As two typical buzzwords related to data science, data mining and data extraction confuse a lot of people. Data mining is often misunderstood as extracting and obtaining data, but it is actually way more complicated than that. In this post, let’s find out the difference between data mining and data extraction.
What is Data Mining
Data mining, also referred to as Knowledge Discovery in Database (KDD), is a technique often used to analyze large data sets with statistical and mathematical methods to find hidden patterns or trends, and derive value from them.
What Can Data Mining Do?
By automating the mining process, data mining tools can sweep through the databases and identify hidden patterns efficiently. For businesses, data mining is often used to discover patterns and relationships in data to help make optimal business decisions.
Use Cases of Data Mining
After data mining became widespread in the 1990s, companies in a wide array of industries – including retail, finance, healthcare, transportation, telecommunication, E-commerce, etc started to use data mining techniques to generate insights from data. Data mining can help segment customers, detect fraud, forecast sales, and many more. Specific uses of data mining include:
Customer segmentation
By mining customer data and identifying the characteristics of target customers, companies can align them into a distinct group and provide special offers that cater to their needs.
Market basket analysis
This is a technique based on a theory that if you buy a certain group of products, you are likely to buy another group of products. One famous example is that when fathers buy diapers for their infants, they tend to buy beers together with the diapers.
Forecasting sales
It may sound similar to market basket analysis, but this time data mining is used for predicting when a customer will buy a product again in the future. For instance, a coach buys a bucket of protein powder that should last 9 months. The store that sold the protein powder would plan to release new protein powder 9 months later so that the coach would buy it again.
Detecting frauds
Data mining aids in building models to detect fraud. By collecting samples of fraudulent and non-fraudulent reports, businesses are empowered to identify which transactions are suspicious.
Discover patterns in manufacturing
In the manufacturing industry, data mining is used to help design systems by uncovering the relationships between product architecture, portfolio, and customer needs. It can also predict future product development time span and costs.
Above are just a few scenarios in that data mining is used. For more use cases, check out Data Mining Applications and Use Cases.
The Overall Steps of Data Mining
Data mining is an intact process of gathering, selecting, cleaning, transforming, and mining the data, in order to evaluate patterns and deliver value in the end.
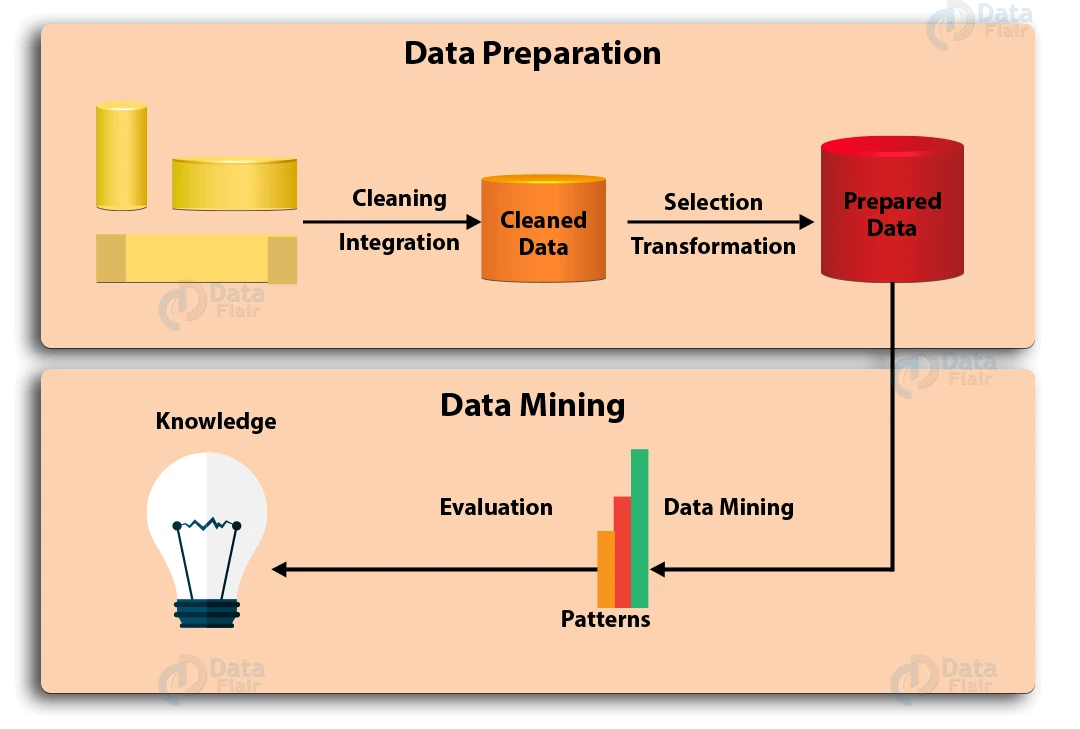
(Source: https://data-flair.training/blogs/data-mining-process/)
Generally, the data mining process can be summarized into 7 steps:
Step 1: Data Cleaning
In the real world, data is not always cleaned and structured. It is often noisy, incomplete, and may contain errors. To make sure the data mining result is accurate, data needs to be cleaned first. Some cleaning techniques include filling in the missing values, automatic and manual inspection, etc.
