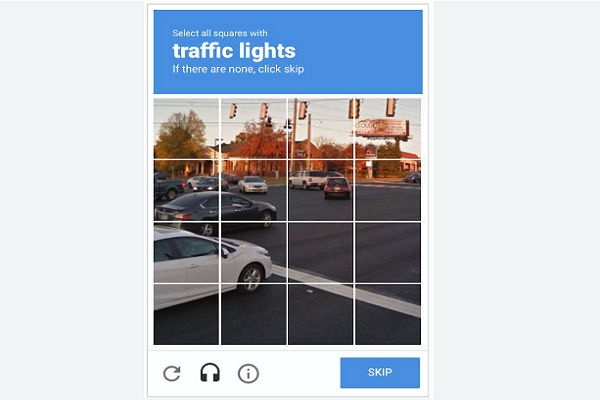
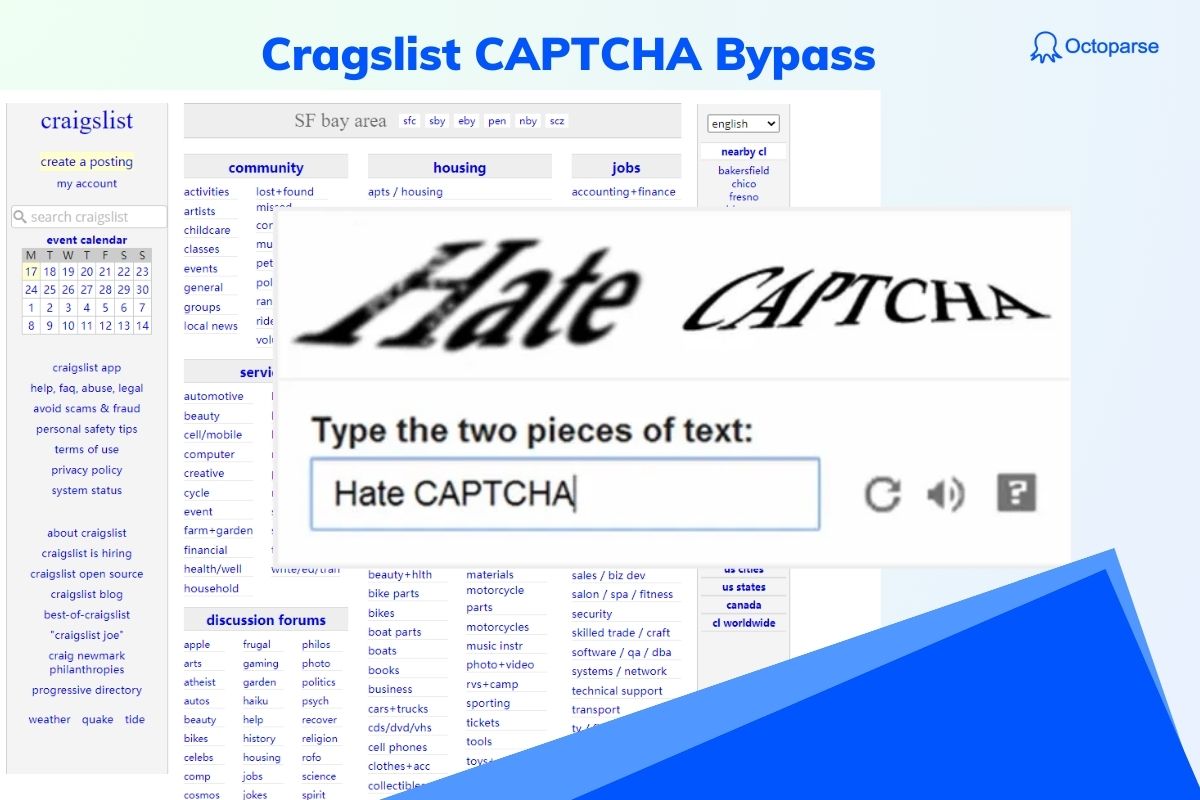
Bypassing CAPTCHA challenges is a crucial task for anyone involved in web scraping, as it ensures smooth data collection without interruptions. Many websites, including e-commerce giants like Amazon, often use CAPTCHA mechanisms to protect their content from bots.
