You search “dentists in Chicago” on Google Maps and the sidebar shows dozens of results. Scroll a little further and the list runs out. There are clearly more dentists in Chicago, but Google just is not going to show you all of them in one view. That gap, between what is on the map and what you can actually pull off it, is the entire reason Google Maps extractors exist. Unlike a generic google web scraping tool that pulls any page structure, a Google Maps extractor is purpose-built to work around the platform’s display limits and return structured local business data.
The market for these tools has gotten crowded. Browser extensions, cloud APIs, AI agents, pay-per-result actors, and lifetime-license desktop apps all promise the same thing, but they price it very differently. This guide compares the eight google map extractor options most teams actually shortlist in 2026, with real pricing pulled from each vendor’s own page, the limits that do not show up in the marketing copy, and a clear take on which kind of buyer each one fits.
A note on method before we start: every price below comes from the vendor’s own pricing page or product documentation as of June 2026. Plans change often in this category, so confirm at checkout. We didn’t take payment from any vendor in this list.
Quick Comparison: 8 Google Maps Extractors at a Glance
| Tool | Type | Free tier | Paid starting price | Best for |
| Octoparse | Desktop + cloud, no-code | Yes (limited) | $83/mo Standard | Large-scale, complex geographies, custom workflows |
| Chat4Data | Chrome extension, AI chat | Yes (limited) | From $10/mo (Pro) | Non-technical users wanting AI-driven extraction |
| GMapsExtractor.com | Cloud subscription | 1,000 leads/mo | $39/mo (100K leads) | Marketers wanting flat-rate, predictable cost |
| Apify Compass | Cloud actor, pay-per-event | $5/mo credits | From $2.10/1,000 places | Developers, technical teams needing API + integrations |
| GMPlus | Free Chrome extension | ~40 leads/scrape | One-time license (varies) | Quick one-off scrapes, freelancers |
| GMapExtractor.io | Cloud, subscription | No | $9.90/mo Standard | SEO agencies, prospecting teams |
| Outscraper | Cloud + API, pay-per-record | 500 records/mo | $3 per 1,000 records | API-first teams, large bulk jobs |
| HasData / Clay / GitHub / Bing | Various | Varies | Varies | See “honorable mentions” below |
The rest of this guide unpacks each tool, then helps you match one to your situation.
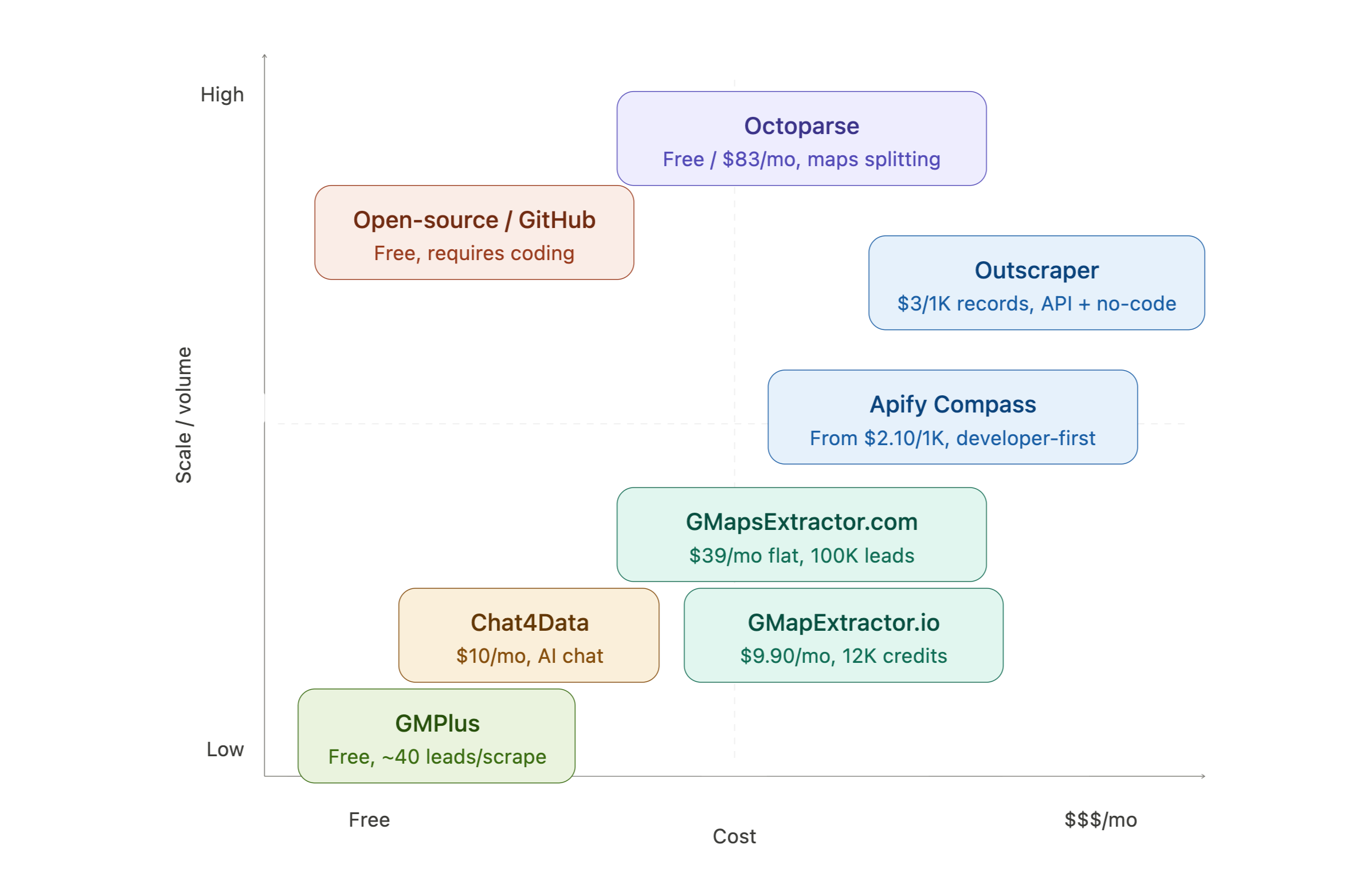
How the 8 tools compare based on scale/volume and cost.
What Is a Google Maps Extractor?
A Google Maps extractor (sometimes called a Google Maps scraper or g maps extractor) is a tool that pulls structured business data like names, addresses, phone numbers, websites, ratings, reviews, opening hours, and coordinates out of Google Maps search results, and exports it to a usable format like CSV, Excel, or JSON. It automates what would otherwise be hours of manual copying.
Extractors fall into four architectures, and the right one depends mostly on volume and where your team prefers to work:
- Browser extensions (Chrome or Edge) work as a google maps extractor extension that scrapes what is visible on the page in front of you. Any google maps extractor chrome extension runs locally in your browser, which keeps costs low but caps throughput at whatever you can load in a single session.
- Online cloud platforms run extraction on remote servers, usually with proxies and anti-bot infrastructure built in. Higher throughput, usually paid by record or subscription. This is the category most teams mean when they search for a google maps extractor online.
- Desktop apps run locally on Windows or Mac. Octoparse is the most full-featured google maps extractor app in this category, with both a desktop client and cloud execution through a visual workflow builder or prebuilt templates. You can also connect it to AI agents like Claude and ChatGPT to get real-time data.
- Open-source / GitHub projects are the google maps extractor github path: free if you are comfortable running code yourself, but you trade money for setup time and ongoing maintenance. Any open-source scraper requires regular updates as Google’s UI changes.
