Manually saving images one by one is not an option when you need hundreds. Right-clicking works for a single product shot. It does not work when you need every image from a 50-page catalog, an e-commerce site with infinite scroll, or a competitor’s entire gallery.
An image scraper solves this. It crawls pages, identifies image files, and downloads them in bulk, with or without metadata attached.
This guide covers six methods, from zero-setup online tools to Python scripts, so you can pick the right one for your technical level and the scale of the job.
Quick Comparison: Which Image Scraper Fits Your Situation?
| Tool / Method | Best for | Coding required | Handles dynamic pages | Free option |
| Octoparse Online Image Extractor | Quick one-off tasks, no signup | No | Partial | Yes |
| Octoparse Desktop Scraper | Large-scale, scheduled, multi-page | No | Yes | Yes (limited but enough for daily use) |
| Octoparse MCP | AI workflow integration | No | Yes | Yes (2,000 export records per week, applicable to any cloud-based templates) |
| Browser extensions (Chrome / Firefox) | Single-page, fast grab | No | No | Yes |
| Online tools (Image Cyborg, extract.pics) | No-install, small jobs | No | No | Yes |
| Python (BeautifulSoup + Requests) | Custom, developer-controlled | Yes | With Selenium | Yes |
What Is an Image Scraper?
An image scraper is a tool or script that automatically accesses web pages, locates image files in the HTML source, and downloads them in bulk. Unlike a basic image downloader, a scraper can also pull metadata such as alt text, file names, image dimensions, and source URLs alongside the images themselves.
Image scraper vs. image downloader: what is the difference?
| Feature | Image Scraper | Image Downloader |
| Function | Extracts images and metadata (URLs, alt text, dimensions) across pages | Downloads image files, typically one page at a time |
| Automation | Built for batch scraping across multiple pages or entire sites | Generally manual, one-click downloads |
| Dynamic content | Can handle JavaScript-rendered content with the right tool | Usually limited to images visible in page source |
| Use cases | Building image datasets, SEO analysis, e-commerce research, AI training data | Personal use, saving individual files |
If you only need to save one image from a single page, a downloader is fine. If you need batch downloads, cross-page scraping, or image metadata, you need a scraper like Octoparse.
👉 Get Octoparse today! | Try Octoparse for free!
Why Scraping Images Is Harder Than It Looks
Most websites make bulk image downloading harder than it looks. Three issues trip people up consistently, and knowing them upfront saves a lot of wasted time.
Dynamic loading (lazy load and infinite scroll)
Modern sites load images as you scroll, using a technique called lazy loading: images outside the visible viewport are not fetched until the user reaches them. Virtually every major e-commerce, social, and media site uses it today. A scraper that only reads the initial HTML will miss the majority of images on the page.
Pagination across dozens of pages
Product catalogs and image galleries rarely fit on one page. Scraping a 30-page catalog manually means repeating the same process 30 times. An automated scraper with pagination support handles this in a single run.
Thumbnail URLs vs. original-resolution URLs
Many sites serve scaled-down thumbnails in the page source and only load the full-size file on user interaction. Scraping the raw HTML returns the thumbnail URL, not the high-resolution original. The URL pattern often gives it away. For instance, on Amazon, replacing SL160 with SL2000 in the image URL returns the full-resolution version. On Pinterest, changing 236x to originals in the URL path does the same.
Understanding these three obstacles will help you pick the right tool in the next section.
6 Methods to Scrape Images from Any Website For Free
Evaluation Criteria of Image Scrapers
| Evaluation criterion | Why it matters |
| Dynamic page handling | Most modern sites use lazy loading or infinite scroll. A tool that only reads static HTML will miss the majority of images on typical e-commerce and social pages. |
| Pagination support | Scraping stops being useful once you have to manually repeat it across 20+ pages. We checked whether each tool can follow next-page links automatically. |
| Metadata alongside images | Downloading file blobs is only half the job. We checked whether each tool can return alt text, image dimensions, source URLs, and accompanying structured data in the same run. |
| Setup time | We timed actual first-use setup for each tool, from zero to first successful image download, including account creation and configuration steps. |
| Output control | Can you filter by size, select specific images, or choose output format? Tools with no filtering return hundreds of icons and thumbnails that require manual cleanup. |
To make this comparison useful rather than promotional, we evaluated each tool against the same five criteria before writing a single word. With those criteria in place, here is what we found:
1. Octoparse Online Image Extractor (Recommended)
The Octoparse Online Image Extractor is the fastest entry point for anyone who needs a quick result without installing software or creating an account. Paste a URL, and it returns every image it can find on that page within seconds.