Step 2: Data Integration
This is the step where data from different sources is extracted, combined, and integrated. These sources can be databases, text files, spreadsheets, documents, data cubes, the Internet, and so on.
Step 3: Data Selection
Usually, not all data integrated is needed for data mining. Data selection is where only useful data is selected and retrieved from the large database.
Step 4: Data Transformation
After data is selected, it is transformed into suitable forms for mining. This process involves normalization, aggregation, generalization, etc.
Step 5: Data Mining
Here comes the most important part of data mining – using intelligent methods to find patterns in data. The data mining process includes regression, classification, prediction, clustering, association learning, and many more.
Step 6: Pattern Evaluation
This step aims at identifying potentially useful and easy to understand patterns, as well as patterns that validate hypotheses.
Step 7: Knowledge Representation
In the final step, the information mined is presented with knowledge representation and visualization techniques in an appealing way.
Disadvantages of Data Mining
Though data mining is useful, it has some limitations.
High investments in time and labor
Because it is a long and complicated process, it needs extensive work from high-performance and skilled staff. Data mining specialists can take advantage of powerful data mining tools, yet they require specialists to prepare the data and understand the output. As a result, it may still take some time to process all the information.
Privacy & data safety issues
As data mining gathers customers’ info with market-based techniques, it may violate the privacy of users. Also, hackers may hack the data stored in mining systems, which poses a threat to customer data security. If the data stolen is misused, it can easily harm others.
Above is a brief introduction to data mining. As I’ve mentioned, data mining contains the process of data gathering and data integration, which includes the process of data extraction. In this case, it is safe to say data extraction can be a part of the long process of data mining.
What is Data Extraction
Also known as “web data extraction” and “web scraping”, data extraction is the act of retrieving data from (usually unstructured or poorly structured) data sources into centralized locations for storage or further processing.
Specifically, unstructured data sources include web pages, emails, documents, PDFs, scanned text, mainframe reports, spool files, classifieds, etc. The centralized locations may be on-site, cloud-based, or a hybrid of the two. It is important to keep in mind that data extraction doesn’t include the processing or analysis that may take place later.
What Can Data Extraction Do?
In general, the goals of data extraction fall into 3 categories.
Archival
Data extraction can convert data from physical formats (such as books, newspapers, and invoices) into digital formats (such as databases) for safekeeping or as a backup.
Transfer the format of data
If you want to transfer the data from your current website into a new website that is under development, you can collect data from your own website by extracting it.
Data analysis
As the most common goal, the extracted data can be further analyzed to generate insights. This may sound similar to the data analysis process in data mining, but note that data analysis is the goal of data extraction, not part of its process. What’s more, the data is analyzed differently. One example is that e-store owners extract product details from eCommerce websites like Amazon to monitor competitors’ strategies in real-time.
Just like data mining, data extraction is an automated process that comes with lots of benefits. In the past, people used to copy and paste data manually from one place to another to move data, which is extremely time-consuming. Data extraction speeds up the collecting, and largely increases the accuracy of data extracted. For other advantages of data extraction, you may view Why Does Web Scraping Matter article.
Use Cases of Data Extraction
Similar to data mining, data extraction has been widely used in multiple industries serving different purposes. Besides monitoring prices in eCommerce, data extraction can help in individual paper research, news aggregation, marketing, real estate, travel and tourism, consulting, finance, and many more.
Lead generation
Companies can extract data from directories like Crunchbase, Yellowpages and generate leads for business development.
Content & news aggregation
Content aggregation websites can get regular data feeds from multiple sources and keep their sites fresh and up-to-date.
Sentiment analysis
After extracting the online reviews/comments/feedback from social media websites like Instagram and Twitter, people can analyze the underlying attitudes and get an idea of how they are perceiving a brand, product or phenomenon.
The Overall Steps of Data Extraction
Data extraction is the first step of ETL (extract, transform, and load) and ELT (extract, load, and transform). ETL and ELT are themselves part of a complete data integration strategy. In other words, data extraction can be part of data mining.
