If you saw a bunch of websites suddenly throw “500 Internal Server Error” on November 18, 2025, it was not just you. A major internet outage traced back to Cloudflare caused widespread 500 errors, breaking access to big names like X (formerly Twitter), ChatGPT, Spotify, and more.
A 500 HTTP status code is a generic server-side error. It means something went wrong on the server (or infrastructure) handling your request.
Let’s unpack what “500 internal server error” actually means, why this spike happened, and what this outage tells us about the fragility of the modern web.
Highlights
1. The Cloudflare outage on November 18, 2025 triggered widespread “500 Internal Server Error” messages, breaking access for major websites and millions of users.
2. 500 errors signal server-side failure—usually not your fault—and require infrastructure fixes, not local troubleshooting.
3. I also included 5 methods to identify and fix cloudflare 500 errors in Web scraper
What Is a 500 Internal Server Error, Anyway?
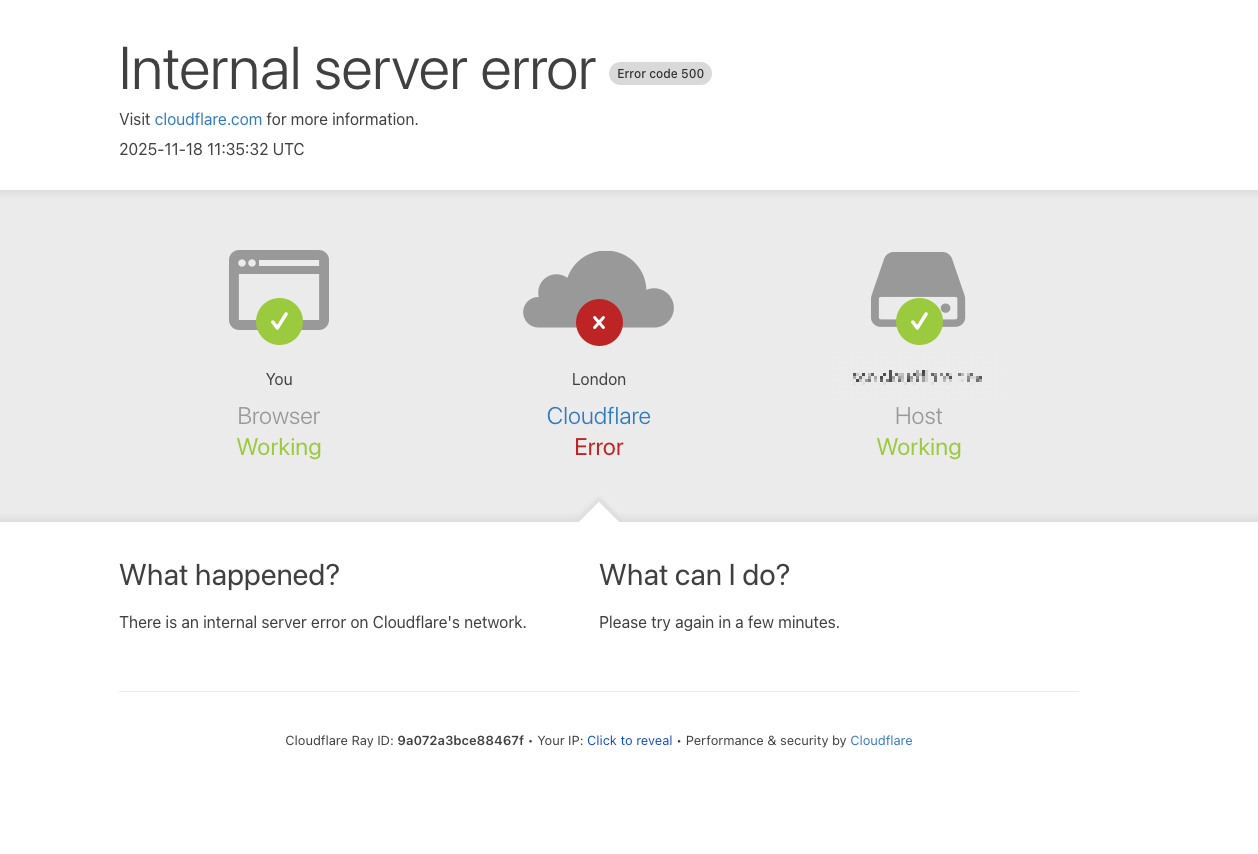
A 500 error almost always signals that the system you’re trying to reach just broke.