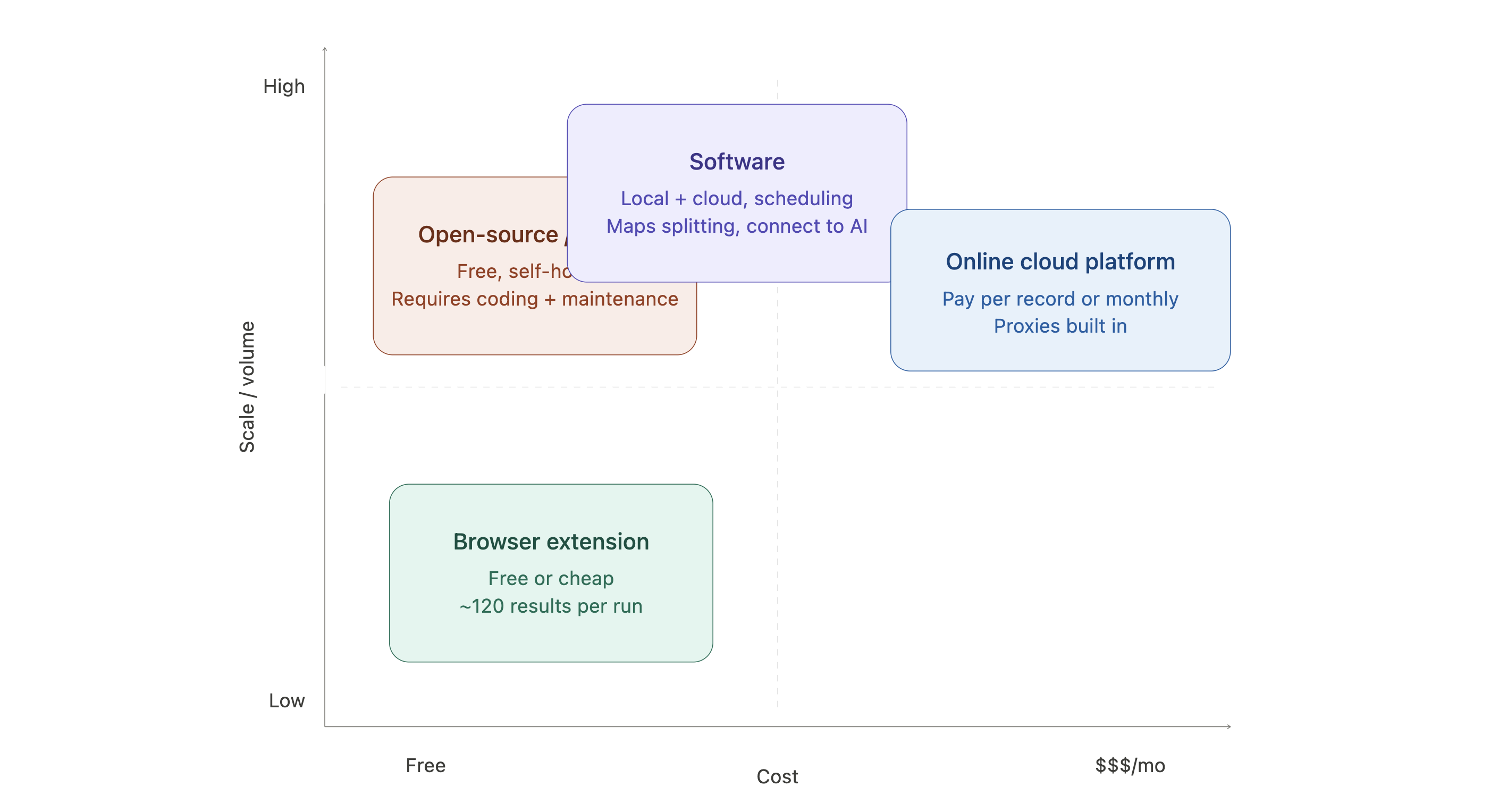
How the four Google Maps extractor architectures compare
A Google Maps extractor is not the same as the Google Places API. The official API gives you up-to-date data through a paid Google Cloud account, but it hard-caps results: the current Nearby Search (New) returns a maximum of 20 places per request with no pagination, while Text Search (New) returns 20 per page with pagination but still tops out well below what a city actually contains. The older Legacy API allowed up to 60 results across three pages, but Google is migrating all users to the New API. Either way, if your target city has 5,000 restaurants and the API returns 20–60, you’re missing most of them. Extractors work around this by simulating what a person would see on the Maps interface, which means they can pull more places per query, but they require more strategy to cover a city completely.
How We Evaluated These Google Maps Extractors
We ranked the eight tools below on five criteria, in roughly this order of importance for most buyers:
- Coverage strategy. Google Maps caps visible results at around 120 places per search view. The tools that handle this well through grid-based searching, polygon splitting, or multi-coordinate seeds beat the tools that just scroll the sidebar harder.
- Field depth. A tool that returns only name and address is useless for outreach. We checked which extractors pull contact data (phone, email, website, social profiles) and which require a separate enrichment step.
- Pricing transparency. Some vendors publish flat per-record rates. Others bundle credits, tokens, and add-ons into a structure that’s hard to budget against. We flagged where pricing requires more math than it should.
- Ease of use. A no-code interface matters to most marketing and sales buyers. Developers may want the opposite: clean APIs and webhooks.
- Output quality and format. CSV and Excel are table stakes. JSON, scheduling, and CRM integrations/ Connect to AI separate the serious tools from the demo-grade ones.
The 8 Best Google Maps Extractors Compared
Octoparse: Best for Large-Scale, Custom Coverage
Octoparse google maps scraper landing page
Octoparse is a no-code scraping platform with both a desktop app and cloud execution. For Google Maps specifically, it goes well beyond pulling a single result page. The Octoparse Google Maps templates use a maps-splitting approach: instead of accepting Google’s roughly 120-place ceiling per view, Octoparse splits a target region into multiple geographic seeds: different coordinate pairs at different zoom levels and runs the extraction across each one, then deduplicates the merged results.
The Octoparse Google Maps Scraper template: input a keyword and location, get a structured spreadsheet.
This matters most for cities where a single search clearly leaves businesses on the table: dense urban cores like Manhattan or Tokyo, coastal cities where naive rectangular bounding boxes waste budget on water, and multi-island geographies like Hong Kong or Jakarta. Octoparse’s approach uses real geographic boundaries (polygon and multi-polygon) instead of simple rectangles, removes maritime areas from the search grid, and adapts grid density based on region size and POI density.
Extraction runs in two layers: a list pass for basic fields (name, rating, reviews, address, coordinates) and a detail pass for richer fields (phone, website, hours, photos, popular times, Plus Code, delivery info, price level). You can run the listing-only pass when you just need a count, or the full enrichment pass when you need outreach-ready records.
