If you try to pull some data off a website and hit a wall, you are not alone. It happens to the best of us. When it comes to digging for insights to deepen your business analysis or just trying to grab some useful info, web crawling can feel like a minefield. Even with all the cool tools and programming tricks we have today, getting the data isn’t always successful. Pesky blocks keep popping up, each one different from the last. But don’t worry! In this article, we’re sharing the top 9 tips to help you dodge those blocks and make your web crawling smoother. Or, if you prefer, you can entrust this job to us!
Configure Your User Agent
First and foremost, dress right.
Setting your user agent is no different than wearing the right outfit to a party. You want to blend in, not stick out! You don’t show up to a formal dinner in your gaming t-shirt, right? So when you crawl a website, do tell them your identity or act like one who has the invitation card in hand. The user agent is your invitation card. It tells the host your operating system, software, and its version. A good user agent, or HTTP request header, should not be too generic or obviously related to a bot. So you would need some popular user agent string here to imitate the latest version of Chrome or Firefox.
Normally, below is what a real user agent string looks like:
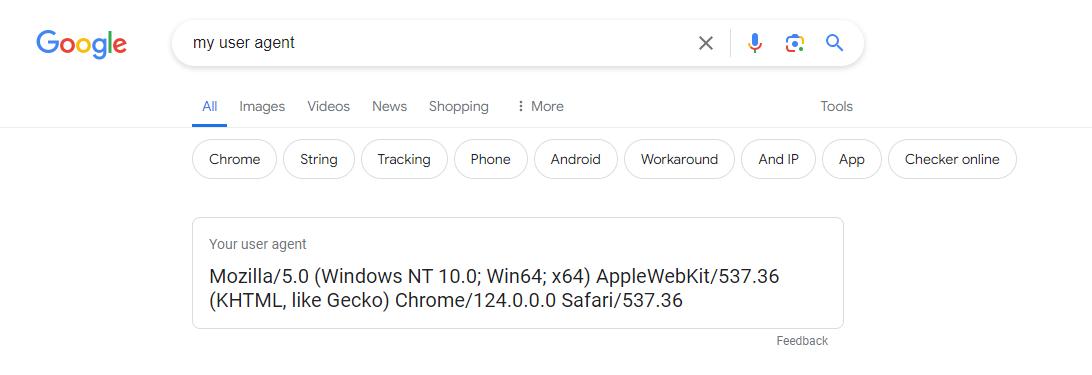
It’s also recommended to include other headers like Accept-Language and Referer to mimic a real user’s browser session further.
Here are some examples of how you can do this using Python’s requests library:
In this example:
User-Agentis set to mimic the Chrome browser on Windows 10.Accept-Languageindicates the preferred languages for content negotiation.Refererspecifies the URL from which the request originated.
Also, try to use the latest user agent because if browsers like Google get updated, user agents will be different. If you don’t refresh your crawlers’ user agents over time, they’ll raise more suspicion as the browsers evolve. It would be even wiser to change your user agent every few requests, so you don’t raise the scraping alarm. Some user agent providers like Octoparse offer auto-switch user agent(UA) features. Users can switch their UA at a desired interval and configure their UA according to their needs.
