About Job Boards
It is true that whoever owns the job seeker market owes a multi-billion dollar market. Indeed, Monster Zip recruiters know that. Google even started to share the job market pie in 2017. Companies keep spending money to find the candidates to fit the right jobs. As a result, there is still great potential for us to explore the job markets.
In this article, I will introduce how to build a job board website of Fortune 500 from ground zero. I will also parse Linkedin’s business model to fuel your business.
The quality and quantity of the job listings are, therefore, crucial for your websites to survive. There are two approaches to boost the volume of listings on your job board websites:
1. Scrape job listings from the career section of companies’ websites
2. Scrape from job listing search engines like Indeed and Monster.com
#Method 1: Scrape Job Listings Online
Because each company has its website, we need to build a spider for all of them.
A traditional method is to write python with Beautiful Soup. This leads to high initial and maintenance costs.
Thus we need to write an individual script for each company due to each website having a unique layout. In addition, the site will likely change its web structure.
As such, we have to rewrite the script and build a new spider to scrape the website.
There are also many websites which would be only accomplished by a troop of tech experts to make your website sustained. The high marginal cost of adding one more labor is untenable for business.
Web scraping tools come in handy as the most effective alternative at a much lower cost.
It allows us to automate the entire scraping process without writing a script. Octoparse stands out as the best web scraping tool. This will enable both first-time starters and experienced tech experts to extract data at click-through visualized interface.
Since there are 500 websites, I will take Facebook as an example in this article. (This is Fortune 500 list of companies’ websites, and welcome to take full advantages.)
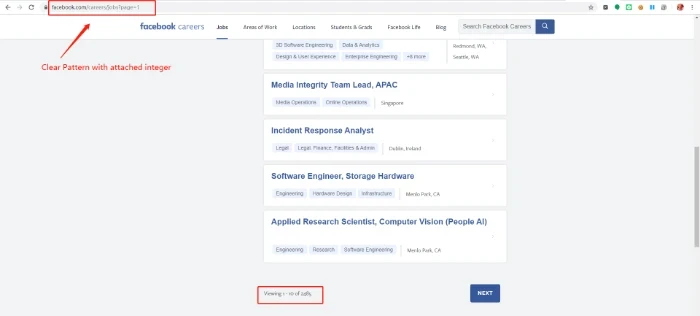
As one can inspect, the webpage contains ten listings and spread over to multiple pages.
We will click through each job listing, extract each job title, location, responsibility, minimum and preferred requirements. For web pages with a nested list (List that contains additional lists) like this we can:
- Collect the first layers of listing URLs to expedite the scraping process, mainly when the website includes a large volume of listings.
- Set up an automated crawler to scrape detail pages.
- The URL follows a consistent pattern with a fixed hostname and a page tag at the end. The numbers change accordingly as you paginate. As such, we copy the first page URL to a spreadsheet and drag it down to get a list of website URLs.
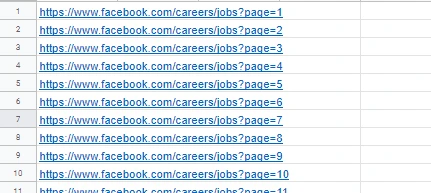
2. Then we set up a crawler with this list URLs using Octoparse.
With the built-in browser, we can extract target elements on the web page with a given command.
In this case, we click on one job listing within the page and choose “Select All” to create a loop item with all listings.
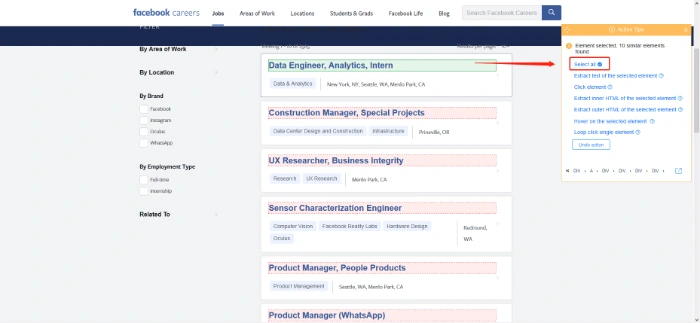
3. Then choose “Loop Click on Each Element” to go through each detail page.
4. Likewise, select to extract elements including job title, location, responsibility, minimum and preferred requirements from the detail page.
Follow the same idea, and we can create as many crawlers as you need with Octoparse.
In addition, the risk of high maintenance cost is minimized.
You can set a scraping schedule and deliver an up-to-date job listing to your database through the API portal.
#Method 2: Scrape Jobs from Job Boards
Job search engines like Indeed and Monster.com provide a considerable amount of job listings.
We can obtain that job information from both large and small companies with one crawler.
On the other hand, it doesn’t give you a competitive edge among the competitions if you source from job search engines.
The most approachable solution is to find a niche.
Instead of a website with a broad scope, we can narrow down to specific groups. It can be creative based on supply and demand.
In this case, I scraped 10000 job listings and correlated locations, and them with the map to see how data science positions spread geographically.
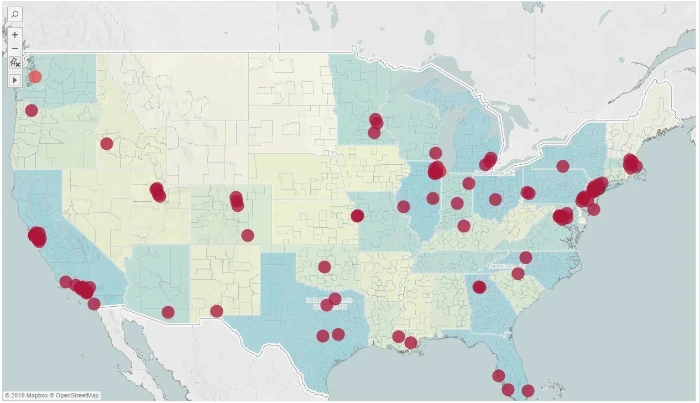
Data science positions are predominantly clustered in coastal areas, with Seattle and New York possessing the highest demand.
With that in mind, it would be an excellent opportunity to help more tech companies find the right candidates through local data scientist communities.
I have a similar video of tutors on how to scrape job listings.
Business Model for LinkedIn’s Job Board
From a blip to a giant, Linkedin is sophisticated in business strategies. Here are four factors inspired by them that would benefit your business on many levels:
- Find the right evangelist: a kick-off start is to invite “champions” and industry leaders to evangelize your website. These champions have the charismatic effect that will translate into elites assembling.
- Social Network Community: Subscribers carry more business value once they gather together. The community generates UGC (user-generated content) to attract more quality users to share their ideas. These are the assets that will increase competitiveness.
- Trustworthiness: The goal of a job board website is to help them land on their careers. It’s a little cliché to say “helping others helps yourself”, but it is the right mentality if you are in pursuit of a successful business.