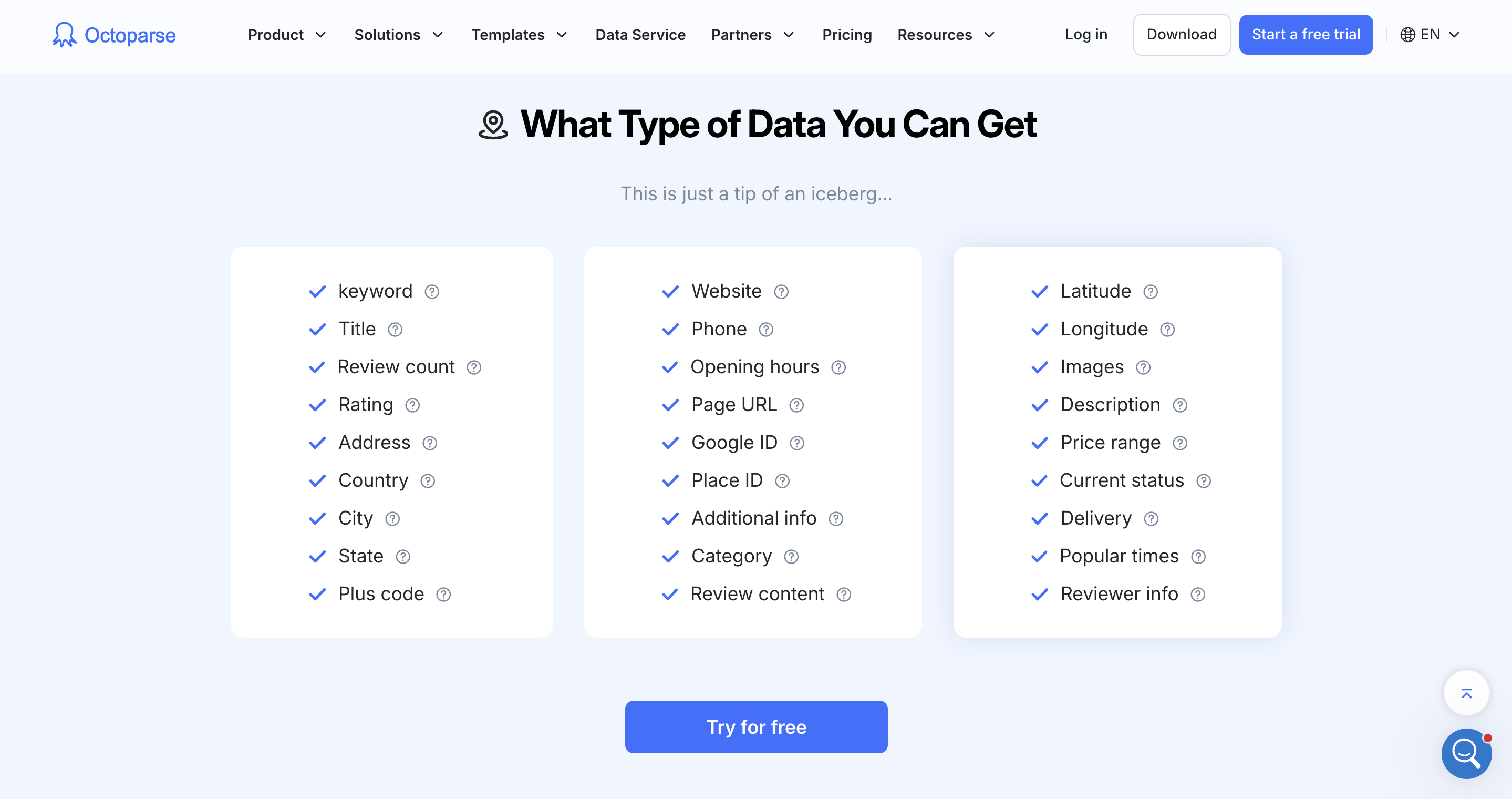
What Octoparse Google Maps Scraper Template Can Offer
Key features: Visual workflow builder; pre-built Google Maps templates; cloud execution with scheduling; IP rotation; built-in CAPTCHA solving; Google Sheets, Excel, JSON, CSV, and database export; Open API; Octoparse MCP for AI workflows(connect to AI).
Pricing: Free plan available. Standard plan starts at $83/mo (billed monthly; lower with annual billing). Professional plan at $249/mo. Enterprise pricing on request. Pricing varies across Octoparse’s own pages. Always confirm the checkout price before subscribing.
Best for: Sales and marketing teams running multi-city or country-level lead generation; market research projects that need real geographic coverage rather than a sample; product teams building local business databases that need to be refreshed on a schedule.
Limitations: The free plan is restrictive. Most real work requires the Standard plan or above.
https://www.octoparse.com/template/google-maps-scraper-store-details-by-keyword
Chat4Data: Best AI-Powered Google Maps Scraper Extension
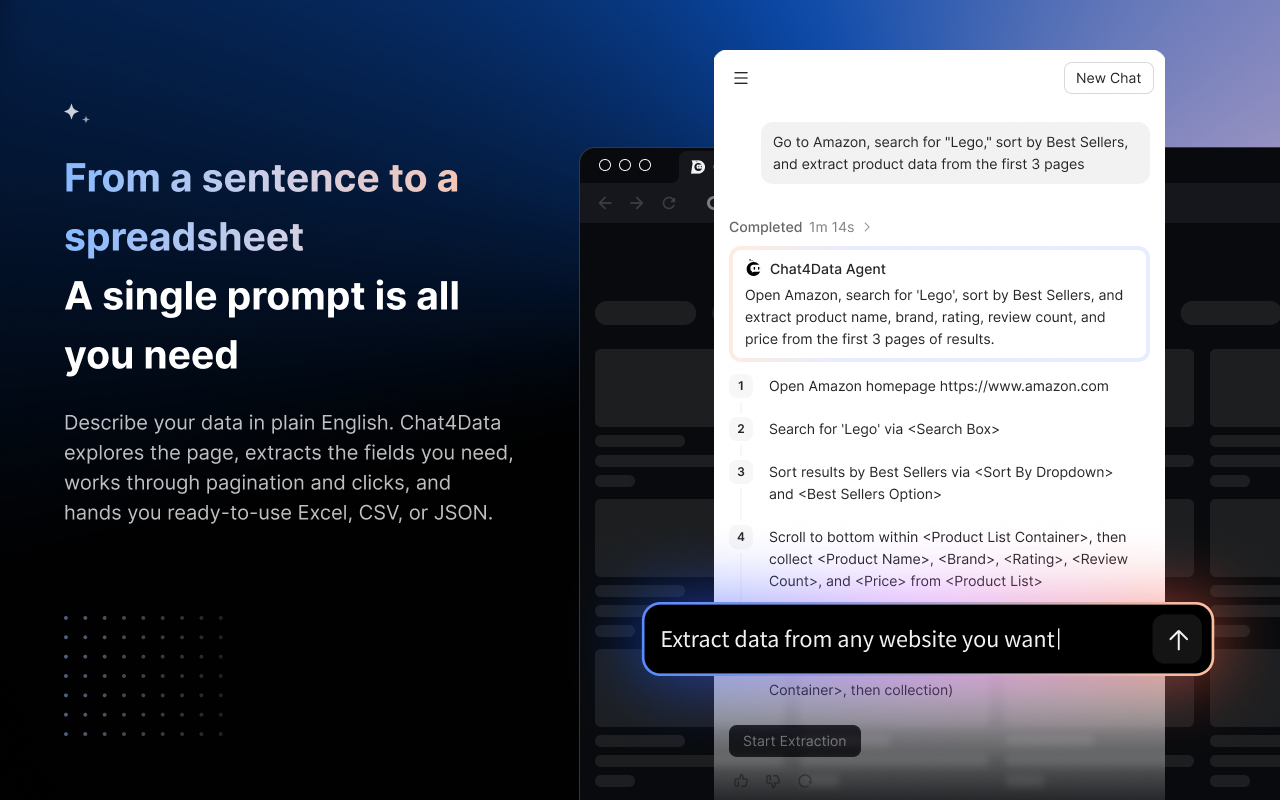
How Chatdata Works (Source from: Google Chrome web store)
Chat4Data is an AI-powered google maps extractor extension for Chrome that turns web scraping into a conversation. If you have ever wanted a tool that just understands what you want, this is the closest thing to that on the market right now. You open Google Maps, search for what you want, then describe the data you need in plain English, for example “extract business name, phone, email, and rating for every result on this page.” The extension’s AI auto-detects the fields, handles pagination and infinite scroll, and exports clean CSV or Excel.
What makes Chat4Data different from the other extensions in this list is generality. It isn’t a Google-Maps-only tool. It works across most listing-style websites. But Maps is one of its most common use cases. There are no XPath selectors to learn, no template to configure. For non-technical marketers and researchers who don’t want to commit to a full scraping platform, it’s one of the lowest-friction options on the market.
Key features: Natural-language field detection; one-level-deep detail page extraction; pagination handling; CSV and Excel export; runs locally in your browser; works on most HTML sites beyond Google Maps.
Pricing: Free credits for new users (300 credits on registration, refreshed on each of your first 3 login days). Pro plan at $10/mo (2,000 credits/month). Max plan with 8,000 credits/month. Credits are consumed on scraper configuration (50–120 credits average) and scraper launch (10 credits per run); once launched, scrapers run without consuming additional credits.
Best for: Non-technical users who already use AI tools and prefer chat interfaces; anyone who needs occasional Google Maps extraction alongside scraping other websites; quick validation runs before committing to a heavier tool.
Limitations: Browser-bound, so throughput depends on your machine. Credit-based pricing requires test runs to estimate cost per project. No native scheduling — while you have to keep the tab open during extraction, you can switch tabs.
