The fastest way to bulk download images depends on what you have: a long list of image URLs, a single webpage, an entire website, or AI-generated outputs from Midjourney or DALL·E. This guide walks through the 5 best image downloaders that can download images from the URL list in bulk easily and quickly.
A bulk image downloader is any tool that fetches multiple images at once (from a URL list, a webpage, or an entire website) and saves them locally in one operation. Below is a quick map of which method fits which situation, then the full breakdown of each.
Quick Recommendation: How to Bulk Download Images
- You have a list of image URLs (in a CSV, spreadsheet, or pasted text): A free online CSV-to-ZIP tool. (See Method 1.)
- You’re on a single webpage and want everything visible: A Chrome extension. Image Downloader or Fatkun for general use. (See Method 3.)
- You only have a website (multiple pages, pagination, “load more” buttons): A no-code scraper like Octoparse to extract image URLs along with their context (product name, price, tags). Octoparse’s desktop client can also download the image files directly to a local folder in the same task. (See Method 2.)
- You need 10,000+ images, recurring runs, or something that lives in a pipeline: A Python script. (See Method 5.)
- You’re dealing with thumbnailed galleries, old forums, or image-hosting sites with non-standard markup: Desktop software like BID or NeoDownloader. (See Method 4.)
Method 1: Download images from a URL List (Online tool)
This is the simplest way when you already have the image URLs (pasted from a colleague, exported from a database, or sitting in a spreadsheet). An online bulk image downloader takes the list, fetches each image, and gives you back a single ZIP file. No installation, no coding.
How it works in 3 steps:
- Paste your URLs into a text box, or upload a CSV / Excel file with one URL per row.
- Pick the column that holds the image URL (and optionally a second column to use as the filename).
- Click download. The tool fetches each image in its original quality, packages everything into a ZIP, and serves it to you.
What to look for in a tool:
- CSV and Excel input: pasting 500 URLs into a text box is fine; pasting 50,000 is not. CSV upload removes that ceiling.
- Original quality, no watermarks: some converters compress or re-encode images. For e-commerce catalogs or archive work, that’s a dealbreaker.
- Custom filename support: without this, 10,000 images turn into
image_001.jpgthroughimage_10000.jpgwith no way to map them back to their source. - Retry on failure: bulk jobs always have a few failed URLs (server hiccups, redirects, expired CDN links). A good tool retries automatically and reports what couldn’t be downloaded.
Several free online tools cover this workflow well, including general-purpose ZIP exporters and dedicated downloaders that accept CSV input. The catch with online tools is that they all run inside your browser tab, so very large lists (tens of thousands of URLs) may hit memory limits. At that scale, jump to Method 5.
For a deeper walkthrough, see our guide on bulk downloading images from a URL list.
Method 2: Extract image URLs from Any Website (No-Code Scraper)
What if you don’t have a URL list and you only have a website? Maybe it’s an e-commerce category page with hundreds of product images, a Pinterest board, a real estate listing site, or a venue’s events page. You can’t paste a URL list you don’t have.
This is where a no-code web scraper earns its keep. Instead of guessing image URLs, the scraper opens the page, identifies every image element along with its surrounding context (product name, price, description, tags), and gives you a structured CSV. From there, you can either feed the URL column into a Method 1 tool or, if you’re using a scraper that supports it, download the image files directly in the same task.
Why does this method beat a pure image downloader:
A pure image downloader gives you a folder of files. That’s fine if all you need is the pixels. But a folder of 5,000 nameless JPGs is useless for competitive monitoring, building a labeled AI training set, or producing a content catalog, you’ve lost every connection back to what each image represents.
The no-code scraper gives you a CSV where every image URL sits next to its product name, price, description, and source URL. When you then save the actual files, each one is labeled, sortable, and traceable.