It usually lands in your lap at the worst time possible — while checking out, logging in, paying a bill, uploading homework, or sending something important. To you, it looks like:
- A blank white page with “500 Internal Server Error”
- A half-loaded screen + a gray box saying “Something went wrong”
- A popup inside an app that says “server error”
- A browser message that feels like: “It’s not you. It’s us.”
It’s rarely something you did.
Every Type of 500 Error Message (And What Each One Actually Means)
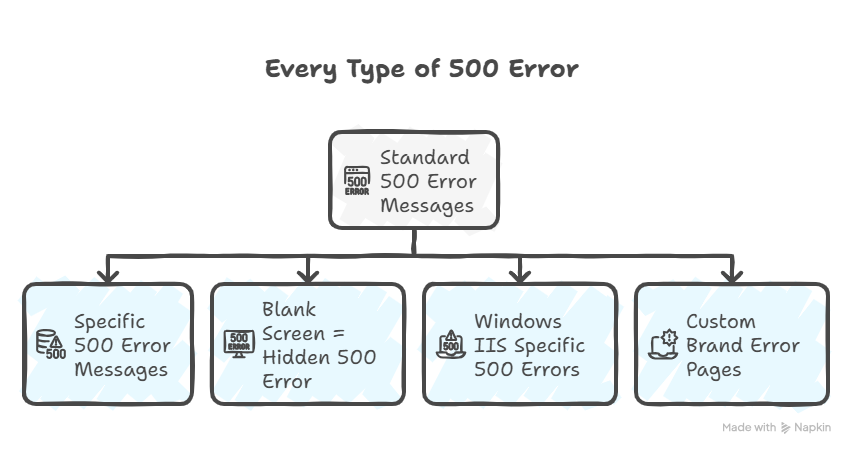
500 errors show up differently depending on your browser, server, and what broke. Here are all the variations you might see – and more importantly, what each one tells you about the problem.
1. Standard 500 Error Messages
“500 Internal Server Error” The most common version. This is the generic message that means “something broke on the server, but we don’t know what.” You’ll see this most often on Apache servers and older websites.
“HTTP 500” or “HTTP Error 500” Same as above, just shorter. Common in browsers like Chrome and Edge. The “HTTP” just means it’s a web server error, not a problem with your internet or computer.
“500 – Internal Server Error” Microsoft IIS servers (Windows-based hosting) show this format. The dash is just their style – it means the exact same thing as the standard 500 error.
“Internal Server Error” The shortest version. Usually shows up in API responses or on minimalist error pages. If you’re scraping and your code receives this text, it’s still a 500 error.
“HTTP 500 – Internal Server Error” Combines both formats. Most common on business websites using IIS servers.
2. Specific 500 Error Messages (These Tell You More)
“500 Internal Server Error. Sorry something went wrong.”
This is a custom error page – the website owner added the apology message. The good news: someone designed this page, which means they’re at least aware that errors happen. The bad news: it doesn’t tell you anything specific about what broke.
“500. That’s an error. There was an error. Please try again later. That’s all we know.”
This is Google’s 500 error message. Yes, even Google goes down sometimes. I saw this during the Cloudflare outage when YouTube broke. If you’re scraping Google services (Shopping, Maps, etc.) and hit this, Google’s infrastructure is having issues – not your scraper.
“The website cannot display the page – HTTP 500.”
Internet Explorer’s version. If you see this, you’re either using a very old browser or testing compatibility. The error itself is standard, just IE’s way of phrasing it.
“Is currently unable to handle this request. HTTP ERROR 500.”
Chrome’s full error message. This actually gives you a small clue: “unable to handle this request” suggests the server is overloaded, not necessarily broken. Could be a traffic spike or resource limit hit.
“The server encountered an internal error or misconfiguration and was unable to complete your request.”
Apache’s detailed version. When you see “misconfiguration,” it often means:
- .htaccess file has syntax errors
- PHP memory limit exceeded
- Module conflict (like mod_security blocking the request)
3. Blank Screen = Hidden 500 Error
Completely blank white page (no text at all) Firefox and Safari sometimes show this instead of an error message. Your browser received a 500 response but the server didn’t send any error page HTML.
If you’re scraping and get blank responses, check the HTTP status code in your logs – it’s probably 500, just with no body content.
How to check: Right-click → Inspect → Network tab → refresh page → look for the status code (it’ll show 500 even if the page is blank)
4. Windows IIS Specific 500 Errors (When You Get More Details)
If the website runs on Windows servers (IIS 7.0 or higher), you might see more specific codes. These are actually helpful because they tell you exactly what broke:
500.0 – Module or ISAPI error occurred
A server extension or module crashed. If you’re scraping, this usually means the site’s backend code hit a fatal error. Wait 5-10 minutes and try again – admins often restart the application pool to fix this.