Fortunately, there are several tools available to bypass CAPTCHA, ranging from automated scraping tools to Python libraries and browser extensions.
In this article, we’ll explore 10 recommended tools that can help you bypass CAPTCHA easily and streamline your web scraping process.
Why Bypass CAPTCHA in Web Scraping
It is an essential part of web scraping to solve CAPTCHA, especially when dealing with websites that implement these security mechanisms to block bots and automated data extraction. Here’s why bypassing CAPTCHA is critical for web scraping:
Faster Data Collection
CAPTCHA slows down scraping, requiring manual intervention and causing delays. Bypassing it allows for faster, automated data extraction.
Keep Your Scraping Automated
CAPTCHA interrupts the automated nature of web scraping. Bypassing it ensures continuous, hands-free data collection.
Handle Large Scale Scraping
When scraping large datasets, handling CAPTCHA manually becomes impractical. Bypassing it enables scalable scraping operations.
Get Real Time Data
CAPTCHA delays data collection, impacting timely decision-making. By bypassing it, you get real-time, uninterrupted access to data.
Avoid IP Blocks
CAPTCHA challenges often lead to IP blocks. Bypassing it helps maintain a smooth scraping process without risking blocks.
Bypassing CAPTCHA ensures faster, scalable, and more efficient data extraction, helping businesses stay ahead in competitive markets.
10 Tools to Bypass CAPTCHA for Web Scraping
1. Octoparse
Octoparse is a powerful, user-friendly web scraping tool that automatically handles CAPTCHA challenges, allowing users to extract data from websites protected by CAPTCHA. This tool uses advanced algorithms to bypass CAPTCHAs and prevents scraping disruptions, making it ideal for both beginners and advanced users.
With features like proxy rotation and cloud-based scraping, Octoparse ensures efficient, uninterrupted data extraction, even from CAPTCHA-protected websites like Amazon.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
2. 2Captcha
2Captcha is one of the most popular CAPTCHA-solving services, leveraging human workers to solve CAPTCHA challenges in real time. It’s a great option to integrate into your scraping process to bypass CAPTCHAs that might stop your bot. When using 2Captcha, you send the CAPTCHA to their platform, and a human worker solves it for you. This service is compatible with most scraping tools, including Octoparse and Python-based methods.
Main Features:
- Real-time CAPTCHA solving by humans.
- Integration with web scraping tools.
- Solves various types of CAPTCHA, including reCAPTCHA and image-based CAPTCHAs.
3. Anti-Captcha
Anti-Captcha is a CAPTCHA-solving service similar to 2Captcha, offering an automated solution to solve CAPTCHAs using both bots and human workers. Anti-Captcha supports reCAPTCHA, FunCaptcha, and other common types. It can be easily integrated into your scraping process, ensuring uninterrupted data extraction even when CAPTCHAs appear.
Main Features:
- Supports multiple CAPTCHA types.
- Integration with various scraping tools.
- Fast response time and reliable service.
4. Selenium with Python
Selenium is a Python-based browser automation tool that can simulate real user behavior. It’s widely used for bypassing CAPTCHAs because it interacts with the web page just like a human, reducing the chances of being blocked. By integrating Selenium with third-party CAPTCHA-solving services like 2Captcha or Anti-Captcha, you can automate CAPTCHA solving and continue scraping data without interruptions.
Main Features:
- Automates browser actions like clicking, typing, and navigation.
- Integration with CAPTCHA-solving services for automation.
- Suitable for handling dynamic content and CAPTCHA challenges.
5. Bright Data (formerly Luminati)
Bright Data offers a large proxy network with the ability to rotate IP addresses, helping you avoid detection while scraping websites. Bright Data can help bypass CAPTCHAs by mimicking human browsing behavior and using rotating proxies, which reduce the likelihood of being flagged or blocked by websites. This tool is especially helpful for large-scale web scraping tasks.
Main Features:
- Rotating proxy network.
- Real-time data extraction.
- Avoids IP blocking and CAPTCHA detection.
