“As a newbie, I built a web crawler and successfully extracted 20k data from Amazon website.”
Do you also want to know how to make a web crawler and create a database that eventually turns into your asset at no cost? It’s not a difficult thing after you’ve learned the right tool and method. This article will share 3 different ways to help you build a web crawler step-by-step even if you don’t know anything about coding.
What Is A Web Crawler
A web crawler (also known as a web spider or web bot) is a type of automated software designed to browse the web and collect data from websites (read the definition on Wikipedia). The crawler systematically navigates websites by following links and indexing content. Web crawlers are used by search engines like Google to index webpages, but they can also be used for a variety of purposes, such as data scraping, price monitoring, market research, or gathering specific information from the internet.
You can view a web crawler as a particular program designed to crawl websites in orientation and glean data. However, you are unable to get the URL address of all web pages within a website containing many web pages in advance. Thus, what concerns us is how to fetch all the HTML web pages from a website.
Normally, we could define an entry page: One web page contains URLs of other web pages, and then we could retrieve these URLs from the current page and add all of these affiliated URLs into the crawling queue. Next, we crawl another page and repeat the same process as the first one, recursively. Essentially, we could assume the crawling scheme is a depth-search or breadth-traversal. And as long as we could access the Internet and analyze the web page, we could crawl a website. Fortunately, most programming languages offer HTTP client libraries to crawl web pages, and we can even use regular expressions for HTML analysis.
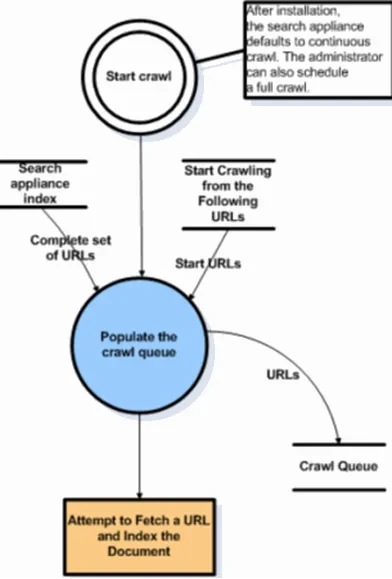
Some Tips for Web Crawling
- Crawl Depth – How many clicks from the entry page do you want the crawler to traverse? In most cases, a depth of 5 is enough for crawling from most websites.
- Distributed Crawling – The crawler will attempt to crawl the pages at the same time.
- Pause – The length of time the crawler pauses before crawling to the next page.
- Crawl Speed – The faster you set the crawler, the harder it will be on the server (At least 5-10 seconds between page clicks).
- URL template – The template will determine which pages the crawler wants data from.
- Save log – A saved log will store which URLs were visited and which were converted into data. It is used for debugging and prevents crawling a visited site repeatedly.
Here is a video that explains the web crawler and the difference between web crawlers and web scrapers.
You may be curious about is web crawler legal or not, well, it depends. But generally speaking, it’s totally legal in most countries to crawl public data on a website.
Why Do You Need A Web Crawler
Imagine a world without Google Search. How long do you think it will take to get a recipe for chicken nuggets from the Internet? There are 2.5 quintillion bytes of data being created online each day. Without search engines like Google, it will be like looking for a needle in a haystack.
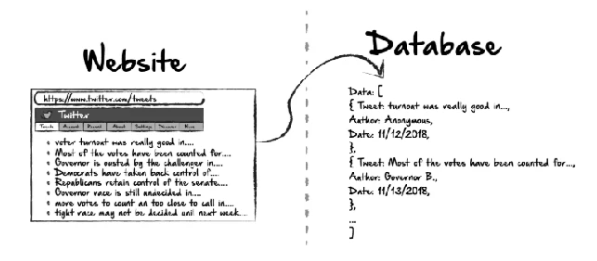
From Hackernoon by Ethan Jarrell
A search engine is a unique kind of web crawler that indexes websites and finds web pages for us. Besides search engines, you can also build a customized web crawler to help you achieve:
1. Content aggregation: It works to compile information on niche subjects from various resources into one single platform. As such, it is necessary to crawl popular websites to fuel your platform in time.