📑Our take on Online Image Extractor: In our hands-on test, the tool handles standard static pages well and returns image URLs alongside download options, with results appearing in under two seconds of pasting a URL. On pages with heavy JavaScript rendering, infinite scroll, or login-protected content, coverage is limited, since the tool works from a page snapshot rather than simulating full browser interaction.
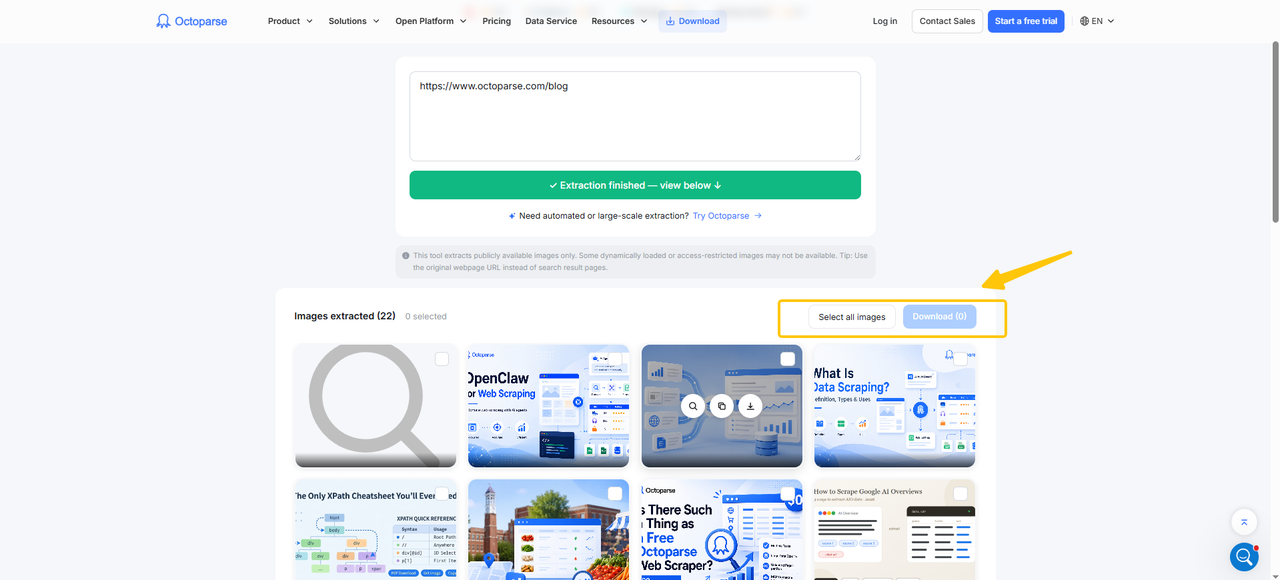
Octoparse Online Image Extractor at a Glance
| Dimension | Detail |
| Best for | One-off tasks, quick validation, users who want zero setup |
| Pros | No signup required, results in under a minute, clean interface |
| Cons | No multi-page support, login-protected content, limited on dynamic or JavaScript-heavy sites |
| Free option | Yes, fully free |
| What users say | Users consistently mention the zero-friction entry point as the main draw. The most common complaint is that the tool misses images on JavaScript-heavy pages, which is expected given how it works. |
2. Octoparse Desktop Scraper (Recommended)
For batch scraping across multiple pages, scheduled runs, or any site with dynamic content, Octoparse is the most complete no-code option. It can use a built-in browser that renders JavaScript, simulates scrolling, and waits for content to fully load before extracting data.
📑Our take on Octoparse Desktop: We tested it across five different site types: paginated catalogs, infinite-scroll galleries, product pages with carousel images, sites with lazy loading, and multi-domain image searches. In every case, it returned both image URLs and accompanying metadata.