GMapsExtractor.com (G Maps Extractor): Best Flat-Rate Subscription
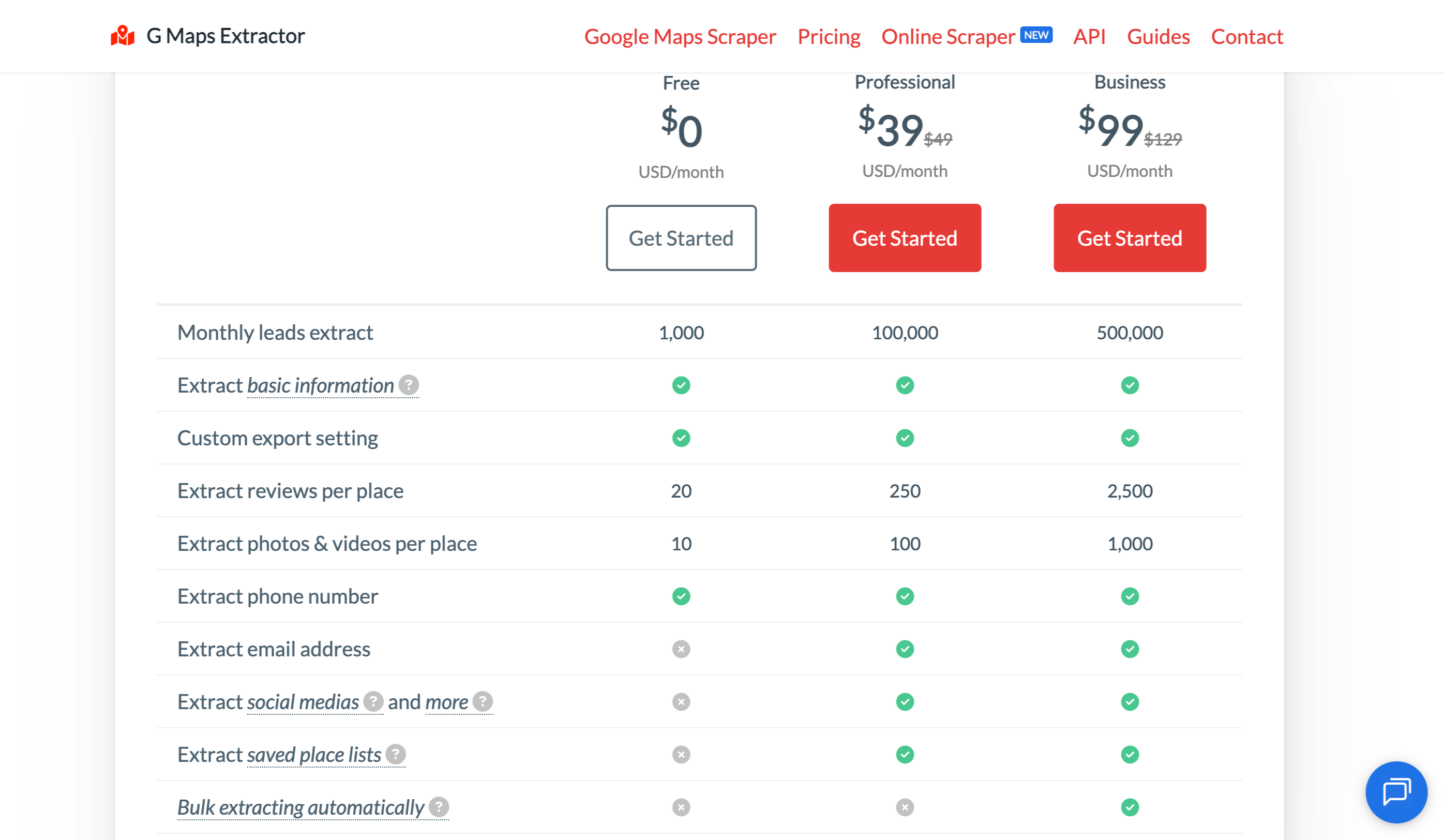
GMapsExtractor Pricing Information
G Maps Extractor is a cloud-based Google Maps scraper sold on a flat monthly subscription. You log in, search by keyword and location, and export results as CSV, JSON, or XLSX with phone numbers, emails, addresses, websites, and social media profiles.
The pitch is pricing simplicity. There are no credits, no per-record math. Pay one monthly fee, get a fixed lead allowance. The Free plan covers 1,000 leads per month for testing. The Professional plan is $39/month for 100,000 leads. The Business plan is $99/month for 500,000 leads. At 500K leads, that works out to roughly $0.0002 per record, which is competitive with anything in the per-record category at high volume.
Key features: Cloud-based (no extension or software install); CSV/Excel/JSON export; bulk keyword and location search; email and social media extraction; cancel anytime.
Pricing: Free (1,000 leads/mo). Professional $39/mo (100K leads). Business $99/mo (500K leads).
Best for: Marketers who want predictable monthly cost; teams running steady-state outreach campaigns where lead volume is roughly the same every month; users who hate credit systems.
Limitations: Less independent third-party review coverage than Outscraper or Apify. Flat-rate pricing is great when you use your full allowance and wasteful when you don’t.
Apify Compass Google Maps Extractor: Best Developer-Friendly Cloud Actor
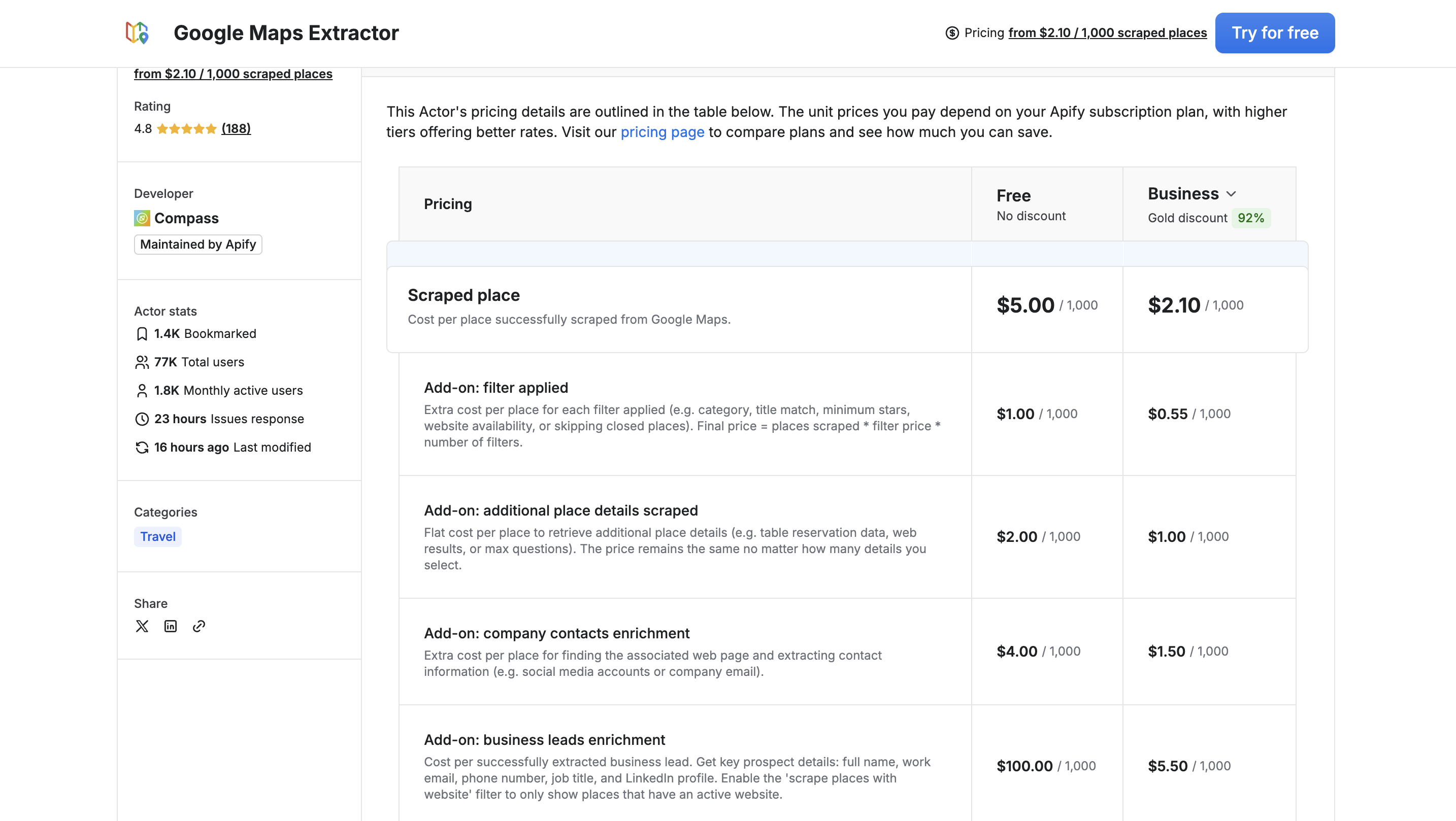
Apify’s Compass Google Maps Extractor Pricing Information
Apify’s Compass Google Maps Extractor is a pay-per-event “actor” running on Apify’s cloud platform. It explicitly bypasses the roughly 120-place-per-area Google Maps display limit and supports custom search areas defined as Polygon, MultiPolygon, or Point geometry, which is useful for technical users who want to control exactly which patch of map gets covered.
