Undoubtedly, we’re living in an age of information explosion. It’s estimated that by 2024, there will be approximately 402.74 million terabytes of data generated daily, which translates to around 147 zettabytes of data annually. Users generate countless texts every second on the Internet. Taking Twitter, currently X, as an example, 6,000 tweets are made every second, resulting in over 350,000 tweets per minute, 500 million tweets per day, and about 200 billion tweets per year. The challenge lies in extracting only the relevant information from the overwhelming flood of data. That’s when text mining comes into being.
What is Text Mining
Text mining, also known as text data mining, is a technique that can mine high-quality information from countless texts. It’s based on Natural Language Processing (NLP) and combined with some of the typical data mining algorithms, such as classification, clustering, neural network, etc. Besides that, text mining has been widely used for sentimental analysis, information extraction, topic modeling, etc.
Meanwhile, text mining is closely related to the Large Language Model (LLM) and Artificial Intelligence (AI). Text mining extracts high-quality, relevant data from large corpora for richer insights. As a tool, text mining can help LLMs and AI systems enhance their training, improve performance, and enable personalized and context-aware interactions.
Key Tasks in Text Mining
Text categorization, text clustering, production of granular taxonomies, document summarization, etc., are typical text mining projects. Here we’ll introduce you to some of the most common tasks in text mining.
Text Categorization
The goal of text categorization is to categorize text into specific classes or labels based on its content. People can organize, sort, and manage large volumes of text data. For example, you can use it to detect spam in emails, so you won’t struggle with meaningless emails anymore. Text categorization is used in various applications, such as spam email detection, topic categorization in news articles, and intent classification in customer service interactions.
Entity Extraction
Entity extraction involves identifying and classifying entities in text into predefined castigates, such as names of people, organizations, locations, dates, etc. It can help convert unstructured text into structured data, enhance search results by identifying and highlighting key entities in documents, and provide valuable insights from text data.
Word Cloud
A word cloud is a visual representation of text data where the size of each word indicates its frequency or importance in a given text or dataset. Many companies apply data visualization like this to analyze reviews, social media posts, and articles to assess customer feedback and brand mentions. Then, they can gauge market sentiment and focus areas more accurately.
Sentimental Analysis
Sentiment analysis is a process that could help you identify the sentiment from opinions based on the words. It’s a field of natural language processing (NLP) that involves determining the emotional tone or sentiment expressed in a piece of text. The most common applications are to analyze customer reviews, track public sentiment toward brands on social media, and conduct market research.
Topic Modeling
Topic modeling could help identify the topic of a piece of text. Latent Dirichlet Allocation (LDA) is an example of topic modeling that could classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions, such as tagging for reviews/news/articles.
What Can Text Mining Help in Different Industries
Text mining can provide valuable insights and benefits across various industries.
E-commerce
In the e-commerce industry, text mining can be applied to enhance customer experiences, optimize operations, and drive strategic decisions. Meanwhile, text mining is a great tool to power chatbots and virtual assistants that can respond to customer inquiries automatically. As a result, you can improve your customer support and service to give customers a better experience.
Healthcare
There are many materials for text mining in the area of healthcare. Taking medical records as an example, you can extract critical information from patient records, such as symptoms, diagnoses, and treatment plans, to support decision-making and improve patient care. In addition, mining clinical trials and scientific papers can help identify new drug candidates and potential side effects of treatments.
Education
Curriculum development and student support can benefit from text mining as well. You can develop insights from educational resources and research to inform curriculum design. Also, monitoring and analyzing student inquiries and interactions will tell what you can do to provide targeted support and enhance the learning experience.
Government and Public Sector
For government departments, text mining has been used to analyze public comments, policy documents, and legislative texts to inform policy development and decision-making for many years. With the fast-speed development of the Internet, many people apply text mining to monitor and analyze public opinion on various issues through social media, news, and communications to guide government actions and responses.
Besides the industries mentioned above, text mining is loved by more and more fields. In the finance area, it plays the role of identifying potential fraud, while people involved in legal companies take it to find key information and relevant clauses. Whatever industry you’re in, text mining is an effective tool anyway.
Octoparse – The Best Tool for Text Mining
Before doing a project with text mining, you need to obtain raw data from somewhere. Text acquisition is the first and the most important step before text mining. However, you might find open-source data from data platforms like Kaggle. However, the datasets on such platforms have been so widely used that you are unlikely to conduct a unique project based on these sources. To solve this problem, building a scraper to extract first-time and up-to-date data from the Internet is more reasonable.
Octoparse is a no-code web scraping tool for anyone to scrape data, regardless of coding skills. It can extract various attributes of web elements, such as texts and URLs. While scraping data with Octoparse, click on your target data, and then select Text from the Tips panel. After that, you’ll grab wanted text data from websites. Or, you can use the auto-detect feature to let Octoparse scan the whole page and detect extractable text data for you. Then, you can directly preview the detected data fields and get the needed data. As a result, you will achieve sufficient text sources for text mining.
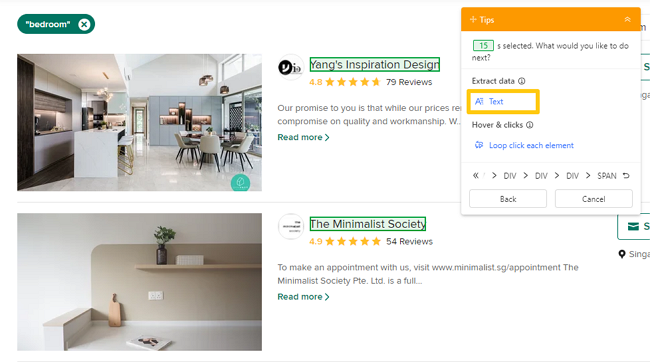
Tips:
Want to learn more about how to scrape URLs and HTML? Check HERE.
Wrap Up
Text mining transforms raw text into structured data, enabling deeper analysis and helping organizations make informed decisions. Web scraping is a necessary part of text mining because it’s the most effective way to collect text data in bulk for mining. Try Octoparse now, and dive into text mining!