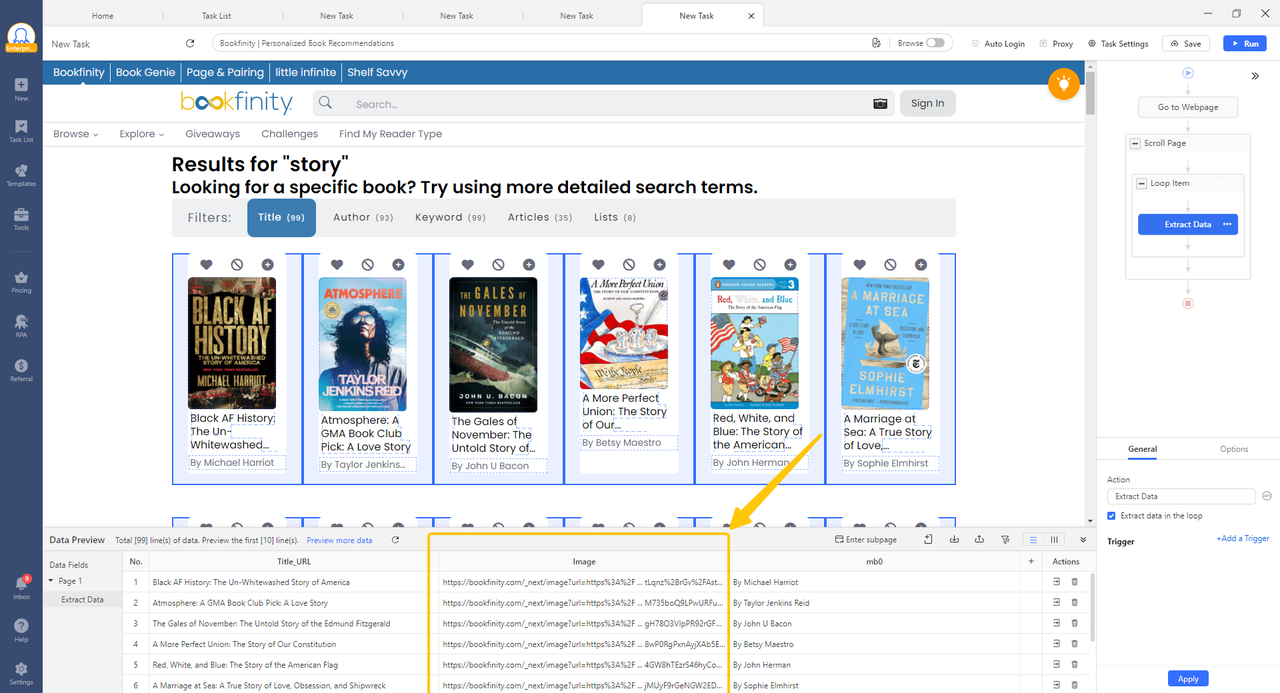
What Octoparse Handles That Most Tools Cannot
| Capability | How it works |
| Paginated sites | Octoparse handles various pagination types: next-page buttons, page number navigation, “Load More” buttons, infinite scroll, and more. Add the matching pagination action and it follows pages automatically to the end. |
| Image metadata + structured data | All publicly shown data including alt text, product name, price, and category alongside image URLs can be extracted in a single run. |
| High-resolution image URLs | Inspect available fields after pointing the scraper at an image element and select the full-resolution URL instead of the thumbnail. |
| Bulk file download | Downloads image files directly to your device, not just URLs; see how to scrape and download files from websites. |
| Carousel images | Captures all images in rotating carousels; see how to build an image crawler without coding for the full walkthrough. |
| Anti-bot protection | Octoparse handles IP rotation and automatic CAPTCHA solving built-in, so batch image requests on e-commerce and media sites do not trigger blocks. Available on paid plans. |
| Scheduled cloud scraping | Run image scraping tasks on a schedule without keeping your computer on. Cloud execution runs on Octoparse’s servers daily, weekly, or at any interval you set. Available on paid plans. |
| Flexible export | Export image URLs and metadata directly to Excel, CSV, Google Sheets, or your database. No manual file handling or API setup required. |
Octoparse also has 600+ pre-built scraping templates for popular sites. If your target site is in the library, setup takes under three minutes.
