As the world’s largest site for readers and book recommendations, Goodreads is at the center of reading. It’s a place for readers to track the books they’re reading, has read, and want to read. And after reading a book, readers will also share reviews there.
Goodreads was launched in January 2007 and had achieved 650,000 members in the first year. By 2022, this site has 125 million members and over 3.5 billion books shelved. Not only do readers use it to record their reading journey, but many people who are involved in the publishing, marketing, and even entertainment industry also treasure this platform as a database to observe the whole market.
In this article, we’ll introduce what data you can collect from Goodreads, and how to scrape Goodreads data without coding skills.
What You Can Scrape from Goodreads
Goodreads shows the very details of every single book on its page. Along with fundamental information like the book’s title, subtitle, genres, author, and language, it also offers more specific details like the book’s first publication information, literary awards it has won, its format, and its ISBN. We can also check the rating, number of ratings, reviews, and number of reviews on the book page. All of these types of data are available for data extraction on Goodreads.
Besides collecting data on a specific book, you can also scrape a variety of book lists from the new updates, on a certain category, and even the best books of the year. These rankings also reflect information about book qualities, the global reading trend, and reader interests.
How You Can Benefit from Goodreads Data
If you only use Goodreads as a reader, the most obvious advantage must be you’re more likely to find the right books with Goodreads. But when we talk about data, we need to think about it on a larger scale.
Understand the Market
Data from Goodreads is a valuable resource for studying the entire market. You can quickly determine which genre is the most popular and which theme is well accepted among readers using information like ratings, reviews, the number of people who wish to read, etc. It’ll help you in various aspects. For example, if you’re an editor, you’ll get an idea about what kind of books are more potential; if you’re a writer, it’ll tell you how to create a popular work to some extent.
Develop an Insight into the Audience
Goodreads members are passionate about books and reading. They’re the bullseye customers of content. Their behaviors on Goodreads are worthy to be observed, and will let you build a truthful and extensive comprehension of what they prefer to read, how they evaluate a book, and their reading habits and attitudes. You can use it for optimizing marketing strategy and targeting the right customers, especially when you’re a book publicist.
Find the Next Best-selling
Statistics from 2022 indicate that 500,000 to one million books come out annually. However, only a few can stand out and become best sellers. Goodreads has a page to present monthly new releases. This page lists the books that Goodreads members most regularly add to their shelves, along with the average rating and the total number of ratings for each new title. Collecting data from such pages, you can use it to understand what’s trending and what type of books are more likely to be the next hit. Even for the entertainment industry, when some companies seek novels to adapt as movies, Goodreads data is essential for reference.
4 Steps to Scrape Goodreads Data
This section will lead you through using Octoparse to scrape ratings and reviews from Goodreads. Octoparse is an easy-to-use and efficient tool for web scraping. Whether you have expertise in coding or not, this tool will support you extract data from the majority of online pages.
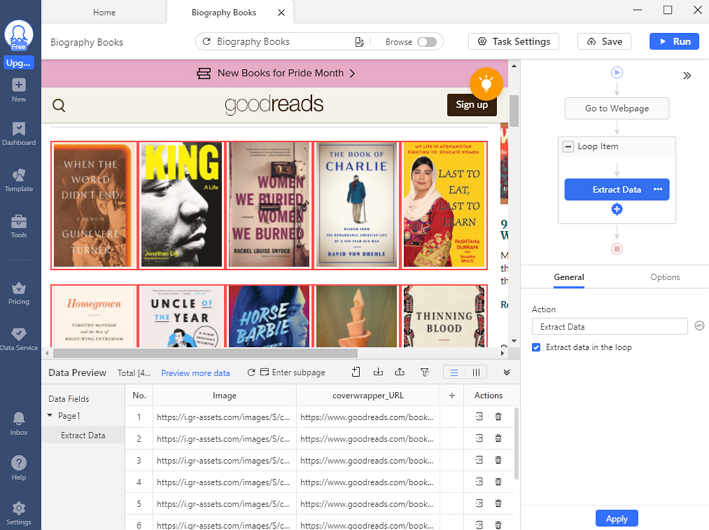
Step 1: Create a Goodreads scraper
Taking Black Holes: The Key to Understanding the Universe (2022) as an example, you can copy the target URL below and paste it into the search bar on Octoparse. Create a task by clicking “Start” after that. The target page will be loaded in Octoparse’s built-in browser in seconds. Please wait until it finishes loading before going forward.
Target URL: https://www.goodreads.com/book/show/58587868-black-holes
Step 2: Select the wanted data
Click “Auto-detect webpage data” in the Tips panel. It’ll let Octoparse scan the page to “guess” what data you want. Then Octoparse will highlight extractable data on the page so you can confirm it is what you’re looking for. So far, Octoparse has selected reviewers, reviewers’ homepages, review dates, review content, etc., automatically.
However, the detected data fields might be unwanted sometimes. You can also delete these undesirable fields on the bottom and rename data fields there to make the data a structured and clean format.
Step 3: Create and modify the workflow
Once you’ve selected all the data fields you need, click “Create workflow” to build a scraper. Then a workflow will show up on the right-hand side. You can grasp how this scraper operates by reading it from top to bottom and inside to outside (for nested actions only). You can also click on each step to see a preview of it in the built-in browser to see if it works as intended.
Step 4: Run the task and export data
Once you’ve double checked that all the data fields you wanted were selected and the workflow worked as expected, click “Run”. Then a box will show up and provide two options for running your task. You can run it on your local device or hand it over to Octoparse’s cloud servers.
There are only 25 reviews under the book Black Holes: The Key to Understanding the Universe (2022). Thus, scraping book reviews is a small project in this case. You can go ahead with running it on your personal computer because this option is ideal for task troubleshooting and quick run. By contrast, some books on Goodreads have achieved millions of reviews. If you’re going to scrape data from these pages, letting could servers process it will be more efficient.
After you pick an option, Octoparse will take care of the rest for you. Once the scraping process is done, you can export the extracted data as an Excel, CSV, or JSON file, even to a database like Google Sheets directly.
Bonus: You can also use Octoparse to scrape movie reviews from IMDB or other similar sites.
Preset template for getting Goodreads data
Another easier way you can find in Octoparse is using preset templates. With the Goodreads data scraping template, you can extract data like book title, author, reviews, and ratings easily from Goodreads by only entering a few parameters. The data sample and template can be found both in Octoparse software and website Template section, or you can click on the link below directly.
https://www.octoparse.com/template/goodreads-scraper
Wrap-up
Goodreads is a perfect place to track the publishing industry and international readership. We’ve paid attention to this platform and introduced how to scrape data from it. There are lists of websites like Amazon and its Kindle store that also offer valuable information about books and readers. With Octoparse, you can scrape data from them easily as well.