Apify shifted Google Maps actors to pay-per-event pricing in 2025. On the actor page, pricing starts at $2.10 per 1,000 scraped places. The pay-per-event breakdown works out to $4 per 1,000 places base, plus a small $0.007 actor start fee per run. Add-ons stack on top: contact details cost $0.002/place, reviews run $0.0005/review, and filters add $0.001 per filter per place. A real example: scraping 10,000 places with contact details comes to roughly $40 base + $20 contacts = about $60. The pricing is granular and predictable once you understand the events, but it does require reading the documentation.
Key features: Pay-per-event cloud execution; Polygon/MultiPolygon/Point custom areas; integrations with Zapier, Slack, Make, Airbyte, Google Sheets, LangChain; Apify API (Node.js and Python clients); webhooks; MCP server support for AI agents.
Pricing: Free plan with $5/mo credits. Apify Starter subscription begins around $29/mo. Pay-per-event: from $2.10 per 1,000 places (base $4/1,000 + platform usage), plus filter and enrichment event costs.
Best for: Developer teams already using Apify or building custom data pipelines; anyone needing API access, webhooks, or programmatic orchestration; technical users comfortable with JSON input schemas.
Limitations: UI is denser than no-code competitors. Pay-per-event pricing requires test runs to estimate cost on real workloads. Email enrichment usually requires a separate actor.
For an honest comparison, see our article on Apify vs. Octoparse Google Maps Scraper.
GMPlus: Best Free Chrome Extension
GMPlus is a free google maps extractor chrome extension built for lead generation. You can grab it as a free download from the Chrome Web Store, open Google Maps or Bing Maps, search for your target category, click “Start Extracting,” and the extension scrapes what is visible, including phone numbers, email addresses, websites, and social media links, into a CSV. The free version handles around 40 leads per scrape, which is enough for testing or genuinely small jobs. Paid plans (one-time license) lift that cap.
The free version handles around 40 leads per scrape, which is enough for testing or genuinely small jobs. Paid plans (one-time license) lift that cap. GMPlus also extracts emails from business websites linked in Google Maps listings, which is a feature most basic extensions skip.
Key features: Free Chrome extension; ~18 data fields per business including email and social profiles; supports Google Maps, Bing Maps, and Instagram; CSV export; runs locally in browser.
Pricing: Free version with per-scrape cap. Paid lifetime licenses available — pricing depends on plan tier; check current rates on the GMPlus pricing page.
Best for: Freelancers and solo operators with small, occasional lead-gen needs; users who want to validate a niche before paying for a real tool; anyone scraping <100 records at a time.
Limitations: Browser-bound throughput. Per-scrape limit on the free tier means you can’t pull a whole city in one go. Less polish than paid alternatives.
GMapExtractor.io: Best for SEO Agencies and Local Audits
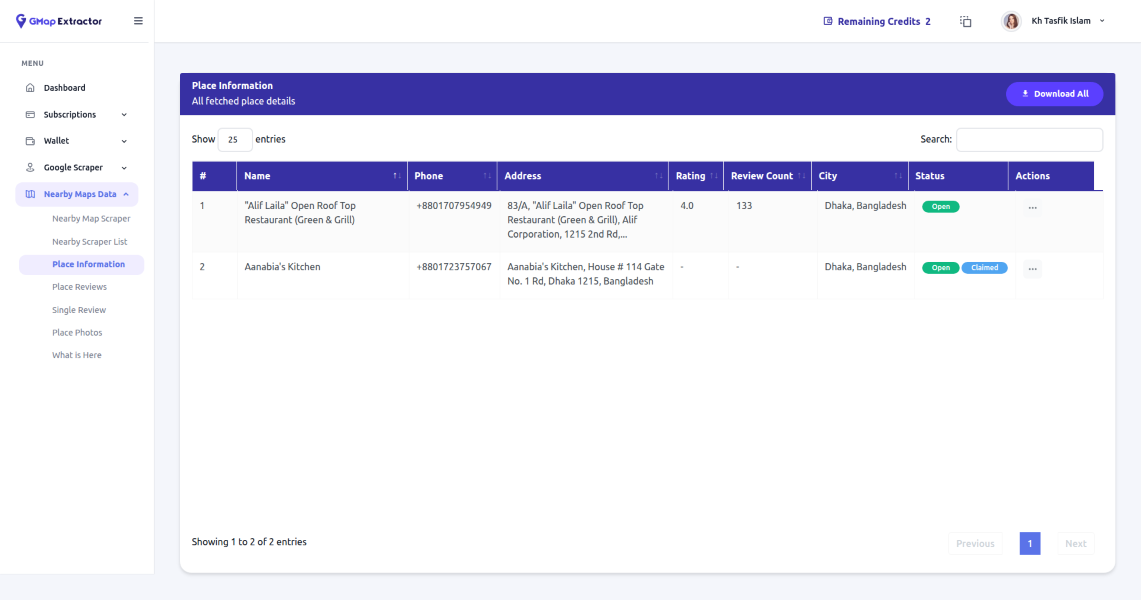
G Map Place Information
GMapExtractor.io is a cloud-based, no-code Google Maps scraper with a clean focus on agency and prospecting use cases. You search by category, city, or radius, and export to CSV or Excel with name, address, phone, website, rating, coordinates, and category. There’s also a “What Is Here” mode for identifying businesses at specific coordinates, which is useful for local SEO audits and geo-research.
Key features: Cloud-based no-code interface; category, city, and radius search; CSV and Excel export; API access on all plans; reviews, photos, and place info extraction; safe pacing to reduce blocks.
Pricing: No free tier. Standard plan at $9.90/mo (12,000 credits/month). Premium at $19.90/mo (35,000 credits). Business at $39.90/mo (100,000 credits). Enterprise at $99.99/mo (1,000,000 credits). Annual billing saves 20%.
Best for: Local SEO agencies running competitor audits across multiple cities; prospecting teams that want a middle-ground option between a Chrome extension and a developer-grade API; users who want CRM-ready output.
Limitations: No free tier, so you have to commit from day one. Less name recognition and review coverage than Octoparse or Apify.