Octoparse Desktop Scraper at a Glance
| Dimension | Detail |
| Best for | Multi-page scraping, dynamic sites, scheduled automation, image + metadata combined |
| Pros | No coding, handles JavaScript and infinite scroll, 600+ templates, cloud execution available |
| Cons | Desktop client is Windows/Mac only; cloud-based operation requires a paid plan |
| Free option | Yes, free plan covers most small-to-medium jobs |
| What users say | Across G2 and Trustpilot reviews (May 2026), users consistently highlight the visual point-and-click setup and support responsiveness as the standout strengths. |
👉 Start scraping images for free with Octoparse
Video Tutorial: Bulk Download Thousands of Images
Here is a tutorial that gives a step-by-step guide to help users scrape and download images from AliExpress with Octoparse.
When you get a hang of Octoparse web scraper, you can download images from any website without effort!
3. Octoparse MCP (Recommended)
MCP (Model Context Protocol) is an open standard that lets AI models call external tools directly. If you are building a workflow that feeds scraped images into an AI system, such as Claude, ChatGPT, or a custom LLM pipeline, Octoparse MCP connects the scraper directly to your AI tools without manual export steps.
📑Our take on Octoparse MCP: With Octoparse MCP connected, you can instruct an AI assistant to trigger scraping tasks using Octoparse’s cloud templates, retrieve structured metadata, and pass the output to a downstream model or storage system in a single automated step. You can try this by describing your scraping requirements in plain English. It will start work by calling existing templates or custom tasks you have set up in Octoparse. It does not support ad-hoc scraping of arbitrary URLs without a corresponding task in place.
📑See these articles for a guide on step-by-step setup and use cases:
1. Connect Octoparse MCP to ChatGPT for web scraping
2. Cursor AI Extracts Web Data Using Octoparse MCP
3. Use Claude Scrape Websites with Octoparse MCP
4. Octoparse MCP Scraping Use Case
Octoparse MCP at a Glance
| Dimension | Detail |
| Best for | AI training dataset pipelines, automated image collection inside LLM environments; totally let AI do the things for you. |
| Pros | No manual export, triggers scraping directly from AI chat, integrates with Claude, ChatGPT, Cursor, and Gemini CLI |
| Cons | Requires MCP client setup; not designed for ad-hoc one-off downloads; only cloud-executable templates work via MCP |
| Free option | Yes. New users get 2,000 export records per week. That free quota also unlocks all cloud-based templates in Octoparse, including paid ones, so you can run any cloud-based template via MCP without upgrading first. |
| What users say | A content researcher at a media startup used Octoparse MCP with Claude to run weekly competitor monitoring. Each Monday, they typed a plain English prompt describing the sites and fields they needed. Claude picked the right template and returned a structured table directly in the conversation, without switching tabs or exporting files. |
4. Browser Extensions (Chrome and Firefox)
Browser extensions are the fastest option for grabbing all images from a single page without installing additional software. They work directly inside your browser with no configuration required.
For Chrome and Edge: Imageye (Recommended)
Imageye is currently the most actively maintained bulk image downloader for Chrome, rated 4.9 stars on the Chrome Web Store (Source: Chrome Web Store, May 2026). It displays all detected images in a visual grid before you download anything, which means you can deselect icons, logos, and thumbnails before they hit your downloads folder. To get started:
- Install Imageye from the Chrome Web Store.
- Open the target page and click the Imageye icon in the toolbar.
- Use the width/height filter to set a minimum image size, which filters out icons and UI elements automatically.
- Select all or specific images from the preview grid and click Download.
📑Our take on Imageye: The size filter and visual preview are the features that separate it from simpler extensions. On a typical product page, setting a minimum width of 300px cuts noise from icons and decorative elements down to near zero. The main limitation is that, on sites that load images progressively as you scroll, you need to scroll the entire page to the bottom before activating the extension, otherwise you only capture the initially visible images.
Alternative for Chrome: Image Downloader
The classic Image Downloader extension has been around longer and is slightly lighter. It lacks Imageye’s visual grid preview but has a reliable filter system. Worth keeping as a backup if Imageye does not detect images on a specific site.
For Firefox: Built-in Media Viewer (No Extension Needed)
Firefox has a native option that requires no extension:
- Open the target page in Firefox.
- Right-click on a blank area and select “View Page Info.”
- Click the “Media” tab. This lists every image, video, and media file on the page.
- Select all items, then click “Save As” to download them.
📖 Note on Imageye for Firefox: A Firefox version of Imageye exists, but it has not received updates at the same pace as the Chrome version. For Firefox users who want Imageye-style filtering and preview, the Chrome version in a Chrome-based browser is the more reliable choice in 2026.
