The ever-growing demand for big data is driving more and more people to dive into the ocean of data. Web crawler plays an important role in scraping the web pages that are ready to be indexed. Nowadays, there are three major ways for people to crawl web data:
- Using public APIs provided by the websites
- Writing a web crawler program
- Using automated web crawler tools
In this post, we will discuss the 3 best free web crawlers that are friendly to beginners. Also, you can learn their alternative software available for both Windows and Mac devices, which can help you scrape much more data without coding.
3 Free Web Online Crawlers You Should Know
1. Import.io
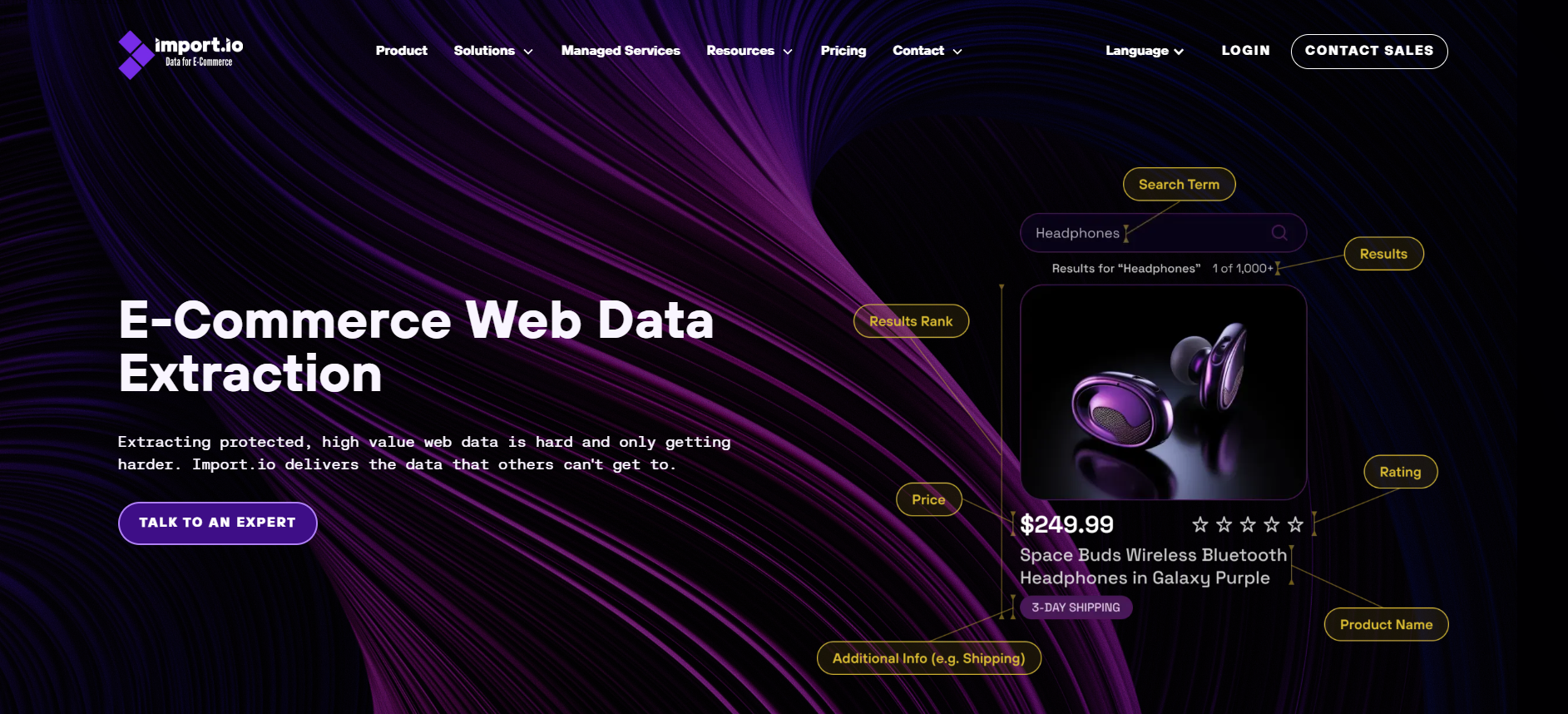
Import.io has evolved into a comprehensive data platform offering both self-service and managed website crawler solutions.
The data storage and related techniques are all based on Cloud-based Platforms. To activate its function, the user needs to add a web browser extension to enable this tool. The user interface of Import.io is easy to get hands-on with.
😊Pros of Import.io:
- Cloud-based platform, no need to run scraper locally; data stored and accessible from anywhere.
- Easy-to-use point-and-click interface with no programming required.
- Extraction from JavaScript- and AJAX-loaded content allowed.
- API access, scheduled runs for automated scraping, and integration with tools like Google Sheets and Tableau supported.
😔Cons of Import.io:
- Slower built-in page loading speed, which may affect large-scale scraping.
- Limited support for complex interactive elements such as dropdown menus, pop-ups, CAPTCHAs, or infinite scrolling.
- Less flexible in scraper logic (e.g., conditionals) compared to some competitors.
- Not as widely used or robust as tools like Octoparse when handling complex websites.
