In this article we will tell you how to scrape biographical data from websites of law firms and export the data collected into an Excel spreadsheet.
A real-life example of this kind of issues from one of our users who is looking for someone to review the websites of several hundred law firms, pull the biographical data and put it into an excel spreadsheet.
Prior to awarding the project for the full several hundred firms, he provided a test sample in his email and want to scrape all of the biographical data for all of the professionals at (1) Morgan Lewis — https://www.morganlewis.com/our-people.
The data fields for the template includes first name, last name, current employer, title, phone number, city, email address, practice area, profile overview (biography text), law school institution, law school graduation year, undergrad education, institution, undergrad education year and website bio URL. And once he have that sample reviewed, he would award the full project for the full several hundred firms.
From the email content we firstly checked the website, and viewed the search results by pressing the Search button.
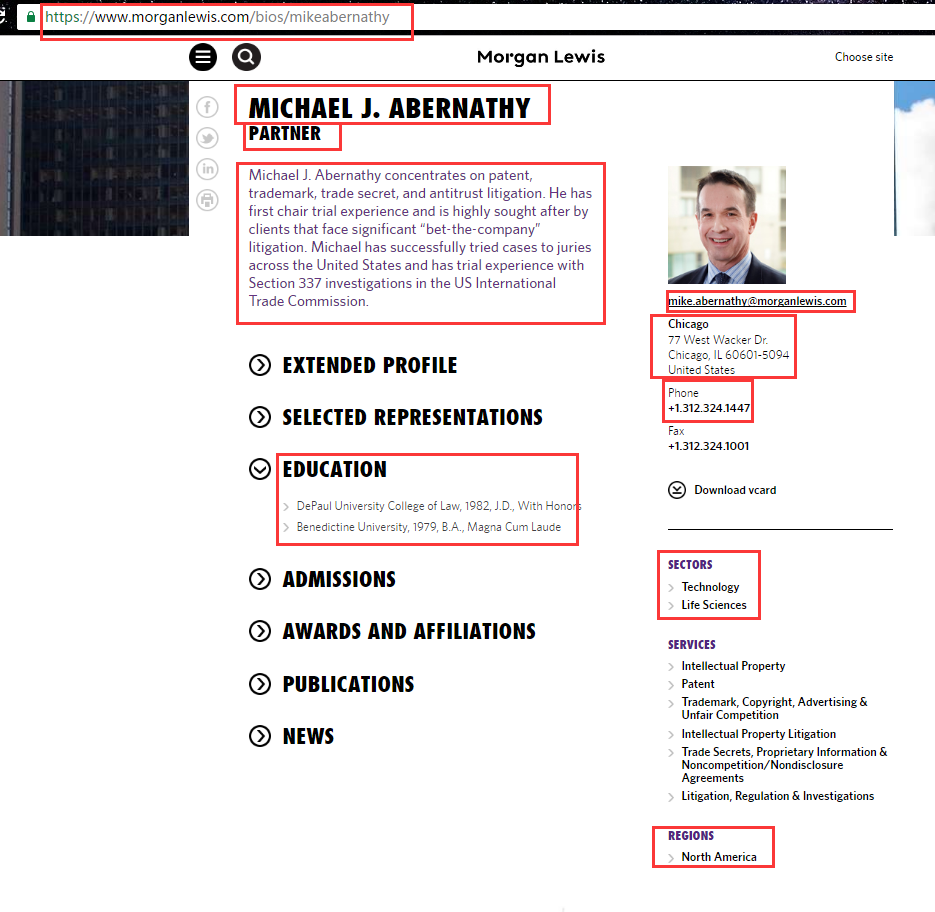
Secondly, we selected one of the professionals from the search results, opened the details page and pointed out the biographical data in red frame. Then we wrote back saying we could scrape the sites and would like to make sure this data is what they want before making a rule and giving a sample data output. We took a screenshot of the data fields in red and told him the process of getting the data with Octoparse.
The process of getting the data
1. Create a task to extract data from multiple pages (Edit the XPath of the pagination if needed);
2. Create a list of these professionals;
3. Extract the information from the detail page:
3.1 Open the “Education” part.
3.2 Extract all the information as data fields.
3.2 Edit the XPath of some data fields or use regular expression to extract the exact data.
4. Check the task: make sure all the actions of the rule work.
5. Test the task and see if it can extract what we want.
6. Get the data and export the data into an Excel spreadsheet.
And he replied, “… I’m reviewing now and some changes may needed to the actual data scraped, but I think that might be an easy fix.
1. “Current Employer” is the name of the law firm.
2. the “phone number”–all we need is the actual phone number itself (“xxx-xxx-xxxx), any other extraneous info will mess up the output on the excel or the csv file.
3. the “location”–it is the same. All we need is the city name, no other extraneous info.
4. the”education”– also, the same.
5. the”Practice Area”– on this site the practice area should correspond to “Sectors” and “Services.”
6. the “Regions”– delete it.”
We replied him back saying that we will get exact data for him and change the data fields to meet his needs. And we made a rule and sent the sample data for him.