Browser Extensions at a Glance
| Dimension | Detail |
| Best for | Single-page, quick grabs; users who do not want to leave their browser |
| Pros | Imageye’s visual grid and size filter remove the need for manual cleanup; instant results with no setup beyond the extension |
| Cons | Cannot follow pagination; only captures images already loaded when activated; requires full-page scroll before activation on infinite-scroll sites; some sites block extensions via Content Security Policy headers |
| Free option | Yes, both Imageye and Image Downloader are free |
| What users say | Imageye Chrome reviews describe it as “absolute gold” for auto-categorizing downloaded images into folders. The most frequent complaint is inconsistent detection on JavaScript-heavy pages, which is a limitation of the extension’s access model rather than a bug. |
5. Online Tools: Image Cyborg and extract.pics
For users who do not want to install anything at all, two online tools cover basic single-page scraping directly from a web interface.
Image Cyborg
Paste a URL and download a ZIP of all found images. Simple and fast, though the results include logos and avatars alongside content images, and all ZIP files share the same default filename, requiring manual renaming.
extract.pics
Offers a preview before downloading, so you can deselect icons and irrelevant images before saving. The bulk download button is unreliable on image-heavy pages; batching the download in groups of 20-30 is more consistent.
Online Tools at a Glance
| Dimension | Detail |
| Best for | One-off downloads from static pages, users who want zero installation |
| Pros | No signup, no install, extract.pics has useful preview before download |
| Cons | No JavaScript rendering, no pagination, no metadata, output needs cleanup |
| Free option | Yes, both tools are free |
| What users say | extract.pics gets consistent praise for the preview-before-download flow. Image Cyborg is seen as more of a fire-and-forget option: faster, but with less control over what ends up in the ZIP. |
6. Python with BeautifulSoup (Full Developer Control)
For developers who need complete control, Python with BeautifulSoup and Requests is the most flexible approach. It is free, runs on any platform, and integrates directly into existing codebases.
When Python Makes Sense over a No-Code Tool
Use Python when you need custom output formatting, want to process images programmatically immediately after download, or are embedding scraping into a larger data pipeline. For pages with JavaScript rendering, add Selenium or Playwright alongside BeautifulSoup. According to BeautifulSoup documentation, Requests + BeautifulSoup alone cannot execute JavaScript.
Script to Scrape Images from a Website
How it works: The script fetches the page HTML, parses all <img> tags, extracts the src attribute, and downloads each file to a local folder. Relative URLs are converted to absolute URLs before downloading.
📑Our take on Python with BeautifulSoup: Many sites block requests that do not include a realistic User-Agent header. The script above includes this header by default. If you still get 403 errors, the site may require cookies or session tokens, in which case Selenium is the more reliable path.
For dynamic pages: Replace requests.get() with a Selenium or Playwright call that fully renders the page before passing the HTML to BeautifulSoup. This adds setup time but handles virtually any modern site structure.
Python with BeautifulSoup at a Glance
| Dimension | Detail |
| Best for | Developers with custom pipeline requirements, processing images programmatically after download |
| Pros | Full control, free, integrates into any codebase, handles any output format |
| Cons | Requires coding, breaks when site HTML structure changes, dynamic pages need Selenium or Playwright |
| Free option | Yes, fully free |
Which Image Scraper Should You Use?
| Your situation | Recommended approach |
| Single page, need results fast, no install | Octoparse Online Image Extractor or other browser extensions |
| Single page, want to preview before downloading | extract.pics |
| Multiple pages or pagination | Octoparse Desktop |
| Infinite scroll or JavaScript-heavy site | Octoparse Desktop |
| Images + metadata (price, alt text, dimensions) together | Octoparse Desktop |
| Feeding scraped images into an AI/LLM pipeline; want to let AI totally do the things for you | Octoparse MCP |
| Custom code, full developer control | Python + BeautifulSoup (static) or + Selenium (dynamic) |
| Recurring automated scraping on a schedule | Octoparse Desktop (paid cloud plan) |
The right choice depends on three questions (ask yourself before you choose): how many pages you need to scrape, how dynamic the target site is, and whether you need metadata alongside the images.
One pattern worth noting is that teams often start with a browser extension or online tool for a one-off job, then switch to Octoparse once the job recurs or the target site has pagination. The two are not mutually exclusive. Use the quick tool when the job is small, and move to the full scraper like Octoparse when scale or automation matters.