- Rate limits and query restrictions depending on subscription plans.
📖How to use Import.io:
- Sign up and create a new extractor using your target URL
- Use the graphical overlay to click and select the data fields you want to extract
- Toggle between list view and overlay view to refine your data selection
- For hyperlinks, create separate columns and use regular expressions to extract absolute URLs
- Run the scraper on multiple sample URLs to verify data accuracy
- Use output from one scraper (like URL lists) as input for detailed page scrapers Schedule & Export – Set up automated runs and download results in CSV, JSON, or Excel formats
2. Apify
Apify is a cloud platform for web scraping and automation. It helps users collect data, streamline repetitive workflows, and build custom web tools without worrying about infrastructure.
The platform includes ready-made Actors, an open-source SDK, and serverless cloud services to make projects easier to launch and scale.
The platform supports both Python and JavaScript, and developers can use their favorite libraries, such as Scrapy, Selenium, Playwright, or Puppeteer.
😊Pros of Apify:
- A powerful and flexible platform that can scrape almost any website, whether it’s a simple project or a highly complex one.
- Offers a large marketplace with over 5,000 ready-made “Actors” (scraping and automation scripts) for popular sites, saving users a lot of setup time.
- Scales easily for enterprise use with cloud infrastructure, IP rotation, and anti-blocking features that support large-scale crawling.
- Developer-friendly, with an open-source SDK, support for JavaScript and Python, task scheduling and monitoring.
😔Cons of Apify:
- The learning curve can be steep for complete beginners, especially those without technical experience.
- Pricing is based on usage credits, which may be costly or confusing for small-scale or high-volume users.
- Some users mention that customer support can be slow to resolve issues.
- Advanced features and customizations often require coding knowledge and familiarity with APIs and cloud infrastructure.
📖How to Use:
- Sign up and log in to the Apify platform.
- Pick a pre-built Actor from the marketplace or create your own scraper using the Apify SDK.
- Configure the Actor or scraper by entering input parameters (e.g., URLs, queries).
- Run it on Apify’s cloud infrastructure.
- (Optional) Schedule automated runs with the built-in task scheduler.
- Export your data or connect it to other tools using APIs, webhooks, or third-party apps.
3. Dexi.io
Dexi.io’s Cloud Scraping Service is built to make web data extraction easier for everyday users. It offers IP proxy support and built-in CAPTCHA solving to access most websites without interruption.
Data is hosted in the cloud, with APIs for monitoring and remote management. The platform also supports seamless integrations, allowing extracted data to be sent directly to storage and workflow tools such as Google Drive, Dropbox, Box, AWS, or via (S)FTP.
😊Pros of Dexi.io:
- Extraction with built-in storage and automation.
- Intuitive point-and-click editor with developer console support for creating complex extractors, including logins, form submissions, dropdowns, clicks, and pagination.
- Advanced data processing features such as transformation, aggregation, debugging, deduplication, and customizable workflows.
- Enterprise-ready with API access, real-time extraction, integrations with third-party tools, and managed service options.
😔Cons of Dexi.io:
- Pricing starts at $119/month, which may be costly for smaller businesses or individual users.
- Customer support is knowledgeable but can be slow outside standard working hours.
- Advanced features come with a learning curve and require some technical expertise.
- Less commonly featured in smaller-scale scraping tool comparisons, with more emphasis on enterprise use cases.
📖How to Use:
- Sign up and log in to the Dexi.io platform.
- Use the point-and-click editor to create an extractor robot by selecting elements directly on the target website.
- Configure advanced steps if needed, such as logins, forms, clicks, or pagination.
- Run the extractor to collect and process the data.
- Schedule automatic runs for continuous updates.
- Export the data in your preferred format or connect it to BI tools and APIs for integration.
Disadvantages of online web crawlers
Apart from those free online web crawlers mentioned above, you can also find many other reliable web crawlers providing online service. However, they have some disadvantages, as the restrictions of cloud-based services, compare to desktop-based web scraping tools.
- Limited customizability: Many online web crawlers have limited customization options, which means you may not be able to tailor the crawler to fit your specific needs.
- Dependency on internet connection: Online web crawlers are entirely dependent on internet connectivity, which means if your connection is slow or unstable, the crawler’s performance may be affected.
- Limited control over the crawling process: Online web crawlers often have limited control over the crawling process, which could lead to incomplete or inaccurate data.
- Limited scalability: Some online web crawlers have limitations on the number of URLs that can be crawled or the volume of data that can be extracted, which could limit their scalability.
Best Free Web Crawler for Windows/Mac
Octoparse is known as one of the best free web crawler, which provides both local task running and cloud-based services. You can scrape data from any web page easily with its auto-detecting mode or preset templates.
Octoparse allows customizing your data fields by dragging and dropping, and the Tips panel will advise your next steps.
Also, it has API access and IP proxies to avoid scraping blocked. Just free download and follow the simple steps below to scrape data easily.

No-code / Visual point-and-click interface: Easy to build crawlers with a visual workflow; suitable for users without programming skills.
Cloud extraction & scheduling: Supports cloud-based runs, parallel extraction, and scheduled scraping — useful for large datasets and repeated works.