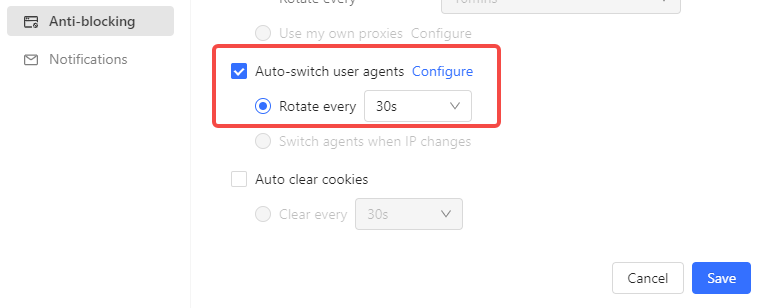
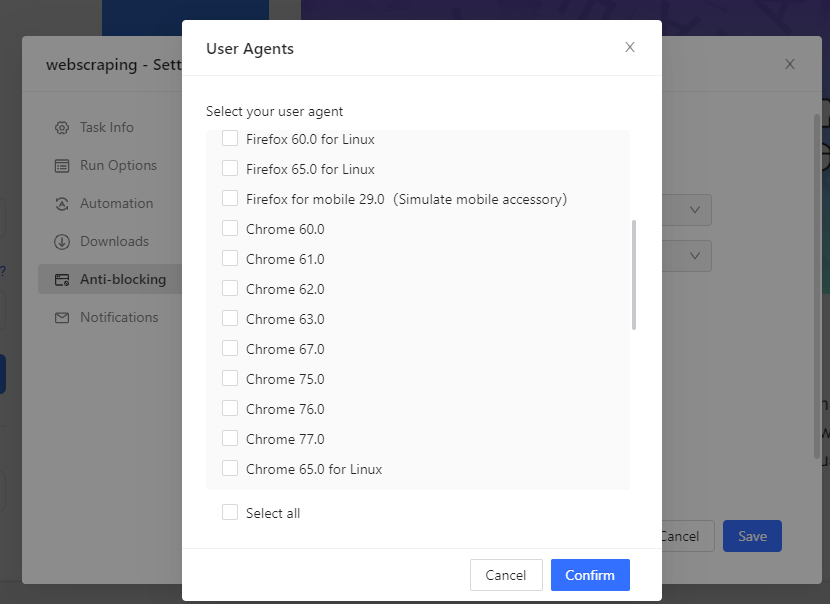
Scraping Pattern and Speed
Several requests per second and last 24 hours? No human being would ever be able to do that I am afraid. So do remember to set an interval between your requests. Or even add more actions while navigating through the website. Some automatic scraper enables “wait before action” to make your scraping movement more natural.
Proxies and IP Rotation
A proxy is an intermediary standing between your scraping bot and your target websites. It enables you to visit sites that have geo-restrictions that your original IP address is not allowed to otherwise. Also, it can protect your IP from being detected and blocked.
There are several kinds of proxies. Among them, residential proxies and data center proxies are most suitable. The former is perfect for real user disguise while the latter is more suitable when the scraping scale is large.
A quick check on all proxy definitions and real-life applications:
- Residential Proxy: They are the ideal proxies for web crawling as they use IP addresses from regular homes, which makes server harder to tell if you are a bot. In this way, you can lower your chance of being detected as suspicious and blocked.
- Datacenter Proxy: These proxies come from servers in data centers, not homes. So although they’re fast, they may not be as good at hiding your identity as residential proxies.
- Web Proxy: A web proxy is like a middleman for internet browsing. It helps you access websites and can sometimes hide your identity. For example, schools or offices often use web proxies to control what websites students or employees can access. It’s like having a filter on the internet.
- HTTP Proxy: This type of proxy is specifically for web browsing. It can save copies of web pages to make them load faster and provide some security. A company might use an HTTP proxy to speed up web browsing for employees. The proxy saves copies of frequently visited websites, so they load faster for everyone.
- HTTPS Proxy: Similar to an HTTP proxy, but it handles secure website connections (like when you see “https://” in the URL). When you shop online and see “https://” in the URL, that’s a secure connection. An HTTPS proxy helps ensure that your online shopping is safe.
- SOCKS Proxy: A SOCKS proxy can handle different types of internet traffic, not just web browsing. For example, gaming. Gamers sometimes use SOCKS proxies to reduce lag in online gaming.
- Transparent Proxy: This kind of proxy works quietly in the background without you needing to set it up. It can speed up internet access and sometimes block unwanted content. Internet service providers (ISPs) often use transparent proxies to speed up internet access for their customers. They cache web content, so popular websites can load faster.
- Reverse Proxy: Just imagine a reverse proxy as a bouncer for websites. It directs internet traffic to the right servers and can add extra security features. Large websites like Amazon or Netflix use reverse proxies to handle incoming web traffic, which can distribute the load across multiple servers, ensuring the website stays fast even during high traffic times.