How People Actually Use Image Scrapers: 3 Common Workflows
E-commerce Product Catalog Monitoring
Retailers scrape competitor product images to track visual merchandising changes, identify new SKUs, and build comparison databases. The typical setup combines Octoparse’s structured scraping (image URL, product name, price, category in a single run) with scheduled automation, so the database updates weekly without manual intervention.
A Japan-based real estate technology company took a similar approach with property listing data. Before using Octoparse, their team collected data manually in limited volume. After building automated scraping tasks, monthly data collection grew to approximately 1 million records, and the structured output directly powered their SaaS product’s search and comparison features.
AI Training Dataset Collection
Demand for labeled image datasets has grown alongside the expansion of vision AI models. Web scraping is one of the primary methods teams use to assemble training data at scale. Octoparse’s HTML and metadata scraping has seen sharply rising usage over the past year, with usage patterns pointing toward users building AI training pipelines rather than conducting standard business intelligence work. Teams connecting Octoparse via MCP can trigger scraping jobs directly from within their model environment, removing the manual export and re-import step.
Content Aggregation at Scale
A US-based digital publisher needed to scale up event listings without adding headcount. Their team was manually collecting around 450 local event listings per month. After setting up an Octoparse scraping workflow, that number reached approximately 4,500 per month, a 10x increase, with the same team size. The same logic applies to image-heavy content: scraping press photos, product imagery, or event visuals from public sources at volume is a job a single automated task can replace.
Conclusion
The right image scraper comes down to scale and technical setup. For a single page, the Octoparse Online Image Extractor or a browser extension delivers results in under a minute. For multi-page or dynamic sites, Octoparse desktop handles pagination, infinite scroll, and metadata without any code. For developers who need full pipeline control, Python with BeautifulSoup covers static pages, and adding Selenium handles dynamic rendering.
If you are building an AI pipeline that feeds scraped images into a model, Octoparse MCP removes the manual export step by connecting the scraper directly to your AI environment.
FAQ about Image Scraper Tools
- What is the best free image scraper?
For zero-setup free scraping, the Octoparse Online Image Extractor handles static pages without requiring an account. For multi-page or dynamic sites, the Octoparse desktop covers most small-to-medium jobs. Browser extensions like Image Downloader for Chrome are also free and work well for single-page grabs. Python with BeautifulSoup is free and fully customizable for developers.
- How do I scrape images from websites with infinite scroll or lazy loading?
Infinite scroll and lazy loading require a scraper with a built-in browser that simulates user scrolling before extracting content. In Octoparse, configure the task to scroll to the bottom of the page before data extraction begins. The built-in browser renders JavaScript and waits for images to load with each scroll event before capturing the full result set. Browser extensions and basic Python scripts using Requests cannot handle this without adding Selenium or Playwright to simulate browser behavior.
- Can I bulk download images from a URL list?
Yes. If you already have a list of image URLs and need to download the files in bulk, see how to download images from a URL list for a step-by-step guide. For generating the URL list from a site first, the Octoparse desktop scraper or the online image extractor produces that list as part of the scraping step. You can also use dedicated tools covered in how to bulk download images from links once you have the list.
- How do I get high-resolution images instead of thumbnails?
Look at the URL structure in the page source. Full-resolution images typically have URLs containing terms like large, original, full, or high-resolution dimensions such as 2048x2048. Thumbnails often include thumb, small, or low-dimension indicators. On Amazon product pages, replacing SL160 with SL2000 in the URL returns the larger version. On Pinterest, changing 236x to originals in the URL path gives full-size images. In Octoparse, inspect the available fields after pointing the scraper at an image element and select the field returning the full-resolution URL.
- Is it legal to scrape images from websites?
Scraping legality depends on the site’s terms of service, intended use, and jurisdiction. Publicly available images may be scraped for personal research or analysis in many cases, but reproducing, redistributing, or using scraped images commercially may infringe copyright. Always review the site’s robots.txt file and terms of service before scraping. For commercial use cases, consult a legal professional.
- Can I download product images and match them to the same data row in Excel?
Yes. Octoparse exports image URLs alongside product data into Excel. To embed the actual images into the matching rows, use Kutools for Excel to insert images from URLs automatically. See the full walkthrough in the Octoparse Help Center. Note: Kutools is Windows-only. Mac users can use TabSave instead.