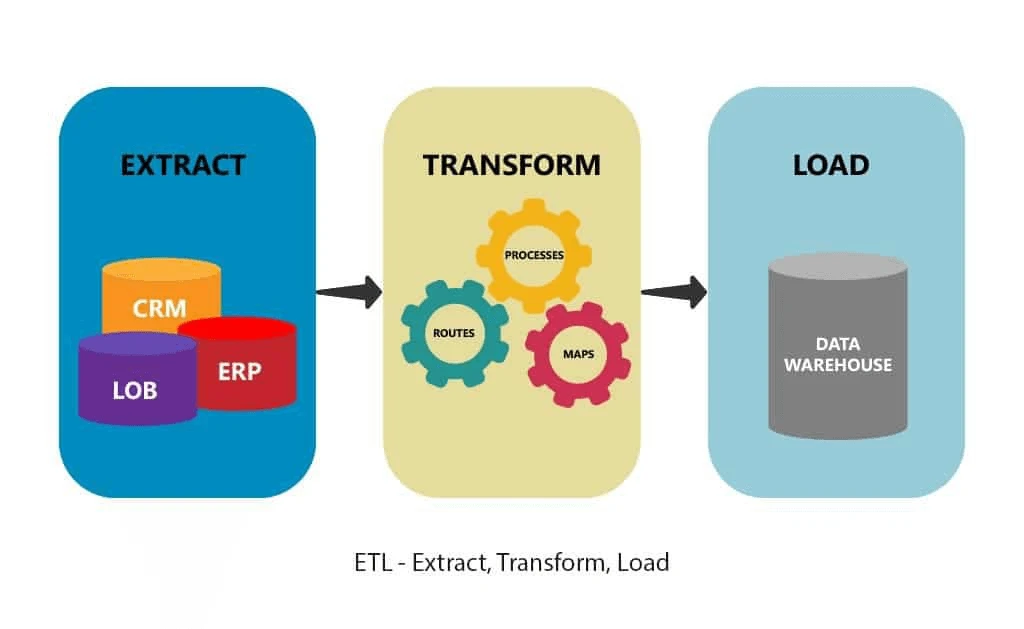
(Source: https://www.astera.com/type/blog/etl-process-and-steps/)
While data mining is all about gaining actionable insights from large data sets, data extraction is a much shorter and straightforward process. The data extraction process can be summarized into three steps.
Step 1: Select a data source
Choose the target data source you want to extract, such as a website.
Step 2: Data Collection
Send a “GET” query to the website and parse the HTML document of it with programming languages like Python, PHP, R, Ruby, etc.
Step 3: Data Storage
Store the data in your on-site database or a cloud-based destination for future use.
If you are an experienced programmer who wants to extract data, the above steps may sound easy to you. However, if you are a non-coder, there is a shortcut – using data extraction tools like Octoparse. Data extraction tools, just like data mining tools, are developed to save people energy and make data processing simple for everyone. These tools are not only cost-effective but also beginner-friendly. They allow users to crawl the data within minutes, store it in the cloud, and export it into many formats such as Excel, CSV, HTML, JSON, or on-site databases via APIs.
Disadvantages of Data Extraction
Server breakdown
When extracting data at a large scale, the webserver of the target website may overload and this could lead to a server breakdown, which harms the interest of the site owner.
IP banning
When one is crawling data too frequently, websites can block his/her IP address. It may totally ban the IP or restrict the crawler’s access to break down the extraction. To extract data without getting blocked, people need to extract data at a moderate speed and adopt some anti-blocking methods.
Legal issues
Web data extraction is in a grey area when it comes to legality. Big sites like Linkedin and Facebook state clearly in their Terms of Service that any automated extraction of data is disallowed. There have been many lawsuits between companies over scraping bot activities.
Data Mining Vs Data Extraction: What’re the Differences
1. Data mining is also named knowledge discovery in databases, knowledge extraction, data/pattern analysis, and information harvesting. Data extraction is used interchangeably with web data extraction, web scraping, web crawling, data retrieval, data harvesting, etc.
2. Data mining studies are mostly on structured data, while data extraction usually retrieves data out of unstructured or poorly structured data sources.
3. The goal of data mining is to make available data more useful for generating insights. Data extraction is to collect data and gather them into a place where they can be stored or further processed.
4. Data mining is based on mathematical methods to reveal patterns or trends. Data extraction is based on programming languages or data extraction tools to crawl the data sources.
5. The purpose of data mining is to find facts that are previously unknown or ignored, while data extraction deals with existing information.
6. Data mining is much more complicated and requires large investments in staff training. Data extraction, when conducted with the right tool, can be extremely easy and cost-effective.
These terms have been around for about two decades. Data extraction can be part of data mining where the aim is to collect and integrate data from different sources. Data mining, as a relatively complex process, comes as discovering patterns for making sense of data and predicting the future. Both require different skill sets and expertise, yet the increasing popularity of non-coding data extraction tools and data mining tools greatly enhances productivity and makes people’s lives much easier.
Best Data Extraction Tool Recommended
Octoparse is a modern visual big data extraction freeware for Windows and macOS systems. Both experienced and inexperienced users would find it easy to bulk extract unstructured or semi-structured information from websites and transform the data into a structured one. The Smart mode will extract data in web pages automatically within a very short time. And it’s easier and faster for a newbie to get data from the web by using the point-&-click interface. It allows you to get real-time data through Octoparse API. Their cloud service would be the best choice for big data extraction because of the IP rotation and abundant cloud servers.
It’s very easy to extract data from any website with Octoparse, you can download and sign up for a free account, and then follow the Octoparse user guide to have a try if you have the data extraction needs.