500.11 – Application is shutting down on the web server
The website is deliberately being shut down, probably for maintenance or updates. Don’t retry immediately – wait at least 15 minutes.
500.12 – Application is busy restarting on the web server
The site is coming back up. This is actually good news if you were seeing other 500 errors. Wait 2-3 minutes and try again.
500.13 – Web server is too busy
Server is overloaded with requests. If you’re scraping, this is your signal to slow down. Reduce your request rate from 1 per second to 1 per 5 seconds.
500.15 – Direct requests for global.asax are not allowed
Very specific – someone tried to access a configuration file directly. You’ll probably never see this unless you’re scraping ASP.NET sites and accidentally requested the wrong URL.
500.19 – Configuration data is invalid
The web.config file (IIS’s version of .htaccess) has errors. This breaks the entire site until an admin fixes it. If you’re scraping, pause your scraper – this could take 30 minutes to several hours to resolve.
500.21 – Module not recognized
A required server module is missing or disabled. Not something you can fix from your end. If scraping, skip this site and try again tomorrow.
500.22 through 500.24
These are all ASP.NET configuration errors. They mean the site’s code is set up for an older server version. Again, not something you can do anything about.
500.50 through 500.53
URL rewrite errors. The site uses mod_rewrite or URL Rewrite module, and it’s misconfigured. Common on sites that recently migrated hosting or changed their URL structure.
500.100 – Internal ASP error
The ASP code itself crashed. This is a programming error in the website’s backend. If you’re scraping and see this consistently on the same URLs, those specific pages have broken code – you might need to exclude them from your scraper.
5. Custom Brand Error Pages
Some big companies show custom 500 error pages:
Airbnb’s 500 error: Shows an illustration with “Something went wrong” and their branding
GitHub’s 500 error: “Unicorn! Something went wrong on our end”
Reddit’s 500 error: “Sorry, we had some trouble” with their mascot
Discord’s 500 error: “500 INTERNAL SERVER ERROR”
These are still standard 500 errors, just with better design. The HTTP status code is the same.
What All These Have in Common
No matter which variation you see, they all mean:
- The problem is on the server, not your device
- Refreshing 2-3 times is fine, but 20 times won’t help
- The website owner needs to fix something
- If you’re scraping, your error handling needs to catch this and retry later
Why You Sometimes See 500 Errors on Multiple Sites at Once
When a big infrastructure provider breaks — CDN, DNS, proxy, load balancer — it’s not just one website that dies. It’s everything that sits behind it.
That morning, millions of users saw 500s on sites that have nothing to do with each other:
- X
- ChatGPT
- Spotify
- News sites
- Crypto exchanges
- Random blogs
It felt like the internet was falling apart. In reality, it was one system upstream bottlenecking thousands of websites.
When Cloudflare’s internal bot-management configuration file crashed their proxy services, every website using that layer responded with the same “500 Internal Server Error” — not because the sites were broken, but because the path to reach them cracked.
How 500 Errors Break Web Scrapers
If you’re running web scrapers, you probably saw this outage break your data collection too. But here’s the thing: 500 errors happen to scrapers even when there’s no global outage.
I’ve built scrapers that run 24/7, and I see 500 errors almost weekly – sometimes from the target site having issues, sometimes from rate limiting that triggers server overload, sometimes from proxy problems.
The Cloudflare incident on November 18 was unusual in scale, but the core problem (infrastructure failure blocking access) is something every scraper needs to handle.
When your scraper hits a 500 error, here’s what typically happens:
Without error handling: Your scraper crashes completely. You lose all progress. If you were collecting 10,000 products and hit an error 500 on product 8,543, you have to start over.
With bad error handling: Your scraper logs an empty record. You end up with a dataset full of blanks and don’t realize until you try to analyze the data.
With good error handling: Your scraper recognizes the 500, waits, retries, and continues. You get complete data even when servers hiccup.
During the Cloudflare outage, scrapers with retry logic automatically recovered once service resumed. Scrapers without it needed manual restarts.
How to Solve 500 Errors
Not all 500 errors are the same. Some you can fix on your end. Others you just have to wait out. Here’s how to tell the difference and what to do about each.
Test First: Is It You or Them?
Before trying to fix anything, open the URL in your regular browser.