6. DataMiner (Chrome Extension)
DataMiner is a Chrome extension designed to help users scrape data from websites without writing code. It has built-in support for bypassing CAPTCHAs, and with proxy management, it helps avoid getting blocked while scraping. DataMiner is ideal for non-technical users and can be used to extract data from a variety of websites, including those protected by CAPTCHAs.
Main Features:
- Point-and-click interface for easy use.
- Supports CAPTCHA bypass with proxy support.
- Can export data to Excel, CSV, or other formats.
7. ProxyMesh
ProxyMesh is a proxy service that allows users to rotate IP addresses while scraping, helping bypass CAPTCHA mechanisms. By using rotating proxies, ProxyMesh ensures that the scraping activity is distributed across multiple IPs, making it harder for websites to detect and block your scraping efforts. It’s a valuable tool for scaling your scraping operations and overcoming CAPTCHA challenges.
Main Features:
- Rotating proxy network for multiple IP addresses.
- Prevents CAPTCHA triggers and IP blocks.
- High scalability for large-scale data extraction.
8. Web Scraper (Chrome Extension)
Web Scraper is another popular Chrome extension for web scraping. It offers users an easy, point-and-click interface for creating sitemaps to scrape websites. To bypass CAPTCHA challenges, Web Scraper can be used in combination with proxy networks and CAPTCHA-solving services. It’s ideal for users looking for a lightweight, easy-to-use tool for scraping.
Main Features:
- Chrome extension for easy setup.
- Supports proxy integration for CAPTCHA bypass.
- Allows exporting data to CSV or JSON.
9. Distill.io (Chrome Extension)
Distill.io is a browser extension that allows for automated web scraping. It includes functionality to solve CAPTCHAs by using proxy networks and CAPTCHA-solving services. It’s particularly useful for monitoring changes on websites and bypassing CAPTCHA challenges during data collection.
Main Features:
- Real-time web scraping and monitoring.
- Integration with CAPTCHA-solving services.
- Supports proxy and IP rotation.
10. Puppeteer (Python Library)
Puppeteer is a powerful headless browser automation tool for scraping, primarily used with Node.js but can be integrated with Pyppeteer (Python version). Puppeteer simulates real user actions, including CAPTCHA solving. When combined with third-party CAPTCHA-solving services, Puppeteer is an excellent solution for bypassing CAPTCHA challenges while scraping.
Main Features:
- Simulates human-like browsing behavior.
- Supports dynamic content scraping.
- Bypass CAPTCHAs by integrating with CAPTCHA solvers.
How to Break Amazon CAPTCHA in Octoparse While Scraping?
Amazon’s CAPTCHA system which includes text-based, image-based, and interactive CAPTCHAs, along with AWS WAF’s advanced challenges, can stop your scraper instantly.
Octoparse offers a complete solution to handle Amazon CAPTCHA automatically without coding.
Four ways to solve Amazon CAPTCHA
Use Octoparse’s Pre-built Amazon Templates (Quick Method)
- Select Octoparse’s Amazon-specific scraping templates for your needs
- Templates come pre-configured with anti-blocking measures and CAPTCHA handling
- Get fast, efficient setup without manual configuration.
Get started to breaking CAPTCHA today by trying following template!
https://www.octoparse.com/template/amazon-product-scraper-by-keywords
https://www.octoparse.com/template/amazon-reviews-scraper
Add CAPTCHA Solving in your scraping workflow
- Add “Solve CAPTCHA” step during scraper setup
- Handles reCAPTCHA v2 and image CAPTCHAs automatically
- Keeps extraction running when challenges appear
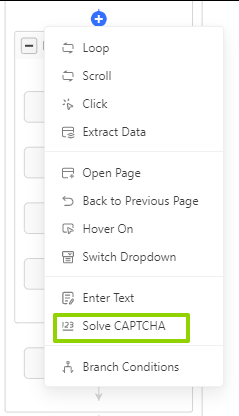
📑For detailed ways to solve various CAPTCHAs, check out our complete guide on how to solve CAPTCHA.