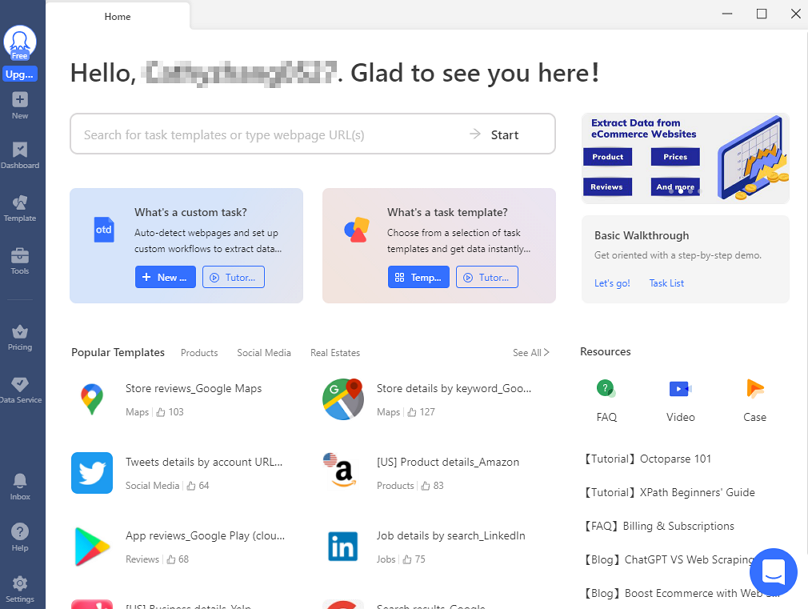
Octoparse is a no-code web scraping tool that extracts structured data from any website without writing code. It’s particularly suited to the image-plus-context workflow because it handles both URL extraction and metadata pairing in a single task, and the desktop client can save the image files locally at the same time.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Here’s the typical flow:
- Paste the target URL into the Octoparse desktop client and let auto-detect identify the relevant fields (most listing-style pages work in one click).
- Confirm that the image URL field is included alongside the metadata fields you want (title, price, description, etc.).
- If you only need the URLs: run the task and export the result as CSV. Each row has the image URL plus its context. Feed the URL column into a Method 1 tool or a Method 5 Python script to download the files.
- If you want the image files saved automatically: select the image field and click “Image file” to enable file download. Octoparse will scrape the URLs and save the image files to a local folder during the run, with naming options (original filename, MD5 hash, data field value, etc.).
The file-download function runs in local runs only, cloud runs extract URLs but don’t save files. Supported formats include JPG, PNG, GIF, plus common document types (PDF, DOC, XLS, ZIP). For full setup instructions, see the Octoparse help article on scraping and downloading files from websites.
What’s more, Octoparse provides preset online templates for hot sites. With these data scraping templates, you can easily extract pictures from eBay, Amazon, and other sites without any coding. Try the template example below:
https://www.octoparse.com/template/amazon-product-details-scraper
A real-world example
A US-based independent events publisher performs image scraping with Octoparse, to collect event data, including names, dates, ticket prices, descriptions, and image URLs, from approximately 70 venue and ticketing sites each week. The structured data exports directly to Google Sheets, where the image URLs are paired with their event context. Active listings grew from roughly 450 to over 4,500 — a tenfold expansion — without adding editorial headcount. With the image URLs and metadata in hand, the team can batch-download any subset of images they need for newsletters, social posts, or feature articles.
One pattern worth flagging before we move on: across our user base over the past year, Contact Details has been the fastest-growing scraping workload we track, with aggregate annual usage running in the tens of thousands of runs. The pattern there is the same as in event aggregation: users aren’t just scraping the image, they’re scraping the image together with the surrounding context (business name, address, phone). If you only need pixels, an extension is enough. If you need pixels paired with data, a no-code scraper is what scales.
https://www.octoparse.com/template/contact-details-scraper
Method 3: Chrome Extension for Quick Page Downloads
For a single webpage you’re already browsing (a Pinterest board, an article with embedded photos, a product gallery), a Chrome extension is the lightest option. Click the extension icon, see every image on the page, filter by size or type, hit download.
