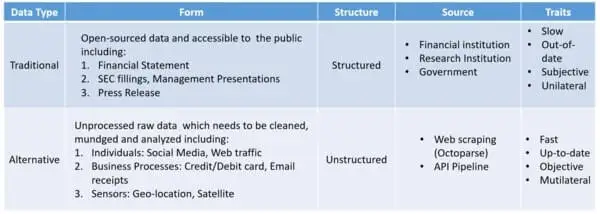
What is alternative data?
Alternative data is often perceived as big data or “exhaust data“, owing to its scale and complexity. These data sets are generally less accessible and structured than traditional datasets. Alternative data opens doors to unique and timely insights which weren’t available through traditional data sources.
One of the early adopters of alternative data is the hedge funds which took that data and incorporate it into their investment models. The use and analysis of alternative data help them detect unforeseen risks and discover potential investment opportunities. Today, in the era of information explosion, the usage of alternative data has fastly expanded into various industries.
So, why is alternative data so tempting?
Let’s make a long story short. Thasos, a mobile data provider, collected trillions of geographic coordinates emanated from smartphone devices in Tesla’s factory and found the overnight shift increased by 30% between June to October in 2018. The significant swollen of overnight shift indicated the boost Tesla Model 3 production. Thasos then inferred that Tesla’s stock price would rise. Just as expected, Tesla Model 3 production had been doubled, and its share increased by 9.1%. What Thasos used to help traders to predict stock moves is alternative data. This is a good example of when the data doesn’t necessarily look relevant can be a crucial strategic insight.
Besides geo coordinates from smartphone devices, there are many other alternative data depending upon the specific industry, such as information being shared when people use an app, credit/debit card transaction data, patent data for a tech company, government contracts, and more. According to a study, there are 482 datasets in 24 categories that have been identified in 2017.
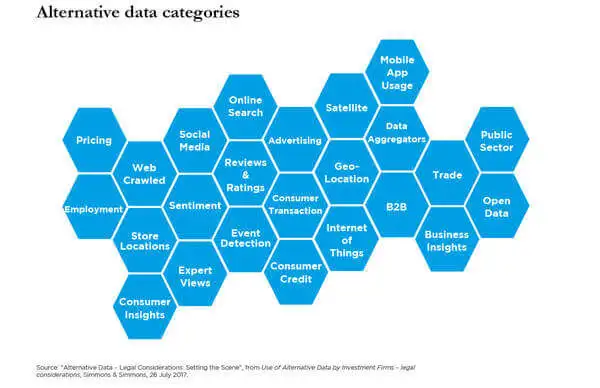
Some of the most popular types of alternative data are:
- Web-scraped Data – Data extracted from public websites. Web data can usually be extracted through the use of spiders/web crawlers. Some of the most sought-after data include commercial data (product information, prices, etc), job listings, real estate data, and more.
- Web Traffic – User visit time, user population, and user activities on webpages. These data can help marketers to shift consumer buying decisions online.
- Geo-location – Satellite image data on parking lots of a local retail store to measure the local economy.
How to get Alternative Data
Alternative data can be hard to get as it is genuinely less readily and less structured. While the number of alternative data providers springs up in the recent decade, it can still be quite challenging for businesses to get a large volume of data from various sources due to the following reasons,
- High fees – It is expensive to get valuable data. As Mr.Skibiski, the founder of Thasos concluded that some clients even pay more than $1 million a year.
- Long-time – Some of the alternative data required a longer period. For some companies, they don’t have the capital to fund for the whole duration.
- Data values – Management is not sure of the potential assets that data can bring. Abruptly following the trend may leave the business in debt.
- Yet, many people still have concerns over the legal implication of web scraping. Up to now, there is no regulation that opposes the act of web scraping, yet there is ethical guidance we should follow.
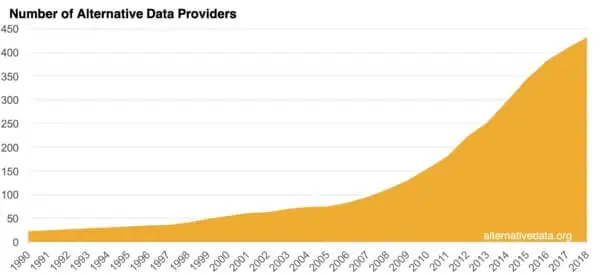
From: alternativedata.org
Currently, the most approachable solution at the moment is through web scraping. For a business with budgets, web scraping is a cheap alternative to get data. And the risk of inaccuracy is much lower than second-hand data from the data source provider. Web scraping automates the process of data extraction that allows you to scrape the data in the way you want.
To better illustrate how web scraping helps to get alternative data, I will take the housing market as an example. The goal here is to extract data scientist salaries in Seattle and relates them to the housing market. And then we can take a wild guess about the next prospering area for the housing market. (Check out this video to build a crawl to scrape job boards)
- First, launch a new project using Octoparse with the URL we got from glassdoor.com with the search result of a data scientist in Seattle
- Second, set a paginate so we can extract all job listings from all pages.
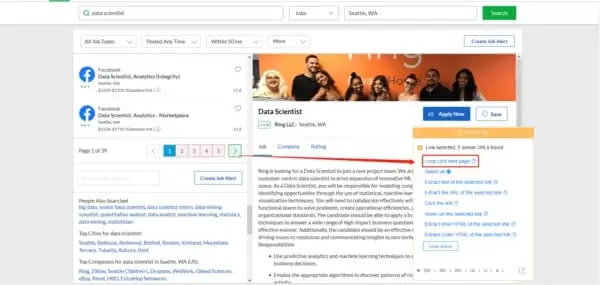
- Third, select the first job listing on the page. Then follow the Action Tip, and click “Select All Sub-element” to define extraction fields. Octoparse will select all data fields in the same pattern. I then follow the guide on the Action Tip and click the “Select All” command to confirm the selection. The selected field will turn green if it has been successfully selected.
- Fourth, Click the “Extract Data” command.
Now we get the data, and I use Tableau to visualize the data. The template I use is “Histogram”. For this example, we are going to graph the salary range for a data scientist in Seattle.
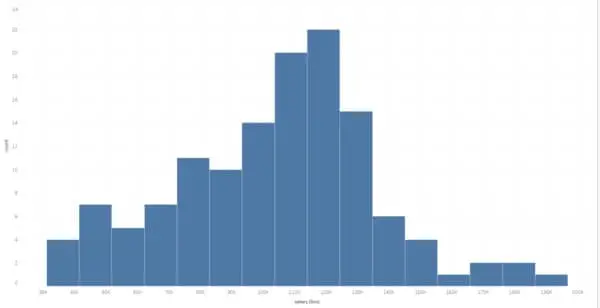
Most data scientists made around $120k. Can they afford a house in the Seattle area? According to Zillow’s affordability calculator, a $120k salary maker can afford a $520k house. However, a median-price single-family house in Seattle costs $685k. While feeling a little burdened, they can turn to suburban areas like Renton where the average price for a single-family house is around $500k. As a result, Renton is likely to get more popular for $120k makers as they are looking for a less pricy house in the Seattle-Bellevue area.
Lastly, the tool that I’ve always been using is Octoparse. It is a reliable web scraping provider that has a long history to provide world-class service to Fortune 500 companies. It also provides intelligent web scraping software that doesn’t require any coding skills. In this scenario, you can build your web crawler to scrape the data from selected sources and integrate it into your database via API.




