Almost every website we browse nowadays is written in HTML. HTML code contains text, images, links, etc., that we see and read in a web browser. If you can scrape HTML code from any website, let’s say you can grab almost everything you want on a page. In this post, we’ll walk you through how to scrape HTML source code with Octoparse and how to locate elements in HTML files.
What is HTML?
HTML (HyperText Markup Language) is the standard markup language used to create and design web pages. It provides the structure and content for web pages, using a system of tags and attributes to define elements such as headings, paragraphs, images, links, etc. With HTML, developers can construct organized and approachable content for browsers to display. It also forms the basis for providing an engaging and interactive web experience.
Why HTML Scraping is Important
Everything you read and see on a website can be found in its HTML file. In various scenarios, people use HTML files for different purposes, such as offline access, data preservation, content analysis, content reuse, etc. Scraping HTML files of websites, in this term, is a useful practice because of its convenience and efficiency.
Offline access
When you have HTML files, you can access the websites even if you’re offline. Scraping HTML files offers convenience and flexibility that allow you to get uninterrupted access to crucial information to analyze and cross-reference website content without the constraints of real-time browsing. In addition, by storing HTML files on your local devices, you can reduce the need for repeated online visits and then conserve bandwidth and server resources.
Archiving and data preservation
Websites are fast-changing, not only in content on the pages but also in their structures. If you want to save a copy of the original content as it appeared on the websites at a specific point in time, scraping HTML can be your best helper. It allows you to create archives of web pages, preserving content that may change or be removed from the live websites over time. Such original content and data are valuable for research, verification, and evidence purposes.
Content analysis and reuse
Data on websites has played an essential role in content analysis for decades. Scraping HTML code allows you to examine the structure, metadata, and text content of web pages, and apply this information for in-depth content analysis, which can provide insights for SEO optimization, content auditing, and competitive analysis. Also, you can extract and reuse specific content, such as text, images, links, etc., to create derivative works, summaries, or re-purposing information for different contexts after extracting HTML files.
Education purpose
Students, developers, and learners can benefit from scraping HTML source code. For example, developers can analyze scraped HTML files to learn how browsers structure and render web pages. That’s a great opportunity for them to practice coding skills. Also, scraping HTML code can be applied to various disciplines, including computer science, digital humanities, social science, etc., to promote collaboration between fields of study. Students can conduct research projects, gather information from multiple sources, and analyze such data to present findings in academic or scientific formats.
Based on your specific needs, HTML files can aid in many other aspects, including web development, debugging processes, performance testing, etc., besides what we mentioned above. Whether you’re involved in web development, content creation, or marketing, scraping HTML code can be fundamental for your job.
Scrape HTML Source Code Using Octoparse
Saving a page into an HTML file is easy. You just need to right-click and select “Save as” on the page. But scraping pages and saving them as HTML files in bulk? It’s nothing like this. You’ll need the help of web scraping tools to make it happen.
Octoparse is a no-code solution to scrape HTML code among websites and save them as files in minutes. Download Octoparse for free and install it on your device first, then sign up for a new account or log in with your Google or Microsoft account. After that, you can start your journey of scraping HTML code with Octoparse’s powerful features!
Preset HTML Scraper – the most effortless way
To simplify and speed up web scraping, Octoparse Web Scraping Templates are designed for anyone to extract data with zero setups. With preset scrapers, you can get data from the most popular websites worldwide.
HTML scraper is a preset template with a focus on scraping website HTML source code. While scraping HTML code with it, you need to enter a list of URLs of websites that you want to save as files, then click Start. After that, you’ll get structured data, including the original URL, page title, and source code.
https://www.octoparse.com/template/html-scraper
Build an HTML code scraper in easy steps
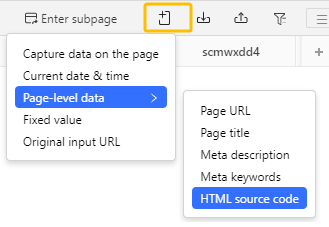
Octoparse also simplifies the process of setting up customized scrapers. In general, it only takes four steps to build a scraper using Octoparse to extract wanted data from websites. Along with the Auto-detect feature and AI, your efficiency in scraping data is increasing. When it comes to scraping the HTML code of your targeted pages, go to the Data Preview panel at the bottom, click Add Custom Field > Page-level data > HTML source code. After that, you can grab the HTML code of the website.
How to Match Wanted Elements In HTML Files
Well, reading every single word in HTML files to find the elements you need is feasible but time-consuming and tedious. Don’t worry, some tools can help remove information we don’t need and extract wanted data from HTML files.
Regular expression (RegEX)
A regular expression is a sequence of characters that defines a search pattern. You can use it to match strings within text based on certain patterns or rules among HTML files. For example, you can use nearby characters to locate your wanted texts and write RegEx to extract specific info like email addresses or URLs from HTML files. Octoparse also provides a free RegEx tool to generate regular expressions for scraping data.
XPath
XPath (XML Path Language) is a query language for selecting nodes from XML documents. It’s also commonly used to navigate through elements and attributes in HTML documents. You can apply this tool to pinpoint specific elements based on their structure, attributes, or content. XPath is particularly useful when working with structured documents like HTML, where elements are nested within one another. Most importantly, the XPath syntax is simple and easier to read and write.
CSS selector
CSS selectors are also a good choice for web content extraction. It selects an HTML element by document.querySelector() and document.querySelectorAll () selects a group of HTML elements with the same characteristics. The syntax of CSS Selector is similar to XPath syntax. However, not all programming languages support a CSS selector library.
Wrap Up
HTML code is valuable for data analysis. Scraping the HTML source code of websites can provide the raw materials you need for market research that will contribute to data-driven decisions and more informed strategies. Try Octoparse now, transform websites into structured forms, and make the most use of HTML code!