Enable Proxy Rotation
- Configure proxy management in settings
- Automatically rotates IP addresses to avoid detection
- Prevents Amazon from rate-limiting your activities
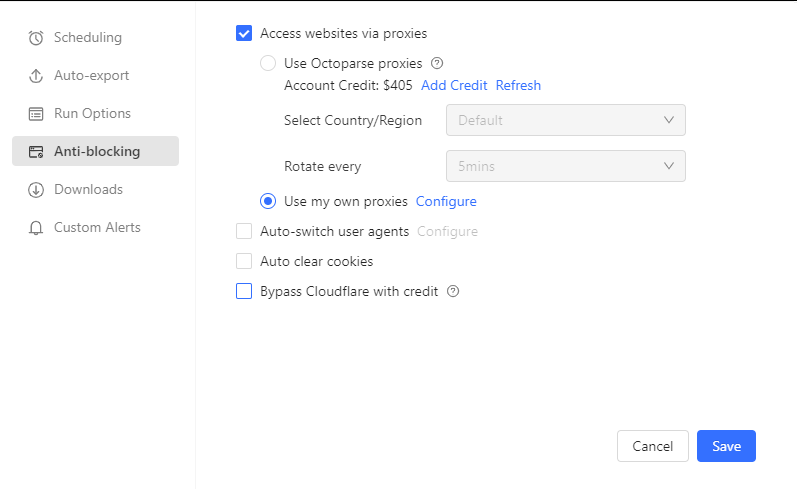
📑Here is a step-by-step guide on how to set up proxy in Octoparse.
Use Cloud-Based Scraping
- Run tasks in Octoparse’s cloud environment
- Bypass local IP restrictions and blocks
- Reduce risk of detection by Amazon’s anti-bot systems
📑For detailed implementation steps and advanced configurations, check out our complete guide on how to bypass Amazon CAPTCHA while scraping.
Final Thoughts
Bypassing CAPTCHA is one of the most important aspects of successful web scraping, especially when dealing with websites like Amazon, which use CAPTCHA mechanisms to prevent automated bots.
From powerful tools like Octoparse to browser extensions and Python libraries, there are multiple methods available to bypass CAPTCHA challenges efficiently.
For a seamless scraping experience, Octoparse offers an automated solution to handle CAPTCHAs without requiring manual intervention, while tools like 2Captcha, Selenium, and ProxyMesh provide added flexibility and control. Choose the tool that best fits your scraping needs and start collecting data without interruptions.
FAQs about CAPTCHA Bypass
1. How do I Disable CAPTCHA Verification?
You can’t directly disable CAPTCHA since it’s controlled by the website, but you can bypass it using CAPTCHA-solving tools or APIs. Common options include:
- 2Captcha – a paid service where real humans solve CAPTCHAs in real time
- Anti-Captcha – an automated service with API integration for reCAPTCHA and hCaptcha
- DeathByCaptcha – affordable, API-based CAPTCHA-solving support
- ImageTyperz – works with various CAPTCHA formats including reCAPTCHA
For non-coders, scraping tools like Octoparse integrate proxy rotation and CAPTCHA-handling features, allowing you to continue data extraction without manually solving CAPTCHAs.
2. How to Get around Invalid CAPTCHA?
Invalid CAPTCHA often happens when the solution doesn’t match or the session expires. To fix it:
- Refresh and retry solving the CAPTCHA
- Clear cookies and cache to reset sessions
- Use scraping tools that automatically handle retries and session management, reducing CAPTCHA errors
3. How to Avoid CAPTCHAs by Improving Request Fingerprinting?
Websites trigger CAPTCHAs when they detect bot-like behavior. To improve request fingerprinting:
- Rotate user-agents and IPs
- Add delays to mimic human browsing patterns
- Use a scraping solution like Octoparse that already optimizes headers, cookies, and IP rotation to appear more human-like
4. What is CAPTCHA?
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a security measure used to distinguish humans from bots. Common types include:
- Image recognition
- Text input puzzles
- reCAPTCHA (Google’s version with checkbox or invisible verification)
5. How to implement Selenium for bypassing reCAPTCHA on websites?
Selenium can be used with third-party CAPTCHA-solving services. General steps:
- Integrate CAPTCHA-solving API with Selenium script
- Capture the CAPTCHA challenge and send it to the solver
- Input the solved token back into the form
This requires coding knowledge, but for non-coders, why not try Octoparse?