Handles dynamic content: Can scrape AJAX/JavaScript-driven sites and paginate, scroll, or interact with page elements.
Data export flexibility: Multiple export formats (CSV, Excel, JSON, databases, API/webhook) for easy integration into workflows. Octoparse can export up to 10K data rows per task, and even allows concurrent cloud processes for advanced plans.
Built-in data cleaning & parsing: Basic transformation options (field extraction, AI regex tool, XPath) to structure results before export.
IP rotation / proxy support: Options for using proxies to reduce blocking (depending on plan).
How to scrape data from any website for free with Octoparse
Step 1: Open the webpage you need to scrape and copy the URL. Paste the URL to Octoparse and start auto-scraping.
Step 2: Customize the data field from the preview mode or workflow on the right side.
Step 3: Start scraping by clicking on the Run button. The scraped data can be downloaded as Excel to your local device.
You can find all tutorial from Octoparse Help Center, or find the customer service if you have any questions.
What is a Website Crawler (Website Crawler vs Web Scraper)
A website crawler is an automated program that systematically browses the internet by following links from page to page, collecting and indexing content along the way.
It is like a digital librarian that never stops reading—it starts with a list of web addresses and methodically explores connected pages to build comprehensive maps of website structures.
However, website crawler and web scraper are two different things. Crawling is the technical term for automatically accessing a website and extracting data using a software program. While web scrapping doesn’t appear to be the case.
Website crawler versus web scraper functionality:
- Website crawlers automatically discover content by following hyperlinks, creating site maps while collecting data across interconnected pages.
- Web scrapers extract specific information from targeted pages without discovering or navigating any links.
- Crawlers prioritize exploration and indexing; scrapers focus on targeted data extraction.
Website crawler tools operate through systematic processes:
- Keep a list (or queue) of URLs to visit
- Check robots.txt files to see which pages they’re allowed to crawl
- Fetch each page’s content, and then extract both the data and new links from it
- Any new links found are added back to the list for crawling later
More advanced site crawlers can also handle websites that rely heavily on JavaScript, monitor whether content has changed or been updated, and follow politeness rules—like slowing down requests—to avoid putting too much load on a server.
Search engines like Google rely on crawlers to discover and index billions of web pages. Beyond search, crawlers also power SEO auditing, competitive analysis, and content monitoring. Modern website crawler tools provide users with practical features such as:
- Automatically extracting data from entire websites or multiple pages
- Handling JavaScript-heavy sites for accurate data capture
- Saving and processing data in the cloud
- Exporting results to formats like Excel, CSV, or JSON
- Using built-in proxy rotation and CAPTCHA solving to avoid blocks
The best webpage crawlers strike a balance between ease of use and advanced capabilities, making reliable data collection possible for marketers, researchers, and anyone who needs structured web data.
How Free Web Crawler Helps
A free website spider is designed to scrape or crawl data from websites.
We can also call it a web harvesting tool or data extraction tool (Actually it has many nicknames such as web crawler, web scraper, data scraping tool, and spider) It scans the webpage for content at a fast speed, and then harvests data on a large scale. One good thing that comes with a free online web crawling tool is that users are not required to process any coding skills. That said, it supposes to be user-friendly and easy to get hands-on with.
A free online web crawler helps people gather information in a multitude for later access.
A powerful free online web crawler should be able to export collected data into a spreadsheet or database and save them in the cloud. As a result, extracted data can be added to an existing database through an API. You can choose a free website crawler tool based on your needs.
Final Thoughts
Now, you have learned about the best free online web crawlers, and the best alternative – Octoparse for Windows and Mac if you’re not satisfied with online tools. Just choose the most suitable one according to your scraping needs.
FAQs about Website Crawler Tool
- How to crawl a website without getting blocked?
Use website crawler tools with built-in proxy rotation like Octoparse, which offers IP rotation and anti-detection features. Implement random delays between requests, rotate user agents, and respect rate limits. Octoparse includes intelligent blocking avoidance specifically designed to handle modern website protections, while tools like Apify and Dexi.io also provide similar website crawler tools capabilities.
- Which free crawler gives the most detailed SEO audit in one run?
Screaming Frog SEO Spider. Its free version crawls up to 500 URLs and delivers detailed insights on technical SEO, meta tags, redirects, and broken links—more comprehensive than other free SEO crawlers.
- How does Screaming Frog’s five-hundred-URL free limit compare to Alpha Crawler?
Screaming Frog limits you to 500 URLs but provides in-depth SEO reporting. Alpha Crawler allows unlimited URLs but offers lighter analysis. Pick based on whether you need depth or scale.
- How do I integrate crawler data with existing SEO analytics platforms?
You can connect crawlers like Screaming Frog directly with Google Analytics, Google Search Console, and PageSpeed Insights APIs to combine crawl data (URLs, errors, metadata) with traffic and performance metrics. This gives you a fuller SEO view in one report.
Alternatively, export crawl results (e.g., CSV) and import them into analytics tools or dashboards like Looker Studio for integrated reporting. If direct integration isn’t available, APIs and scripts can automate data merging between crawlers and analytics platforms.