It’s still not enough to have a proxy in disguise. You would need to rotate your IP to avoid making too many requests using just one IP, which is highly impossible for a normal user. An ideal proxy service has many IPs included. So rotate them as often as possible. It will lower your chance of being detected as a robot.
For proxy service and IP rotation, you can check out some scraping software that offers steady and safe built-in residential proxies, which enable you to rotate your IP within clicks.
CAPTCHAs Solving
When your crawling behaviors become predictable with regular patterns and fast requests, website servers will send CAPTCHAs to check if you are a robot.
Image clicking is now the most common technique to detect. Though easy for human beings, your crawler will not be able to crack it. At least for now.

That’s when you need CAPTCHAs Solving Service. Some point-and-click web crawlers can solve three kinds of Captcha automatically: hCaptcha, ReCaptcha V2, ReCaptcha V3, and ImageCaptcha., and do it easily.



Use a Headless browser
Sometimes, user agents are not enough in disguise as real users. Servers, where your requests have been sent, will also detect things like the extensions, fonts used, and cookies of your browser, which may be a headache to set up because you don’t really use this virtual browser. In this case, you might need tools like headless browsers to navigate. A headless browser is a browser without a graphical user interface(GUI). To put it another way, you cannot see any page output like what Google offers you when you use a headless browser, but it can still navigate webpages and interact with the pages for you like a real user and in the meantime, collect the target information, which saves you the muscle building and focus on the skeleton. Also, when you encounter sites that heavily rely on JavaScript, a headless browser is here to help too. Tool suites like Selenium can offer such a service.
Honeypot Traps
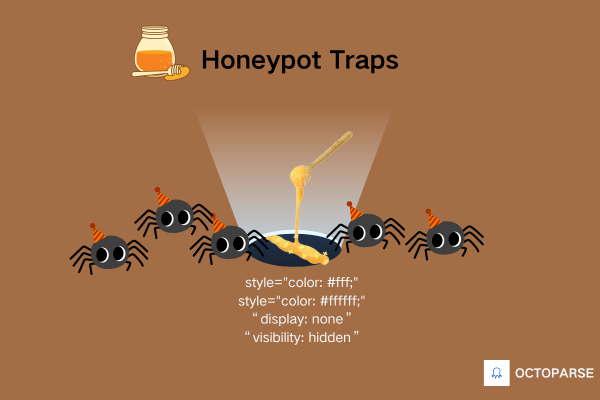
Some websites are pretty smart in crawler detection. They know crawlers collect links, so they put a link trap that is invisible to users but will be seen by crawlers. Link traps might look the same color as the webpage background, and have attributes like style="color: #fff;" or style="color: #ffffff;". Or they might be hidden with CSS properties like “display: none” or “visibility: hidden”. Check these attributes and avoid them while scraping would help you go under the radar.
Scraping Google’s Cache
If you exhaust all the methods mentioned above, don’t lose hope. There’s still a way to crawl the cache of the website instead. Scraping Google’s cache is extracting data from the cached version of a webpage that Google stores in its servers. This can be a great help in web scraping when you encounter difficulties accessing the live version of a website or when you want to retrieve historical data that might no longer be available on the live site.
To do this, first, you need to understand Google’s Cache URL Format.
- Google’s cache URLs follow a specific format. For example, the cached version of a webpage can be accessed by adding “cache:” before the URL.
- So, if the original URL is
https://example.com/page, the cached version would behttps://webcache.googleusercontent.com/search?q=cache:https://example.com/page.
Then, you can use Python and Requests Library. Before that, you would need to install the Requests library if you haven’t already (pip install requests). Then, write a Python script to send a GET request to Google’s cache URL for the desired webpage.
You can check the example script below:
Later, with the data, you can start parsing the Cached Page by using libraries like BeautifulSoup or lxml in Python to parse the HTML and extract the desired information.
API solution
If you’re having difficulty resolving a blocking issue, using the targeted website’s API to retrieve the data you need might be easier, provided an API is available, of course.
Or, it might be helpful to find the hidden API that the website is using to get its data. This approach can be a substitute for traditional scraping methods that are made difficult by anti-scraping measures such as CAPTCHAs or IP blocking.
