For personnel who are actively looking for flight or hotels with low prices for traveling to other places, or for businesses who want to track prices of flights or any types of travel accommodations for maintaining their competitive edge, Octoparse works great to effortlessly collect data based on different filters without manual searches.
A real-life example from one of our users who was trying to scrape data from booking.com and had tried various solutions for pagination, starting with the next bottom, X-path and X-path following siblings, open in the same window or a new tab, etc. But unfortunately the loop in the crawler created stopped after the first two maybe three pages and then duplicates itself. He created two crawlers which should have received +50 and +70 data records respectively but only received around 18 unique values. He would like to add more information and scrape the data through the cloud once these crawlers work properly on online booking sites.
After we got his two Octoparse crawlers, we checked out the crawlers and found out that his issue is caused by the X-path for the pagination.
We replied him back saying:
“ … I’ve checked out the attachments.
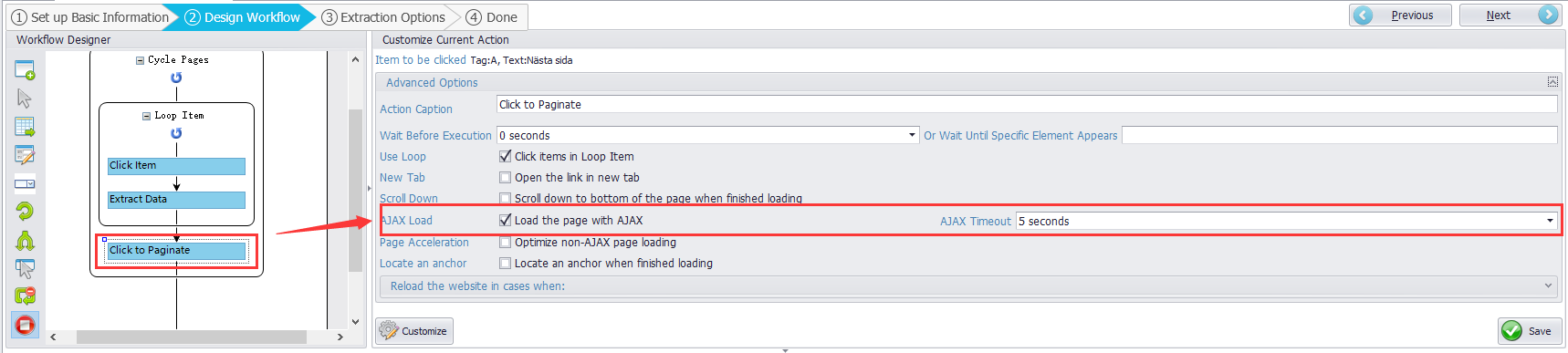
The XPath of the pagination link is incorrect and the link uses the AJAX technique. (When you click the link, the page doesn’t reload)
The correct XPath will be: //*[text()=’Nästa sida’]
And you need to set up ‘AJAX Load’ of ‘Click to paginate’ as well. See the screenshot below.
I attached the corrected tasks. Please kindly check out. …”
He replied,
“Thank you for your support.
I just tried the paginate-booking.com_fixed.otd attached as received it and again exported paginate-booking.com_Copy NEW.otd.
Unfortunately, it seems as if it still has problems.
It loads following pages but doesn’t seem to ever finish and after a while it starts generating duplicates, see attached print screens and xls-files. …”
We opened the website he wanted to scrape and it was very slow on our computer.
Because Local Extraction will be affected by the local machine situation. The differences between ‘Local Extraction’ and ‘ Cloud Extraction’ are scraping speed and IP addresses. So we switched to Cloud Extraction, using the same crawler, and collected the data correctly. The crawler worked fine, and no duplicate data in the output.
Then the user upgrades to a paid subscription plan and use our Cloud Extraction to retrieve the data on booking.com.