If the page loads fine in your browser → The problem is with your scraper (you can fix this)
If you see a 500 error in your browser too → The server is broken (you can’t fix this, skip to “When You Can’t Fix It” below)
Fix #1: Slow Down Your Requests
You get 500 errors after the first 50-100 requests work fine. Or you get errors that say “500.13 – Web server is too busy.” These all could mean that you are overwhelming the server with too many requests too fast.
The solution would be add delays between requests. I recommend starting with 3 seconds and adjusting based on results.
In Python:
In Octoparse:
- Open your task workflow
- Click “Settings” → “Advanced Options”
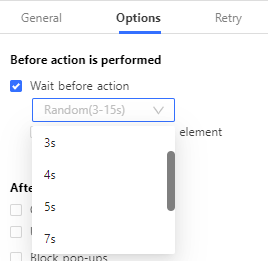
- Set “Wait before Action” to 3-5 seconds
- Or just use random interval to vary the timing
This single change fix 500 errors on about 90% of the sites I scrape.
Fix #2: Use Proper Headers
When you get 500 errors immediately, on the very first request, every single time, the problem would be your scraper announces itself as a bot, and the server rejects it.
Make your scraper look like a normal browser by adding headers so it can mimick human browing behaviors:
In python it would look like:
Fix #3: Rotate IP Addresses
Your first 20-50 requests work, then you suddenly start getting 500 errors on everything. Or you get consistent 500s right from the start. The server sees all your requests coming from one IP address and blocks you.
For situation like these, use proxy rotation. This makes your requests come from different IP addresses so you don’t look like a single bot hammering their server.
Types of proxies:
Datacenter proxies: Cheaper ($50-100/month) but more likely to get blocked. These come from data centers, not real homes.
Residential proxies: More expensive ($200-500/month) but much harder to detect. These come from real home internet connections.
For serious scraping that keeps hitting 500 errors, residential proxies are worth the cost.
In Python with rotating proxies:
In Octoparse:
Octoparse has built-in proxy support. Go to Settings → IP Proxy Settings and add your proxy provider’s details. When you run in the cloud, Octoparse can automatically rotate IPs for you.
Fix #4: Add Smart Retry Logic
When you hit a temporary 500 error (server hiccup), your scraper gives up instead of trying again.
The solution to that would be add retry logic that waits and tries again, with increasing wait times:
python
This “exponential backoff” approach gives the server more time to recover with each retry.
In Octoparse:
Octoparse has this built in:
- Open your task workflow
- Look for the setting for the specific workflow “Go to webpages”
- Click “Add condition”
- Set: If page text contains “500 Internal Server Error” → Reload page
For further detail on how to set a retry in Octoparse, you can read our tutorial for more powerful features of Octoparse.
During the Cloudflare outage on November 18, scrapers with retry logic automatically recovered once service came back. Scrapers without it needed manual restarts and lost data.
Fix #5: Use Cloud-Based Scraping
Your home/office internet connection is unreliable or gets blocked. The solution would be to run your scraper in the cloud instead of on your local computer.
Benefits:
- More reliable internet connection
- Can rotate through multiple IP addresses automatically
- Doesn’t depend on your computer staying on
- Generally faster
In Octoparse:
Use “Cloud Run” instead of “Local Run” when you start your task. Cloud runs cost credits, but during infrastructure issues (like the Cloudflare outage), they performed much better because they could automatically switch to working servers.
Further reading: How to Bypass Cloudflare

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
How to Detect Infrastructure Issues Early
You can avoid wasted scraping time by checking site status before running large jobs:
Status pages to bookmark:
- Cloudflare Status: status.cloudflare.com
- AWS Service Health: health.aws.amazon.com
- DownDetector: downdetector.com
Before starting a scrape of 10,000+ pages, I do a quick test scrape of 10 pages. If I see errors, I check these status pages before committing to the full job.
Conclusion. What the November 18 Outage Teaches Us
The Cloudflare outage was a reminder that even the most reliable infrastructure can fail, that server-side failures like 500 Internal Server Errors can disrupt even the most robust web infrastructures, impacting both users and automated processes like web scraping.
To sum up what we walked through:
- A 500 Internal Server Error means something broke on the server, not your device. When infrastructure providers like Cloudflare fail, thousands of websites can go down simultaneously—exactly what happened on November 18, 2025.
- For web scrapers and data collectors, 500 errors are especially costly. Without proper error handling, a single 500 error can crash your entire scraping job, corrupt your dataset with blank records, or waste hours of collection time.
- Most 500 errors when scraping can be fixed on your end. Slowing down requests, adding proper headers, rotating IP addresses, and implementing retry logic solve about 80% of scraper-related 500 errors. The other 20% are server-side issues you simply have to wait out.