By locating and utilizing the hidden API, you can potentially access the data more reliably and efficiently as APIs are often designed for data exchange and can provide structured and consistent access to the information you require. However, it’s essential to keep in mind that accessing an API in this way must be done in accordance with the website’s terms of service and legal requirements.
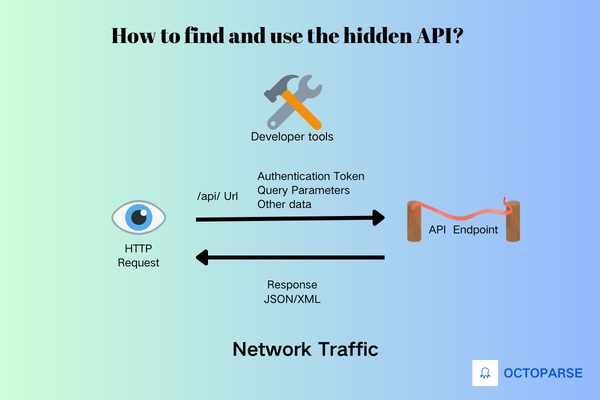
To find and use the hidden API that a website uses to fetch its data, you can follow these general steps:
- Inspect Network Traffic: First, you can use your browser’s developer tools to inspect network traffic while interacting with the website and closely look for requests made by the website to fetch data. APIs are often accessed through HTTP requests, so focusing on XHR (XMLHttpRequest) requests or fetch requests will do the help.
- Identify API Endpoints: Within the network traffic, identify URLs that point to API endpoints. These URLs may look different from regular website URLs and often start with
/api/or have a distinct pattern indicating an API request. - Analyze Request Parameters: Next, you need to look at the parameters sent with API requests. These parameters could include authentication tokens, query parameters, or other data required to access and retrieve specific data from the API.
- Understand Response Format: Then you can analyze the responses returned by the API endpoints. APIs typically return data in structured formats like JSON (JavaScript Object Notation) or XML. Understanding the structure of the responses helps you better parse and extract the desired data.
- Test and Validate: Once you have identified the API endpoints and understand how to make requests to them, you can test the API by making sample requests using tools like cURL, Postman, or scripting languages like Python with libraries such as Requests. Then validate that you can retrieve the data you need consistently.
- Handle Authentication and Rate Limiting: If the API requires authentication or imposes rate limits, you would need to handle these aspects appropriately. Obtain necessary API keys or tokens and implement logic to handle rate limiting to avoid getting blocked or throttled.
- Respect Terms of Service: Remember to adhere to the website’s terms of service and legal guidelines when accessing its data through an API, and avoiding excessive or abusive requests that may disrupt the website’s operations or violate its policies would land you safely in the data field you want.
If there is no hidden API or you don’t want to find it, you can use Google’s API.
Google’s API is a developer tool provided by Google that allows us to get search results, including cached pages. This can also reduce the risk of being blocked.
One useful API is Custom Search JSON API. It is part of Google’s Custom Search Engine (CSE) platform, which lets you create a custom search engine tailored to specific websites or topics. With this API, you can perform searches and retrieve search results in JSON format, which makes it easier to parse and extract information.
Or, if you decide to lay back and relax, you can leave the crawling work to Octoparse by setting up a crawler and an API to get the data whenever you need.
Conclusion
There will always be battles in the data field.
However fierce, there is one rule that we should always keep in mind—crawl ethically. Web crawling will remain legitimate as long as the data you crawl is publicly published and displayed, or you have the rights to see, for example, data behind log-in or paywall. Crawling private data such as user information is not only illegal but also unethical. So bear in mind what data to crawl is pivotal. Always remember to check the rulebook. Every website has a robots.txt file that tells you what’s cool to scrape and what’s off-limits. Always check it—it’s like checking the game rules before playing on someone else’s server.
While the defense side increasingly walls up and becomes more alert when it comes to intruders, more techniques are developed to power ninja infiltration. So, don’t get disheartened when some of the techniques don’t work out there. There are still many popular web crawling tools out there that can clear your headache. Contact us and tell us your needs. And Octoparse will provide a detailed data solution that matches your expectations.




