Whether you love football or not, you must be surrounded by FIFA World Cup 2022 from the 21 November. Until the champion shows up, this football passion will linger for about a month.
Just in the group stage of the World Cup, there were two significant upsets. Argentina and Germany both suffered 2-1 losses at the hands of Saudi Arabia and Japan, respectively. Although football is built for shocks, some football fans think that World Cup 2022 will surpass most people’s expectations.
Does the World Cup in 2022 “truly” defy predictions? We scraped betting odds from professional betting agencies and tried to find the answer.
Why We Scraped Betting Odds from Betting Agencies
We must first understand the reasoning behind sports betting odds. Betting odds essentially represent how individuals think the game will turn out. The more people are optimistic about a team winning a game, the more bets they will have on this team. At the same time, betting companies make fortunes by collecting a commission on losing bets. So to maximize profits, betting agencies will provide higher odds on the underdog, or hedge their best to prevent large payouts.
Every professional betting agency has a statistical model with extensive data. They are more knowledgeable than others about a team’s chances of winning a game. Therefore, by examining betting odds, we may have an idea about how much World Cup 2022 has surprised people so far.
What We Have Found
Since both shock and surprise are intangible emotions, we first established a baseline. In this instance, we characterized the game as a shock if the outcome matches the game’s greatest odds.
Many bookmakers display their real-time odds on their websites. In the meantime, some platforms will gather information from various organizations and display it all on one page. We chose the OddsPortal platform as the data source. It provides betting odds from more than 10 betting agencies and presents their average odds. We used Octoparse to collect game results and odds of World Cup 2022, 2018, and 2014.
When we were writing this article, the group stages had just finished. 14 game results throughout the group stages, which took around 29%, corresponding to the game’s highest odds, according to the scraped data. World Cup 2022 hasn’t surpassed people’s expectations much in this sense.
Let’s read data on a larger scale. Data from World Cup 2018 represents about 18.75% of games were shocks with 14.06% in World Cup 2014. Compared with these two, World Cup 2022 is more surprising, of course.
Additionally, it was simple for us to identify the game with the highest odds result. When Costa Rica defeated Uruguay in 2014, the average betting odds were 8.80; when Germany lost 2-0 to South Korea in 2018, the average betting odds were 19.05. Then, in Qatar, Saudi Arabia smashed this record. The average betting odds were 25.52 when they defeated Argentina.
How to Scrape Data from Betting Platforms
You can visit a single betting website or extract data from a variety of platforms to keep track of sports betting odds. Well-known companies like bet-at-home, 1XBET, Matchbook, etc., are excellent options. And with an easy-to-use data scraper, Octoparse, you can scrape data from all of them. You can download and install it on your device for free. If you have not used it before, you might need to sign up for a free account to log in.
In this case, we picked OddsPortal as the data source and extracted data from its game results pages. You can also use the below URL to scrape betting odds and conduct an analysis of FIFA World Cup 2022.
Target URL: https://www.oddsportal.com/soccer/world/world-cup-2022/results/#/
Step 1: Create a new task
Copy the URL and paste it into the search bar in Octoparse. Click on the Start button. Wait for the page to load in the Octoparse browser before continuing.

Step 2: Use auto-detection to select data fields
Once the page loading is completed, click “Auto-detect webpage data” on the Tips panel. After scanning the entire page, Octoparse will deduce what you want. Additionally, we will highlight any data that may be extracted from the page. You can get a preview of the data fields at the bottom and check the exact locations of the data by clicking on the name of the fields.
Web page structures can be complex in some circumstances. To examine different data fields, click “Switch auto-detect results.” You can also choose data manually or locate data using XPath to increase the correctness of the data.
