What is web scraping/data extraction
Web scraping (Web harvesting or web data extraction) is a computer software technique of extracting information from websites. Usually, such software programs simulate human exploration of the web by either implementing how-level Hypertext Transfer Protocol(HTTP), or embedding a fully-fledged web browser, such as Mozilla Firefox.
Web scraping is closely related to web indexing, which indexes information on the web using a bot or web crawler and is a universal technique adopted by most search engines. In contrast, web scraping focuses more on the transformation of unstructured data on the web, typically in HTML format, into structured data that can be stored and analyzed in a central local database or spreadsheet. Web scraping is also related to web automation, which simulates human browsing using computer software.
Web Scraping Using Java
Java is often thought of as a stuffy enterprise language, while web scraping is the often-murky domain of scripting languages. By combining the robustness and extensibility of Java with the flexibility and power of web scraping, we can create immensely useful tools that can solve very difficult problems.
Here is my sample java code: WebHarvestTest.java
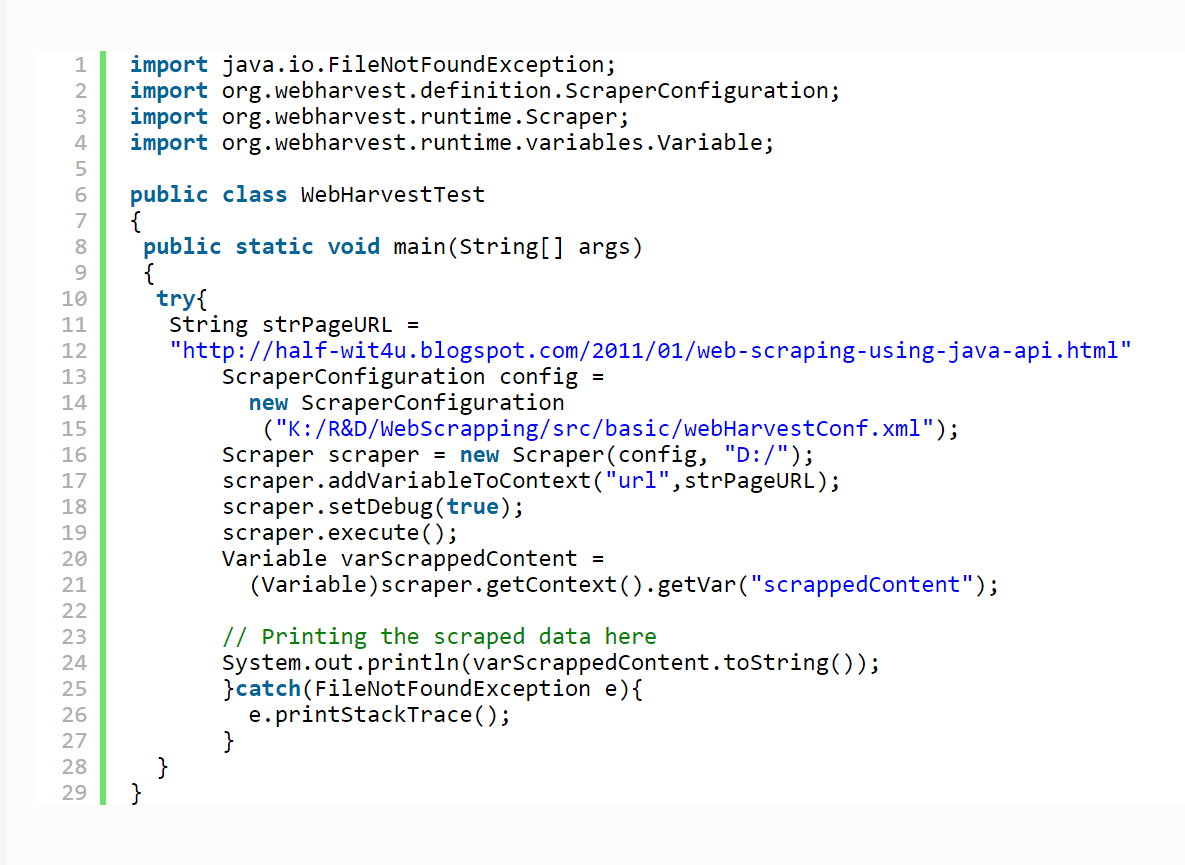
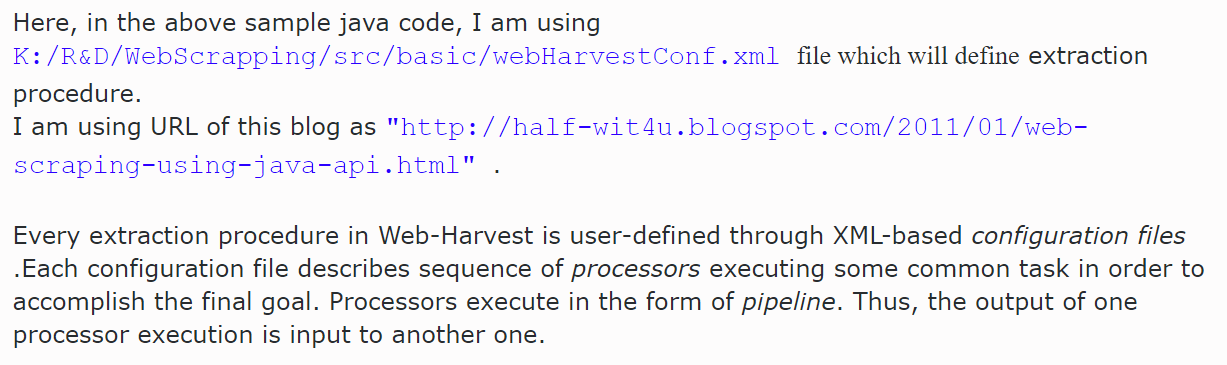
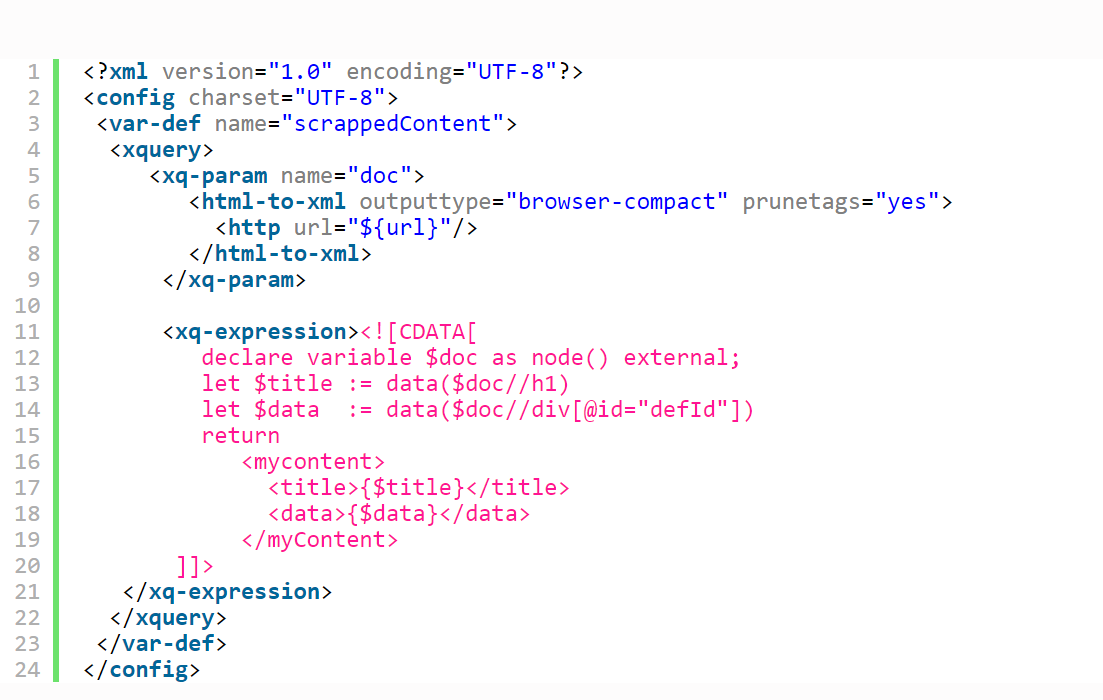
(source from http://scrapingdatafromwebsites.blogspot.hk/2013/05/web-page-scraping-using-java.html)




