Anti-Scraping Techniques are often used to block web scraping bots and prevent their web info from being openly accessed.
While web scraping has been an effective and low-cost solution for businesses to fulfill their data acquisition needs, there is a non-stop coding war between spiders and anti-bots. And this is mainly because web scraping, if not done responsibly, can slow down the website or possibly crash it in the worst scenario. This is why some websites use different kinds of anti-scraping measures to discourage scraping activities.
In this article, I have listed the five most common anti-scraping techniques and how they can be avoided.
1. IP
One of the easiest ways for a website to detect web scraping activities is through IP tracking. The website could identify whether the IP is a robot based on its behaviors. when a website finds out that an overwhelming number of requests had been sent from one single IP address periodically or within a short period of time, there is a good chance the IP would be blocked because it is suspected to be a bot. In this case, what really matters for building an anti-scraping crawler is the number and frequency of visits per unit of time. Here are some scenarios you may encounter.
Bypassing IP address-based blocking
Case #1: Making multiple visits within seconds. There’s no way a real human can browse that fast. So, if your crawler sends frequent requests to a website, the website would definitely block the IP for identifying it as a robot.
Solution: Slow down the scraping speed. Setting up a delay time (e.g. “sleep” function) before executing or increasing the waiting time between two steps would always work.
Case #2: Visiting a website at the exact same pace. Real human does not repeat the same behavioral patterns over and over again. Some websites monitor the request frequency and if the requests are sent periodically with the exact same pattern, like once per second, the anti-scraping mechanism would very likely be activated.
Solution: Set a random delay time for every step of your crawler. With a random scraping speed, the crawler would behave more like how humans browse a website.
Case #3: Some high-level anti-scraping techniques would incorporate complex algorithms to track the requests from different IPs and analyze their average requests. If the request of an IP is unusual, such as sending the same amount of requests or visiting the same website at the same time every day, it would be blocked.
Solution: Change your IP periodically. Most VPN services, cloud servers, and proxy services could provide rotated IPs. When requests are being sent through these rotated IPs, the crawler behaves less like a bot, which could decrease the risk of being blocked.
Here is the tutorial on how to set up proxies in Octoparse. By rotating the IP addresses, you can greatly avoid being blocked.
2. Captcha
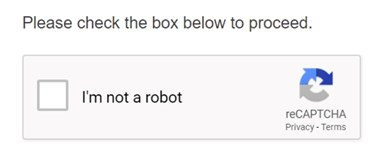
Have you ever seen this kind of image when browsing a website?
1. Need to click to confirm “I’m not a robot”
2. Need to select specific pictures
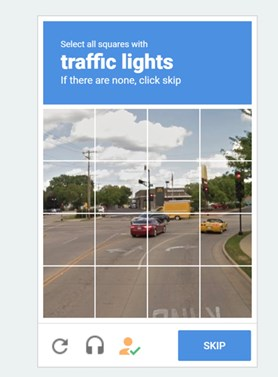
3. Need to type in/select the right string

What is a captcha?
These images are called Captcha. Captcha stands for Completely Automated Public Turing test to tell Computers and Humans Apart. It is a public automatic program to determine whether the user is a human or a robot. This program would provide various challenges, such as degraded images, fill-in-the-blanks, or even equations, which are said to be solved by only a human.
This test has been evolving for a long time and currently, many websites apply Captcha as an anti-scraping technique. It was once very hard to pass Captcha directly. But nowadays, many open-source tools can now be applied to solve Captcha problems though they may require more advanced programming skills. Some people even build their own feature libraries and create image recognition techniques with machine learning or deep learning skills to pass this check.
How to solve Captcha while web scraping?
It is easier to not trigger it than solve it.
For most people, the easiest way is to slow down or randomize the extracting process in order to not trigger the Captcha test. Adjusting the delay time or using rotated IPs can effectively reduce the probability of triggering the test.
If you’re using Octoparse, we’ve listed several methods to help you solve the CAPTCHA, check them out.
3. Log in
Many websites, especially social media platforms like Twitter and Facebook, only show you information after you log in to the website. In order to crawl sites like these, the crawlers would need to simulate the logging steps as well.
After logging into the website, the crawler needs to save the cookies. A cookie is a small piece of data that stores browsing data for users. Without the cookies, the website would forget that you have already logged in and would ask you to log in again.
Moreover, some websites with strict scraping mechanisms may only allow partial access to the data, such as 1000 lines of data every day even after log-in.
Your bot needs to know how to log-in
1) Simulate keyboard and mouse operations. The crawler should simulate the log-in process, which includes steps like clicking the text box and “log in” buttons with the mouse, or typing in account and password info with the keyboard.
2) Log in first and then save the cookies. For websites that allow cookies, they would remember the users by saving their cookies. With these cookies, there is no need to log in again to the website in the short term. Thanks to this mechanism, your crawler could avoid tedious login steps and scrape the information you need.
3) If you, unfortunately, encounter the above strict scraping mechanisms, you could schedule your crawler to monitor the website at a fixed frequency, like once a day. Schedule the crawler to scrape the newest 1000 lines of data in periods and accumulate the newest data.
4. UA
UA stands for User-Agent, which is a header for the website to identify how the user visits. It contains information such as the operating system and its version, CPU type, browser, and its version, browser language, a browser plug-in, etc.
An example UA: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11
When scraping a website, if your crawler contains no headers, it would only identify itself as a script (e.g. if using Python to build the crawler, it would state itself like a Python script). Websites would definitely block the request from a script. In this case, the crawler has to pretend itself as a browser with a UA header so that websites could provide access to it.
Sometimes website shows different pages or information to different browsers or different versions even if you enter the site with the same URL. Chances are the information that is compatible with one browser while the other browsers are blocked. Therefore, to make sure you can get to the right page, multiple browsers and versions would be required.
Switch between different UA’s to avoid getting blocked
Change UA information until you find the right one. Some sensitive websites which apply complex anti-scraping techniques may even block access if using the same UA for a long time. In this case, you would need to change the UA information periodically.
5. AJAX
What is AJAX?
AJAX stands for Asynchronous JavaScript and XML, which is a technique to update the website asynchronously. Briefly speaking, the whole website doesn’t need to reload when only small changes take place inside the page. Today more websites are developed with AJAX instead of traditional web development techniques.
How could you know whether a website applies AJAX?
A website without AJAX: The whole page would be refreshed even if you only make a small change on the website. Usually, a loading sign would appear, and the URL would change. For these websites, we could take advantage of the mechanism and try to find the pattern of how the URLs would change. Then you could generate URLs in batches and directly extract information through these URLs instead of teaching your crawler how to navigate websites like humans.
A website with AJAX: Only the place you click will be changed and no loading sign would appear. Usually, the web URL would not change so the crawler has to deal with it in a straightforward way.
How to handle AJAX in web scraping?
For some complex websites developed by AJAX, special techniques would be needed to find out unique encrypted ways on those websites and extract the encrypted data. Solving this problem could be time-consuming because the encrypted ways vary on different pages.
If you could find a browser with built-in JS operations, then it could automatically decrypt the website and extract data. Octoparse is a powerful web scraping tool that can help you deal with AJAX with just point and click, no code needed, try it now.
With all that said, web scraping and anti-scraping techniques are making progress every day. Perhaps these techniques would be outdated when you are reading this article. However, you could always get help from us, from Octoparse. Here at Octoparse, our mission is to make data accessible to anyone, in particular, those without technical backgrounds. As a web-scraping tool, we can provide you with ready-to-deploy solutions for all these five anti-scraping techniques. Feel free to contact us when you need a powerful web-scraping tool for your business or project.