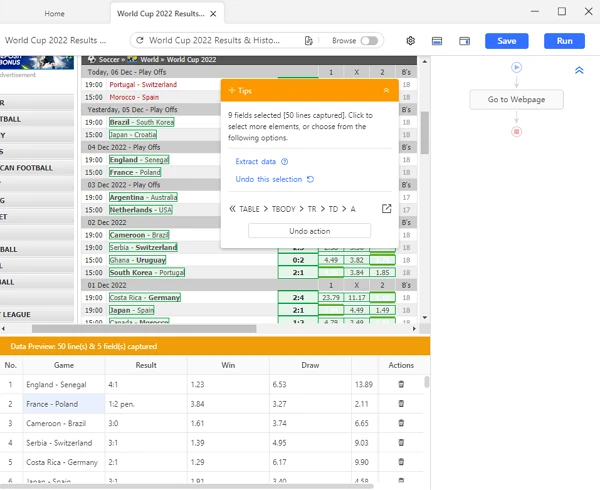
Step 3: Create the workflow
After you’ve selected all the data fields you want, click “Create Workflow.” Octoparse will then build a workflow for you. You can check the workflow on the right-hand side. By clicking on each action, you can review each step of the data scraping process. Remember the proper workflow: you should read it from top to bottom, and inside to outside in case of nested actions.
Step 4: Run the task and export the data
After making sure the workflow works well, click “Run” to launch the process. You’re able to run the task on your local device or Octoparse Cloud servers and in the Standard Mood or Boost Mood. A fast run is ideal for using your device to run. But because betting odds providers offer so much data, we strongly advise giving the job to cloud servers so they can work around the clock for you. You can export data to Excel, CSV, and JSON files after the data extraction process.
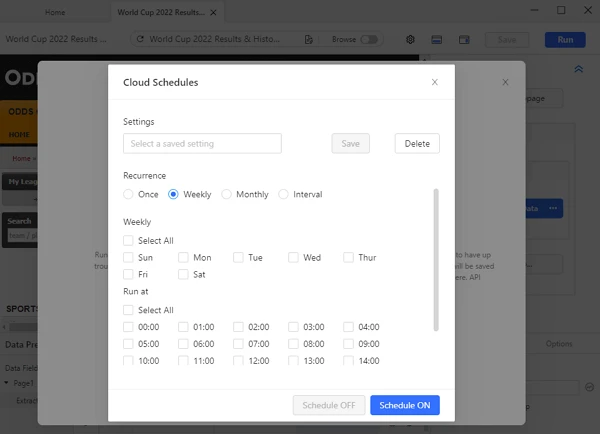
Additionally, betting data is fast-changing. You must periodically scrape data to make sure you are always in the state. Before starting the process, click “Schedule Runs” to set the recurrence details. Depending on how frequently you want to extract betting odds, choose the week, day, and time of the day you want to redo the task. If necessary, you can even choose to repeat it after a short interval of time.
Once everything is ready, Octoparse will automate scraping on schedule rather than requesting that you run the task again.
Extract with Preset Odds Portal Scraper
The Octoparse preset template is designed to simplify how you pull data from websites. While scraping data using a preset template, you can get up-to-date data by entering several required parameters. Taking Odds Portal Scraper as an example, you can get information including game title, time, final result, bookmaker, ratio, etc., by only providing the URL on Odds Portal. Check out preset templates, and grab data in mass at ease!
https://www.octoparse.com/template/odds-portal-scraper
Go Beyond the Final Game Results
Betting agencies provide odds not only on the final results of games. If you look around their pages, you can realize that you can bet on almost every detail or data of a game. Take football as an example. Agencies provide odds on which team will win the 1st and 2nd half, which player will goal first, and even how many yellow cards and corners will appear in a game. These specific details are priceless. Believe it or not, researchers also utilize it for sports analytics in addition to those who wish to make a profitable wager.
In addition to match outcomes and post-match statistics, betting odds for forthcoming games are dynamic. For example, people are more likely to bet on a team’s rival in the next game if it did not perform well in the previous game. On betting websites, the changing odds can also be followed. You should not miss it if you try to predict who will win correctly.
Similar to professional betting agencies, you can create your database or statistical model if you have access to enough data. Then you can place a low-risk wager or even go as far as to forecast the winner or the team value.
Warp-up
Now World Cup 2022 is in full swing. The following games could feature additional surprises. Data, however, always tells the truth. You can use the method in this article to employ data extraction to create a final winner prediction. It will be incredibly fascinating!
Moreover, betting agencies focus on a lot of sports and leagues. There is a lot of data that can be extracted. You can continue using the same approach to seize it and enrich your database, and finally become an expert in sports.