Three extensions stand out by install count, ratings, and how they handle real-world page complexity:
1. Image Downloader
– Average Rating: ★★★½
Image Downloader is an easy-to-use extension that allows users to browse and download multiple images from any web page with just a few clicks. After installing the extension, users can simply click the toolbar icon on any page and be presented with a pop-up window displaying all visible images. Images can then be selectively downloaded individually or all at once with one click by using the download button.
Powerful filters allow sorting and selecting images based on attributes like width, height and URL. Images can also be opened directly in a new tab for closer inspection. Image Downloader is an invaluable tool for anyone looking to grab multiple photos from the web with minimal effort.
2. Fatkun Batch Download Image
– Average Rating: ★★★★½
Fatkun Batch Download Image is a powerful image downloading tool that allows users to bulk download all visible photos on a webpage with just one click. The extension displays all images it detects on the current page and provides filtering options to sort by resolution or image link. Users can selectively choose and download individual pictures as needed. It supports downloading pictures from all major websites, utilizing smart scripts to automatically filter product images on e-commerce sites like Amazon into separate category views.
With over 800,000 users, Fatkun Batch Download Image is a highly effective solution for anyone looking to easily grab multiple images from online in a batch. The extension is continuously updated to add compatibility with new sites and improve functionality.
3. ImageAssistant Batch Image Downloader
– Average Rating: ★★★★½
ImageAssistant Batch Image Downloader is a powerful image downloading tool that allows users to easily extract and download all visible images on any webpage. After installing the extension, users can click the toolbar icon on pages to detect, analyze and view all available photos. Advanced sniffing capabilities ensure images loaded via Flash, AJAX or other technologies are still captured.
Users can then selectively download images individually or in bulk with a single click. ImageAssistant is effective at batch image extraction from any website. It is continuously updated to provide the best compatibility and user experience.
Honest Limitations of any Chrome extension
- No CSV or URL list input : extensions only see what’s on the current page. If your URLs are in a spreadsheet, use Method 1 instead.
- Can’t crawl multiple pages: pagination, infinite scroll, and “load more” buttons mean an extension misses everything past the visible viewport. For a whole site, use Method 2.
- Lazy-loaded images may be missed: most extensions read the page’s current state. Images that only load when you scroll won’t be captured unless you scroll through the whole page first. ImageAssistant handles some of these cases via its sniffing engine, but it’s not foolproof.
Note: A few well-known extensions we chose not to feature: Tab Save (functional but more general-purpose, it saves tabs, not specifically images, and its image-only workflow is weaker than the three above), and the Chrome-version of Bulk Image Downloader (a bridge extension to the Windows desktop app, if you want the BID workflow, install the desktop app directly). The Chrome Web Store pages for those extensions already rank for their own names, so there’s no value in duplicating their descriptions here.
Method 4: Desktop software for large galleries and forums
Desktop bulk image downloaders are a niche but useful category. They earn their keep on three specific kinds of jobs that browser-based tools struggle with:
- Very large galleries (10,000+ images), where browser memory becomes a bottleneck
- Thumbnailed galleries that hide the full-size image behind a click — desktop apps follow the thumbnail-to-fullsize chain automatically
- Older forum threads and image hosting sites with non-standard markup that extensions and online tools can’t parse
Two long-running options dominate this category:
Bulk Image Downloader (BID) by Antibody Software: A Windows desktop app first released in the mid-2000s. Handles thumbnailed galleries, integrates with browsers via context menu, queues multiple gallery URLs for unattended downloading. Free trial limited to 500 images per URL; full version is paid.
NeoDownloader: Similar feature set, with parsers built for 1,500+ specific sites including DeviantArt, Flickr, Pinterest, and Reddit. Drag a URL into the floating basket and it crawls the page automatically. Paid software with a free trial.
You probably don’t need either of these if your use case is “download the images on this one page.” Save desktop software for when you’ve already tried an extension or online tool and hit a wall.