Outscraper: Best for API-Based Bulk Extraction
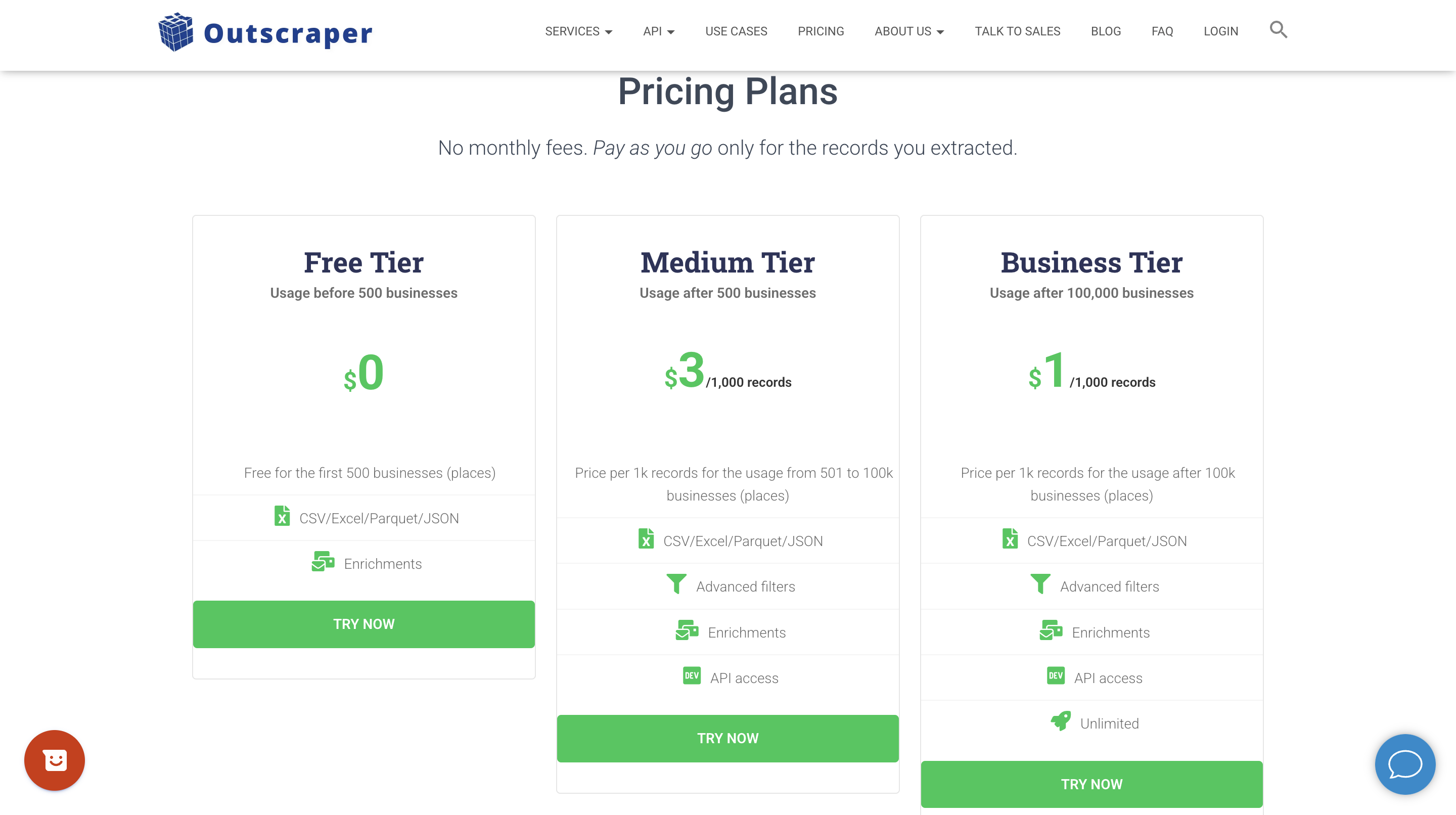
Outscraper Pricing Information
Outscraper is a cloud platform with both a no-code UI and a full REST API, sold on pay-as-you-go pricing with deep volume discounts. Like Octoparse, it’s one of the most-reviewed Google Maps tools on Capterra and AppSumo, which matters when you’re evaluating a vendor that touches Google’s infrastructure.
The pricing tiers reset every 30 days. The first 500 Google Maps records each month are free. Records 501 through 100,000 cost $3 per 1,000 ($0.003 each). After 100,000 records, the rate drops to $1 per 1,000 ($0.001 each). For agencies running multiple client campaigns or anyone needing to extract hundreds of thousands of records per month, the volume discount is meaningful.
Outscraper also offers enrichment scrapers for email and contact data, phone validation, and social media links that can be chained onto a Google Maps extraction.
Key features: No-code UI plus REST API; SDKs for Python, PHP, Node, Go, Java, Ruby; CSV/Excel/JSON/Parquet export; CRM integrations (HubSpot, Zoho, Pipedrive); Zapier and Make connectors; covers Google Maps, reviews, photos, and more across 249 countries.
Pricing: Free first 500 records/mo. $3 per 1,000 records (501–100K). $1 per 1,000 records (after 100K). Email & Contacts enrichment $3 per 1,000.
Best for: Technical teams building data products on top of Google Maps; agencies running high-volume monthly extractions; anyone who needs the API as a first-class interface, not an afterthought.
Limitations: Credit system can take a few minutes to wrap your head around. Costs scale fast if you also run heavy enrichment without checking the per-event prices first.
Honorable Mentions: HasData, Clay, Open-Source, and Bing Maps
A few tools come up often in “Google Maps extractor” SERPs without being the right primary pick for most teams. Worth knowing they exist, worth knowing why they’re not in the top seven.
HasData Google Maps Scraper. A developer-focused API platform with a Google Maps endpoint. HasData is genuinely good at SERP and Maps scraping at scale through a clean REST API, but it’s API-first. There’s no point-and-click interface like Octoparse or Outscraper. If you’re choosing between HasData and Outscraper, the deciding factor is usually whether you want a no-code dashboard alongside the API (Outscraper) or a leaner API-only product (HasData).
Clay Google Maps Scraper. Clay is a workflow automation platform with a Google Maps source built in. But it’s not really a Google Maps extractor. It’s a sales orchestration tool that includes Google Maps as one of dozens of data sources. Pricing starts in the hundreds per month. Choose Clay if you want one platform to extract, enrich, and run outbound. Choose anything else in this list if you just want the Maps data.
Open-source Google Maps scrapers (GitHub). Search “Google Maps extractor GitHub” and you’ll find dozens of repositories. The most popular is the Botasaurus-based Google Maps Scraper from omkarcloud, which extracts 50+ data points with no recurring fees and offers a hosted API at $16/month for users who don’t want to self-host. These projects are excellent if you’re a developer comfortable maintaining code as Google’s UI changes; they’re a poor fit for non-technical buyers because most are unmaintained, output formats vary, and you carry all the anti-bot maintenance burden yourself.
Bing Maps extractors. Tools like the Maps Scraper & Leads Extractor extension (4.7 stars on Chrome Web Store) extract business data from Bing Maps, not Google Maps. In some niches Bing surfaces different businesses than Google, so a Bing Maps tool can be a useful complement to your Google Maps stack but if you’re shopping for a Google Maps extractor specifically, you want one of the seven options above.
What Data Can You Extract from Google Maps?
Most Google Maps extractors return some combination of these fields. Coverage varies by tool and by listing — not every business publishes everything Google could display.
Listing-level fields (almost always available):
- Business name, category, full address, latitude/longitude, Plus Code
- Star rating, review count, average price level
- Place ID, Google Maps URL
Detail-level fields (require an extra enrichment pass on most tools):
- Phone number, official website, email address (when listed)
- Opening hours, popular times histograms
- Photos, menu links, reservation links
- Social media profiles (Facebook, Instagram, LinkedIn, Twitter, YouTube)
- Service options (delivery, takeout, dine-in)
Email is the field that varies most by tool. Google Maps itself rarely shows email addresses directly. Tools that “extract emails” almost always do it by visiting the business’s website (linked from the Maps listing) and scraping a contact page or mailto: link. This is why some extractors add email as a separate paid enrichment step rather than including it in the base extraction.
If your goal is a complete contact record for every business like phone, email, social, decision-maker name, plan for a two-step pipeline: extract from Google Maps first, then run the website URLs through a contact enrichment tool (see below).
https://www.octoparse.com/template/contact-details-scraper
For more on the coordinate field specifically, see our guide on extracting Google Maps coordinates.
