Twitter follower data is quite beneficial for marketing research and branding since it enables you to better understand the characteristics of the consumers and the motives behind their engagement with respective accounts in your domain or business.
Nearly all social media influencers are on Twitter, where you can also find their huge following lists with a mountain of data that you can use for analytics, promotion, and insight. Unlike other social media sites, Twitter actively allows people to use and do good with its public data.
Therefore, this article will assist you in how to scrape Twitter followers information with Python and no-coding methods.
Can I Scrape Twitter Followers
Yes, it is possible to scrape public information on Twitter followers using web scraping software. Numerous web scrapers have boosted the growth of big data and made it simple for users to get the data they want.
However, it would be better if you pay more attention on your local laws and rules about personal information. In other words, a scraping tool just do the “copy and paste” work for you, the final step is up to where your data use.
The next query is, “Why do we need to scrape the data?”
Well, Twitter data may be extracted for a variety of purposes, including advertisements, ventures, and other activities. Sometimes to evaluate engagement and establish competitive strategies, businesses and corporations scrape Twitter data from several of their competitor’s accounts. Therefore, using Twitter scraping software to gather relevant information in an orderly environment is more crucial.
Now, the next thing that you would like to know is how to scrape the data.
How to Scrape Twitter Followers
There are many open-source web scrapers available which enable users to create programs using its frameworks and play a significant role in the ability to scrape data quickly, easily, and completely.
These web scrapers are ideal for developers instead of people who do not have sufficient knowledge in coding or who do not like to code.
For such individuals, many non-coding web scrapers are available. Hence, scraping is no more just a developer’s expertise. These technologies are better suited for making scraping simpler for those who lack programming skills.
Now, let’s discuss scraping via the no-coding application approach and through Python Twint method.
No-Coding Method to Scrape Twitter Followers Easily
For this approach, we will use Octoparse. With this web scraping tool, you can retrieve data from any website rapidly and without programming.
It is ideal for firms of all sizes and people from different walks of life. Web information is no longer just a resource for those with tech expertise.
Octoparse allows anybody to quickly design a crawler. By offering a one-stop framework to handle all mining tasks, this software has not only improved the tasks of professional developers but has also made web data available to others who seek web page data but may not have coding abilities.
How does Octoparse work
As it mimics human-like surfing behaviors, such as visiting a website & interacting on a page component or link, it instantly collects data from web pages. Each activity in the pipeline that defines the entire extraction method represents a specific interface with the targeted page.
Octoparse is intentionally designed such that “you receive what you see”. You may utilize it to scrape any needed data as long as it is “viewable” on the web page.
It also offers sophisticated functionality to handle login, AJAX, JSON, infinite scrolling, and other issues for more complex websites.
How to scrape Twitter followers with Octoparse
Step 1: Launch Octoparse scraper and paste the target URL
Download and install Octoparse on your device to get you started. After installing, you just need to register an account for free. Now, enter the follower’s list URL in the search bar and press start to go to the targeted web page.
The next thing you need to do is to log in to your Twitter account using cookies from the current page as Twitter prohibits immediate access to follower lists. Then to save the adjustments, click Apply.
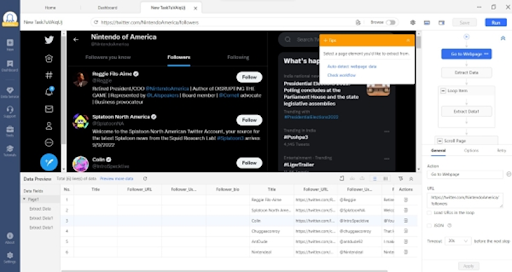
Step 2: Customize the crawler
You can use Octoparse auto-detect feature to scrape the follower data then you can remove or rename data fields that it captures or even add new custom fields as per your requirements in the data preview tab or you can just choose to scrape the data manually to create the desired workflow.
Step 3: Extract followers from Twitter
Review the workflow options and data preview tab, then save and execute the workflow. Once the task is finished, use the Export option to export the data in CSV, Excel, or another format.
Preset Twitter Account Scraping Templates
There are many scraping templates provided by Octoparse, with them, you can extract data within a few clicks. If you have already installed Octoparse on your device, you can search the keyword “Twitter” from the search bar and choose one of the search results you want. Or you can try the online Twitter Scraper template directly by clicking on the link below.
https://www.octoparse.com/template/twitter-scraper-by-account-url
Scrape Twitter Followers with Python Twint
Twint is a free Twitter scraper that collects tweets with contact information like mobile numbers and emails. It makes use of a Twitter client handle and then retrieves all of that client’s tweets including leads.
With this CLI Twitter utility, you may retrieve a client’s tweets without using API privileges. Furthermore, you may choose to just receive tweets with an email id or a contact number if that is all you require.
According to your needs, you only need to specify a few parameters in CLI, and it will take care of the rest. This application is capable of a variety of other tasks in addition to collecting tweets, including obtaining users’ most favorite tweets and their followers on Twitter.
Advantages of Twint:
- May retrieve nearly all tweets (more the Twitter API).
- Quick initial setup, anonymity and Twitter sign-up are not required.
- No restriction on the frequency.
How to use Twint get Twitter followers
First, install twint using the pip command.
Below are some CLI Basic examples:
Conclusion
I hope this article will assist you in scraping Twitter Followers data using the no-coding application Octoparse and via Python Twint. As you witnessed while using Octoparse how easily we scrapped followers’ data in just a few clicks.
Users that practice Twitter scraping may create statistics and evaluate tweet hits. This facilitates the creation of promotional posts, the development of potential organizations and webpages, and the focus on timely implementation of activities like festive periods, weddings, etc.
Web scraping is a boon for firms of all sizes as it helps them strategies their moves against their competitors and helps them evaluate their engagement with the masses in a short time.
FAQs
1. Is Twitter scraping legal?
Yes, scraping publicly available Twitter data is generally legal when done in compliance with Twitter’s terms of service and local data privacy laws. Twitter actively allows people to use its public data for legitimate purposes. However, always respect user privacy and avoid scraping personal information without proper authorization.
2. What Python libraries are best for scraping Twitter followers?
For Python-based Twitter follower scraping, Twint is a popular free library that can collect follower information without requiring API access. It allows you to retrieve user data anonymously and bypass Twitter’s API limitations. However, for users without coding skills, no-code solutions like Octoparse offer similar functionality with pre-built templates.
3. How can I automate exporting followers into an Excel file?
Most Twitter scraping tools like Octoparse support automated export to Excel format. With Octoparse, you can schedule scraping tasks and automatically export follower data to Excel, CSV, or Google Sheets.
4. What are the limitations of scraping Twitter followers manually or with tools? Manual scraping is time-consuming and prone to errors, especially with large follower lists. Tool-based scraping faces challenges like Twitter’s login requirements for accessing follower lists, infinite scrolling patterns, and rate limiting. Additionally, some scrapers may encounter IP blocking or CAPTCHA challenges during large-scale data collection.