Method 5: Python script for developers
If you’re comfortable with code or you’re building a recurring pipeline (a daily scrape, a CI/CD step, a workflow tied to a database), a short Python script is faster and more flexible than any GUI tool.
Here’s the minimum that works:
Swap urls for a list loaded from a CSV (urls = pd.read_csv("images.csv")["image_url"].tolist()) and you’ve got the bridge from Method 2’s output to a bulk download.
For more demanding setups, look at aiohttp for async I/O when you’re moving past a few thousand images, and Pillow if you need to convert formats, resize, or strip EXIF data on the way in.
When to write code instead of using a tool: automated daily runs, integration with a database or cloud storage, authentication-protected sources, anywhere the workflow needs to live inside a larger system. For a one-time grab, a tool is faster.
Related: build an image crawler without coding covers the no-code equivalent when the team writing the workflow isn’t a developer.
Common Use Cases: Who Needs to Bulk Download Images?
Designers and creatives building moodboards, reference libraries, or AI prompt inputs. A Chrome extension (Method 3) handles the day-to-day grabs; pair it with an online URL-list tool (Method 1) when collaborators send over batches.
AI dataset researchers are training computer vision models, where images need to come with labels. This is where Method 2 + Method 5 shines: a no-code scraper pulls image URLs with their metadata (product category, alt text, tags) into a CSV; a Python script then downloads the files. The metadata becomes the labels — without that pairing, you’re back to manually tagging thousands of images.
Marketing and content teams aggregating event imagery, UGC, or campaign assets across many sources. The no-code Method 2 workflow is what lets a small editorial team track every venue in a city without manual coverage caps. The events publisher case profiled above is the cleanest example we’ve seen of this scaling pattern.
AI-generated image collectors archiving outputs from Midjourney, DALL·E, Stable Diffusion, and similar tools. This is a new use case driving extension development in 2025–2026: the top-ranked “Bulk Image Downloader” extension on the Chrome Web Store now lists AI image support (data:image URLs, AVIF, WebP) as its first headline feature.
How to Bulk Download Images Safely and at Scale
Bulk downloading is straightforward when you’re grabbing 50 images. At 5,000 or 50,000, three things start to break: your IP gets blocked, your browser session gets fingerprinted, and you start running into copyright questions you didn’t have to think about before. Here’s how to handle each.
- Respect rate limits and rotate IPs
Aggressive bulk downloading can trigger IP blocks within minutes. The standard defense is IP rotation. Octoparse’s built-in proxies, for example, use residential IPs (harder to detect than datacenter IPs) and let you choose a country and rotation frequency (a typical setting is rotating every 5 minutes). Pricing is usage-based, with monthly proxy credits included in Standard and Professional paid plans. For current pricing, see Octoparse pricing.
For step-by-step setup, see how Octoparse IP rotation works and the IP proxies documentation.
If you’re using a Chrome extension or desktop software that doesn’t support rotation, manually slow your concurrency. Five to ten concurrent downloads is usually safe on most sites; fifty or more will get you blocked within minutes.
- Use cloud distribution to spread requests
Beyond rotating a single IP, distributing requests across multiple cloud nodes lowers the risk of any single source getting flagged. Octoparse’s cloud extraction, for example, breaks a large scraping task into smaller subtasks and assigns them to multiple cloud nodes running in parallel, with each node using its own IP from Octoparse’s global server pool. Because the target site sees requests coming from many different IPs at varying times instead of one local IP hammering it, the block risk drops sharply. (Note: cloud extraction handles URL collection at scale; if you need the image files saved automatically as part of the run, use the desktop client’s local-run mode covered in Method 2.)
- Layer browser-level defenses: UA rotation and cookie clearing
Sites don’t only fingerprint IPs — they also profile your browser. Two simple defenses make a bulk scraping task look more like normal browsing:
- Rotate user agents. Set the scraper to switch between desktop and mobile browser identities on a schedule. Sites can’t easily cluster requests as “one bot” when each request looks like a different browser version.