How to Choose the Right Google Maps Extractor for Your Use Case
The right tool depends less on features and more on your situation. Here are the four buyer profiles we see most often.
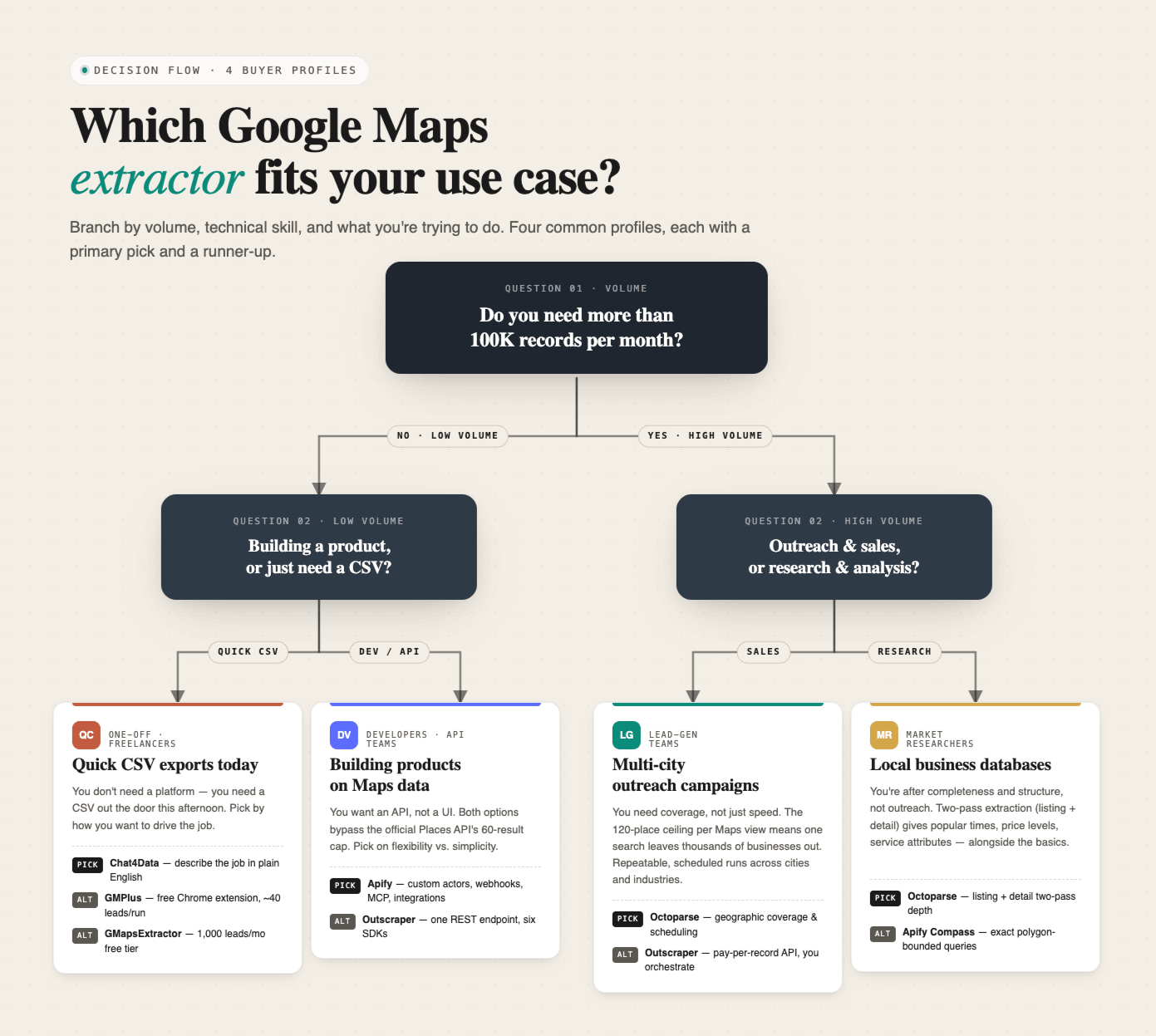
A decision flowchart for picking a Google Maps extractor based on volume, technical skill, and use case.
For lead generation teams running multi-city campaigns
Teams running local lead generation campaigns need coverage, not just speed. Any lead scraper that accepts the default 120-result ceiling per Google Maps view leaves the majority of a city’s listings out of the export. A “restaurants in Chicago” search looks complete at 120 results but misses thousands more. When choosing a leads extractor for Google Maps, the deciding factor is whether the tool splits the target area into multiple geographic seeds or just scrolls the same sidebar harder. Choose Octoparse if you need real geographic coverage across multiple cities or industries with scheduled, repeatable runs. Choose Outscraper if you would rather pay per record through an API and orchestrate everything yourself.
For a worked example of a complete lead-gen pipeline, see our walkthrough on Google Maps lead generation with MCP.
For market researchers building local business databases
You’re after completeness and structure, not outreach. Octoparse’s two-pass extraction (listing layer + detail layer) using the google maps scraper (see below) gives you the depth that researchers actually need, including popular times, price levels, service attributes, alongside the basics. Apify Compass is a strong second choice for technical researchers who want to define exact polygon boundaries for the area being studied.
https://www.octoparse.com/scraping-templates/google-maps-scraper
For developers building products on Google Maps data
You want an API, not a UI. Apify wins on flexibility (custom actors, webhooks, MCP support, integrations). Outscraper wins on simplicity (one REST endpoint, six SDKs, predictable per-record pricing). Both bypass the official Places API’s 60-result cap.
For one-time exports and small-volume prospecting
You don’t need a platform. You need to get a CSV out the door this afternoon. Chat4Data if you want to describe the job in plain English. GMPlus if you want a free Chrome extension. GMapsExtractor.com‘s free tier (1,000 leads/month) if you want a cloud option without a credit card commitment beyond signup.
The 120-Result Limit: Why Most Extractors Hit a Ceiling
Google Maps only shows about 120 places per search. This isn’t a bug or anti-scraping rule. It’s just a UI limit.
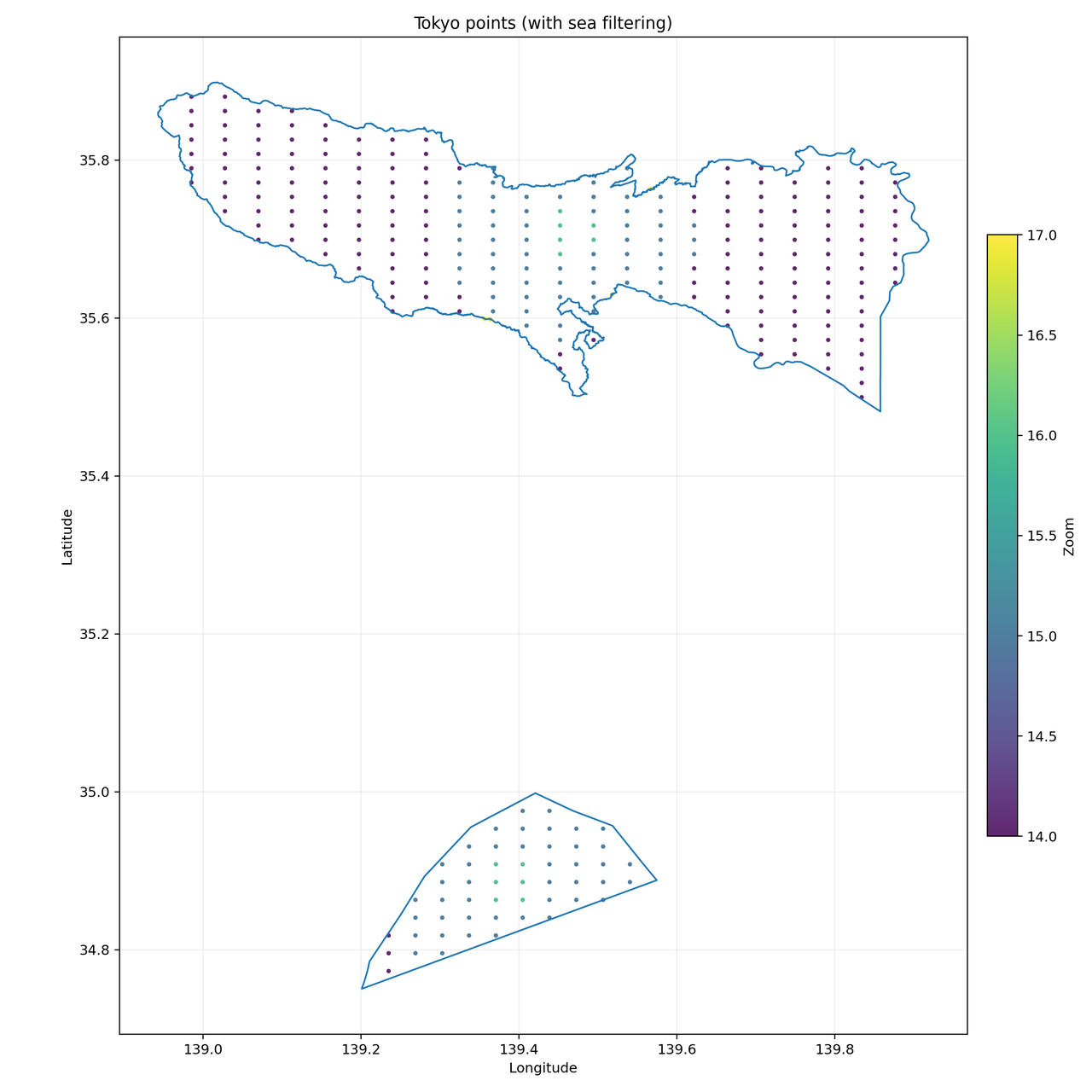
So if you search “coffee shops in Tokyo” and get 120 results, you’re only seeing one slice of the data. To go beyond that, tools need to split the area into multiple searches, use different zoom levels, and remove duplicates.
