instead of the thumbnails?
6. Download pictures from an image URL list
You can bulk download images with image download tools, or you can use Octoparse built-in file downloading functions to get pictures directly.
2 Online Tools to Download Images from URL List

(Feel free to use this infographic on your site, but please provide credit and a link back to our blog URL using the embed code below.)
Forget about what browser you are using, try webpage tool to download the images if you don’t want to install anything on your devices.
2. Image Cyborg
Image Cyborg is a web app that quickly downloads all the images of a web page.
This tool has a simple and clear home interface, just like a search engine.
Though it is quite accessible, it comes with some apparent defects.
Note: This is my own experience of using Image Cyborg, please take it with a grain of salts.
1. Images are mostly low resolution and small-sized. Yes, most of them are thumbnail images.
2. The zip files share the same name: [image-cyborg]. Need to rename the file one by one.
3. Some logos or avatar images will be packed but you might need them.
3. extract.pics
extract.pics is another geeky tool with a simple and clear interface.
The best part of it is you can preview all the images before downloading and selecting or deselecting them.
However, you might bump into this error when you try to download all images with one click.
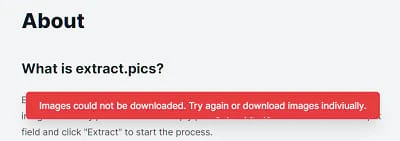
Well, if you want to know how to download all photos from a web page, you can learn it from our detail blog: “How to Bulk Download Images“.
Top 2 Image Downloader Extensions
4. Firefox
You may be surprised that everything is just behind a right-click.
You can download all the images of the present website by following a few simple steps with only a few seconds:
1. Open the website you are going to get images from with Firefox.
2. Right-click on the blank area, and you will see the option of “view page info”. Click it.
3. Skip the general information and click “Media”.
Then you will see a list of URLs of those images you are going to download.
4. Click “select all” – ”Save as”: Now you are getting all the images from the website!
Note: One caveat for this is that it can’t save the image files in web format as it doesn’t get detected by the “Media” option.
5. Chrome or Edge
If you’re using the Chrome browser, an image downloader for Chrome will be a good choice.
For Edge users, you can try Microsoft Edge Image Downloader.
Take Chrome as an example:
1. Open the website you are aiming to scrape pictures from.
2. Launch the extension tool, and it’s a white arrow on a blue background.
3. You’ll find it on the top-right side of the Chrome window.
This displays all downloadable images in a pop-up window.
Note: You will find that this tool offers a filter to help you get rid of those small, tiny icons and only download the normal-size pictures you need.
How to Extract Images with Python
If you are a developer, you can write codes to achieve basically everything.
Well, without further ado, these are the basic steps to download images from website with Python.
First, you need to install Beautiful Soup by typing pip install bs4 command line. And type pip install requests to install requests.
After that, follow the example code lines below:
How It Works:
Download Function: download_image() takes the image URL and saves it to the specified folder.
Scrape Images: scrape_images() fetches the page content using requests, then extracts all <img> tags with BeautifulSoup. It collects image URLs and downloads them.
Handling Relative URLs: If an image URL is relative (e.g., /images/pic.jpg), it’s converted to a full URL before downloading.
Conclusion
Now, you have learned both coding and non-coding ways to scrape and download images from websites easily and quickly along with other situations that are also listed for your reference.
Hope you find this article helpful.
And please remember, Octoparse is always the best image scraper if you need scheduled scraping or a large amount of image extraction.
Common Question When Scraping Images
1. Can I extract image metadata (like alt text or image size) while scraping?
Yes, image scraping tools can often extract image metadata such as the alt text, file names, image dimensions (size), and URLs along with the images themselves. This metadata is found in the HTML code of a webpage, usually inside the tags or related attributes.
- Alt text provides descriptions of images, helpful for SEO and accessibility.
- Image size (width and height) can be specified in HTML or determined after downloading the image file.
- Many web scrapers and tools like Octoparse or Python libraries (e.g., Beautiful Soup) can be programmed to capture this data to build comprehensive datasets.
2. How do I scrape images from websites with infinite scroll or lazy-loaded images?
Scraping images from pages with infinite scroll or lazy loading can be tricky because the images load dynamically as you scroll, rather than all being present in the initial page source.
To handle these, use tools and techniques that can:
- Simulate scrolling behavior like a human user to trigger loading of new images.
- Use scrapers with a built-in browser or headless browser that can run JavaScript, so it fully loads content before scraping.
- For example, Octoparse has a feature that auto-scrolls the page to the bottom before extracting images, enabling scraping all loaded content.
- In coding, tools like Selenium or Puppeteer control browsers to automate scrolling and detect newly loaded images.
This method ensures you capture all images, not just the ones loaded when you first visit the page.
3. Can I bulk download images from a list of URLs?
Yes, bulk downloading images from a list of URLs is a common task and can be done efficiently using:
- Specialized image downloader tools or browser extensions that accept a list of URLs and save the images in bulk.
- Scraping tools like Octoparse that can extract image URLs in batches and then automatically download them to your device or cloud storage.
- Writing a simple script (e.g., in Python) that reads the URL list and downloads each image using HTTP requests.
This approach is useful when you have the exact URLs but want to automate the download process instead of manual clicking.
4. How to Download High Quality Images?
First you need to identify these high quality images.
Look for size indicators that signal full-resolution files: URLs containing “large.jpg,” “original.png,” or specific dimensions like “2048×2048.jpg” typically point to high-quality images. Conversely, avoid URLs with obvious thumbnail indicators like “thumb.jpg,” “small.png,” or small dimensions like “150×150.jpg.”
You can often modify URLs to access higher quality versions. For Amazon product images, replace “.SL160” with “.SL2000” in the URL to get larger versions. Pinterest users can change “236x” to “originals” in the URL path for full-size images. Instagram photos ending with “?_nc_ht=” parameters usually indicate full-size versions.