- Auto-clear cookies. Configure the scraper to wipe cookies every few seconds, or sync the clearing with each IP rotation. This prevents the site from tracking your session across pages and concluding you’re a single user fetching thousands of images.
Both options are toggleable in most no-code scrapers’ anti-blocking settings. For details on how Octoparse handles each, see the anti-scraping measures documentation.
- Respect copyright and robots.txt
Technical defenses prevent blocking, but they don’t address legality. Downloading public images for personal reference is generally low-risk. Republishing scraped images, training a commercial AI model on them, or scraping a site that explicitly forbids automated access in its robots.txt or terms of service can create legal exposure. The hiQ v. LinkedIn ruling (2022, Ninth Circuit) clarified that scraping public data isn’t automatically a CFAA violation in the US, but copyright and contract law still apply. When in doubt, check the source’s Terms of Service first.
FAQs About Bulk Image Downloader
How do I download a lot of images at once?
Use a bulk image downloader matched to your input. For a list of URLs, online tools that accept CSV input work fastest. For images on a single webpage, a Chrome extension like Image Downloader or Fatkun is enough. For an entire website with multiple pages, a no-code scraper like Octoparse extracts image URLs along with their metadata, and the desktop client can save the image files directly to a local folder in the same task.
How do I bulk download images from a website?
If you don’t yet have the image URLs, use a no-code web scraper. Tools like Octoparse can extract every image URL on a site — along with related data like product names, prices, or descriptions — and either export to CSV (so you can feed the URLs into a separate downloader) or save the image files directly to a local folder when running the task on the desktop client. This is the only path that gives you the images labeled with their context, which matters for e-commerce catalogs, AI training sets, and content aggregation.
What is the best image downloader extension for Chrome?
For Chrome, Image Downloader and Fatkun Batch Download Image are the two most-installed classic options, with combined user bases over 800,000 (Source: Chrome Web Store, 2026). Both detect all images on a page, let you filter by resolution, and download in one click. Neither handles CSV input or multiple pages — for those, use an online tool or a no-code scraper instead.
How do I download 1,000 photos at once?
For 1,000+ images, a Chrome extension will likely fail or hit memory limits. Use either an online bulk image downloader that accepts a CSV of URLs, or a no-code scraper like Octoparse to extract URLs first (along with related metadata). For 10,000+ images, a Python script with concurrent downloads is more reliable than any GUI tool.
Is it legal to bulk download images from a website?
It depends on the site’s terms of service, the images’ copyright, and how you use them. Downloading public images for personal reference is generally low-risk. Republishing them, training a commercial AI model on them, or scraping a site that explicitly forbids automated access in its terms can create legal exposure. Always check the site’s Terms of Service first.
What’s the difference between an image extractor and a bulk image downloader?
An image extractor pulls image URLs from a webpage so you can see or copy them — the output is a list of links. A bulk image downloader takes URLs (whether extracted or already in hand) and saves the actual image files locally, the output is a folder or ZIP of pictures. Some tools combine both steps. Octoparse, for example, extracts image URLs along with related data (product names, prices, descriptions), and the desktop client can also save the actual image files in the same run. For a tour of online extractors specifically, see our roundup of free image extractor tools.
Final Thoughts
The right method depends on what you have on hand:
- If you already have a list of image URLs, an online tool (Method 1) gets you to a ZIP file in minutes.
- If all you have is a website and you need image URLs paired with context, product names, prices, descriptions, a no-code scraper (Method 2) is what scales, and Octoparse’s desktop client can also save the actual image files in the same task.
- For quick one-page grabs, a Chrome extension does the job, a classic one if you just need the images.
- For very large or specialized galleries, desktop software earns its keep. And for anything that needs to run on a schedule or live inside a larger system, write the Python.
If you regularly need to grab images and their underlying data from multiple websites, Octoparse’s 600+ pre-built templates and free tier are the fastest way to start with Method 2. For one-off jobs, Method 1 or Method 3 is usually enough.