Different tools handle this differently:
- Octoparse: breaks areas into geographic grids and adjusts zoom automatically
- Apify Compass: uses polygons or points to define scrape zones
- Outscraper: relies on cloud-based search + rate handling
- Browser extensions: stay capped at ~120 results per search
For full coverage (like “every dentist in Boston”), you need a tool built for this limitation. For smaller tasks, basic tools are usually enough.
Free vs Paid Google Maps Extractors: What’s the Real Difference?
Free google maps extractor options fall into two camps: genuine free tiers from paid platforms (Outscraper’s 500 free records per month, Apify’s $5/month credits, GMapsExtractor.com’s 1,000 leads per month, Octoparse’s local extraction with 50K data rows per month) and free google maps extractor extension tools (GMPlus, Chat4Data’s new-user credits). Any google maps extractor extension free tier runs from your own browser and IP, which works fine for small one-off jobs but becomes a liability on repeated runs from the same machine.
The differences worth knowing:
Throughput. Free tiers cap monthly volume. For one-off jobs under a few hundred records, that’s fine. For ongoing campaigns, you’ll hit the wall in week one.
Enrichment. Free plans rarely include email extraction or detail-page fields. You’ll get name, address, phone, rating — and stop there.
Anti-blocking. Paid plans almost always include proxies and CAPTCHA handling. Free Chrome extensions extract from your IP — fine for small jobs, bad for repeated runs from the same machine.
Scheduling and API access. Free tiers don’t include scheduled runs, webhooks, or API endpoints. If you want yesterday’s data refreshed every Monday morning, that’s a paid feature on every tool here.
Practical rule: start free, hit a wall on either volume or fields, then move to the paid tier of the same tool — switching vendors mid-project costs you more than the upgrade.
Frequently Asked Questions about Google Map Extractors
- Is it legal to extract data from Google Maps?
Scraping publicly visible data from Google Maps occupies a gray area. Google’s Terms of Service prohibit automated scraping; enforcement is uneven and varies by jurisdiction. Several US court rulings have held that scraping public web data does not violate the Computer Fraud and Abuse Act. The official Google Places API is the unambiguously safe route for compliance-sensitive use cases. Consult a lawyer for your specific situation cause this is not legal advice.
- What is the best free Google Maps extractor?
For occasional small jobs, GMPlus (free Chrome extension, ~40 leads per scrape) and Chat4Data (free credits for new users, then Pro at $10/mo) are the two most flexible starts. For a free cloud option without per-scrape limits, GMapsExtractor.com’s 1,000-leads/month free tier and Outscraper’s 500-records/month free tier are both worth testing. Octoparse also offers a free plan, though cloud extraction will require a paid plan.
- Can I extract email addresses from Google Maps?
Sometimes directly, often indirectly. Google Maps rarely displays email addresses in the listing itself. Most “Google Maps email extractors” work by following the business’s website link from the Maps listing and scraping the contact page. Tools that handle this in one workflow include GMPlus, GMapsExtractor.com, and Outscraper (via the Email & Contacts enrichment add-on at $3 per 1,000). On Octoparse and Apify, email enrichment is a separate template or actor chained to the main extraction. But with Octoparse MCP, you can connect Octoparse to any AI and ask it to run several templates in a project.
- How do I extract Google Maps data without coding?
All eight tools in this guide are no-code in their default workflows. Octoparse uses a visual workflow builder along with pre-built Google Maps templates. And now with Octoparse MCP, you can ask any AI to extract web data. Chat4Data uses natural-language chat. GMapsExtractor.com, GMapExtractor.io, and Outscraper all have web dashboards. GMPlus and Maps Scraper & Leads Extractor are click-and-go Chrome extensions. You only need code if you want to call an extractor through an API.
For a step-by-step walkthrough of exporting Google Maps results to a spreadsheet, see our guide on exporting Google Maps search results to Excel.
- What’s the best open-source Google Maps extractor on GitHub?
The most actively maintained option is the omkarcloud Google Maps Scraper, built on the Botasaurus framework. It extracts 50+ data points including business emails, phone numbers, and social profiles, runs as a desktop app on Windows/Mac/Linux, and offers a hosted API at $16/month if you don’t want to self-host. Searching “Google Maps extractor GitHub” returns dozens of other repositories, but most are unmaintained. Google Maps changes its UI often enough that any open-source scraper requires regular updates to keep working. Open-source is the right path if you have engineering resources and want full control. It’s the wrong path if you need a tool that keeps working without you maintaining it.
- What’s the difference between Google Maps API and a Google Maps extractor?
The Google Places API is Google’s official paid endpoint, accessed through a Google Cloud account. It returns up-to-date data and avoids any terms-of-service ambiguity, but the current Nearby Search (New) caps results at 20 per request with no pagination, and Text Search (New) returns 20 per page. The older Legacy API allowed up to 60 results across three pages, but Google is migrating users to the New version. A Google Maps extractor simulates what a person sees in the Maps interface, which means it can return more places per query and pull fields the API doesn’t expose. Use the API when compliance matters most. Use an extractor when coverage matters most.
For a deeper comparison of the API path specifically, see our Google Places API guide.
Which Google Maps Extractor Should You Pick?
If we had to compress this guide into one paragraph: Octoparse if you need real coverage across complex geographies and a long-term tool you can customize. Apify Compass if you are a developer who wants a cloud actor with API and webhooks. Outscraper if you want pay-per-record simplicity at scale. GMapsExtractor.com if you want flat-rate predictability. Chat4Data if you want an AI-powered extension that lets you describe your data in plain English and get a CSV back. GMPlus if you want a free Chrome extension for one-off jobs. GMapExtractor.io if you are an SEO agency running local audits.
As part of a broader stack of lead generation tools, a Google Maps extractor covers the sourcing layer. If you also need verified emails, chain any of the above to a dedicated google maps email extractor workflow that follows website links from Maps listings and scrapes contact pages. The tool that gets closer to the businesses you actually wanted to find, tested against your own target city, is the right one.
For a complete pipeline that ties extraction to enrichment and outreach, see our walkthrough on building a Google Maps lead generation workflow.