How to get images from a website
As you may notice, in many cases we need to save a list of images from a website and it can be very tiring and tedious work just by clicking and saving images one by one.
In fact, a web scraping tool is the perfect pick to automate this job. Instead of endless clicks across web pages, you just need to configure a task within 5 minutes and the robot will get you all the image URLs. Copy them into a bulk image downloader and you will get things done in just 10 minutes.
Get prepared with a web scraping tool
The first step is to download the web scraping tool on your computer. Octoparse is the tool we will use in this task. Don’t worry. This is a foolproof guide and you don’t need any programming experience to get started!
Note: Octoparse offers a free plan for our users. You don’t need to pay for any features mentioned in this guide.
Get all the image URLs in 3 steps
#Step 1: Create a task
Launch Octoparse. Enter the URL of the webpage we are scraping from. Then click the “Start” button to proceed.
Sample URL: https://www.aliexpress.com/w/wholesale-pillow-decor-home.html?spm=a2g0o.home.100000001.2.650c2145tkm2Bo
(If this link goes invalid, just use another product listing link in Aliexpress)
As the page renders in the Octoparse, find the Tips Panel on the upper right and click “Auto-detect web page data” to proceed with auto-detection. Auto-detection is a feature that can help you detect and select valuable data from the page. You don’t even do the points and click, Octoparse offers options for you.
As the detection completes, a data preview box will pop up where you can check what data you are getting from the current set. Click “Switch auto-detect results” to pick across different options. Click “Create workflow” to confirm and create a task.
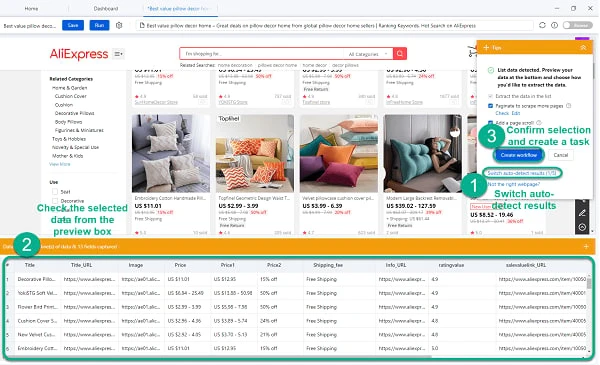
That’s it! You have now built your Aliexpress scraper!
#Step 2: Edit the task
In this step, we will check the pagination and amend the Xpath if necessary. What’s pagination? Well, it is a setting to let the scraper click through pages so whenever it finishes scraping the current page, it will click on the next page and continue the scraping.
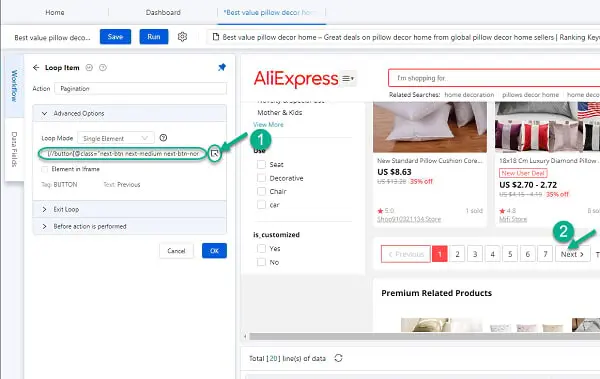
1)Check the workflow created by Octoparse on the left and click the “Pagination” loop. Scroll down the page on the built-in browser to see where the “Next” button lies so that we can see if the scrape has selected the right button to turn pages.
2)The picture shows that the scraper has selected the “Previous” button(in the red rectangle) instead of “Next”. Clicking Previous is not a way to turn pages, robot. Let’s correct it.
3)Double click the Pagination loop and you will reach out to the settings interface. In the bar there is a line of code, that’s auto-created Xpath to locate the “Next” button. How do I amend it?
Click the little arrow on it’s right, and click the “Next” button in the browser. Yes, you are telling the robot, hey this is the button I want to click. Fairly simple, right?
4)The last move in the step is to set automatic scrolls. This will make sure the page gets completely loaded before the actual scraping takes place. Just a few clicks will do!
5)Go back to the workflow and double click “Go to Web Page”, go to “after loading page” and check “scroll down the page after it is loaded”, set a 50 scroll-down with a half-second between 2 scrolls.
Congratulations. You have now successfully configured a scraper!
#Step 3: Run the task
Just click the “Run” button on the above and run the task on your device. You will get thousands of data lines in a few minutes. That’s the speed of Octoparse! Once you get a hang of this, you must regret wasting time on manual jobs getting web data in the early days.
This is the data Octoparse got for me in 5 minutes. In fact, it scrapes not only all the image URLs, but also the according product details. This could be extremely helpful for people who are doing product research and eCommerce analysis.
Bulk download images in seconds
With all image URLs in an Excel file, what you need now is a bulk download tool. I would recommend using the Chrome extension: Tab Save.
Copy and paste the image URLs into Tab Save and click to download, all images will be saved on your computer in seconds.
The whole process may take just 10 minutes and you will get thousands of images (even product details accordingly) from Aliexpress. Come on, this is definitely worth a try!
Takeaway
- Octoparse is a web scraping tool that offers a free plan for users. It is particularly designed for no-code use. The best tool to start your web scraping project from scratch!
- You can use the auto-detection feature in Octoparse to get data from any website. This will free you from confusing scraper building steps that you are very likely facing in other tools.
- You don’t need to write code to amend the path! Point and click is the most friendly way for you to teach the robot what to do.
- “How long will it take to scrape 2000+ image URLs?”
“5 Minutes.”