2. Sentiment analysis: It is also called opinion mining. As the name indicates, it is the process to analyze public attitudes toward one product or service. It requires a monotonic set of data to evaluate accurately. A web crawler can extract tweets, reviews, and comments for analysis.
3. Lead generation: Every business needs sales leads. That’s how they survive and prosper. Let’s say you plan to make a marketing campaign targeting a specific industry. You can scrape email, phone number, and public profiles from an exhibitor or attendee list of Trade Fairs, like attendees of the 2018 Legal Recruiting Summit.
Method 1: Preset Data Crawler Templates Online
If you only want to crawl a specific site for data quickly, you can try to use a preset data scraping template. These templates are designed for popular scraped sites and can be used from the web page, which means that you don’t need to download any software to your device. They’re very friendly for beginners as you just need to enter several parameters and start crawling data.
Try the online Contact Details Scraper template below:
https://www.octoparse.com/template/contact-details-scraper
Method 2: FREE No-coding Web Crawler Tool
For customizing more data scraping needs on the crawler, Octoparse is the recommended choice for non-coders. It has an AI-based auto-detecting function to recognize the target data fields automatically. What’s more, its advanced functions like cloud scraping, IP proxies, pagination, etc. can also be used easily during your data scraping.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
3 steps to make a web crawler without coding
Step 1: Download Octoparse and copy a web page link
Download and install Octoparse on your device, and paste the target web page URL to the main panel. It will begin detecting automatically to build a crawler workflow, or you can select “Advanced Mode” to try more customized options.
Step 2: Customize the web crawler data fields
You can simply preview the data that is detected, and click the “Create workflow” button to set the crawler. You can customize the data field as you need by clicking the target data position with the tips. Octoparse supports setting up pagination by clicking the “Next Page” button so that the crawler can navigate through it.
Step 3: Run the web crawler to extract data and export as Excel files
Once you finish setting up the extraction fields, click the “Run” button to execute the crawler. You can download the data to local devices by Excel or CSV.
If you still have questions, move to the user guide to learn more details.
Method 3: Build A Web Crawler with Coding Script
Writing scripts with computer languages is predominantly used by programmers. It can be as powerful as you create it to be. Below is a step-by-step guide to help you build a basic web crawler using Python. We’ll use Requests for sending HTTP requests and BeautifulSoup for parsing HTML content.
Steps to create a web crawler using Python
Step 1: Install and import the required libraries
Before you start coding, you’ll need to install the following libraries:
- Requests: To send HTTP requests.
- BeautifulSoup: To parse HTML content.
- lxml (optional): For faster parsing with BeautifulSoup.
You can install them using
In your Python script, import the necessary libraries:
Step 2: Send an HTTP Request
Next, you’ll need to send an HTTP request to the website you want to crawl and get the content of the page. For example, to crawl the homepage of a website, use the requests.get() method:
Step 3: Parse the HTML Content
Once you have the content of the page, you need to parse it. Use BeautifulSoup to parse the HTML and extract useful data:
Step 4: Extract Information
Now that the page is parsed, you can extract specific data, like the titles of articles, URLs, or images. For example, if you want to extract all the hyperlinks on the page, you can find all the <a> tags:
Step 5: Follow Links to Crawl Other Pages
A basic web crawler will not only scrape the current page but will also follow the links found on the page and continue crawling. To achieve this, you can loop through the links and recursively call your function to crawl them:
Step 6: Run and Test the Crawler
Once you’ve completed the code, run your Python script, and the crawler will visit the starting URL, extract data, and follow the links (if specified) to gather more data. You can adjust the crawling depth or add additional data extraction logic depending on your needs.
Final Thoughts
Writing scripts can be painful as it has high initial and maintenance costs. No single web page is identical, and we need to write a script for every single site. It is not sustainable if you need to crawl many different websites. Besides, websites tend to change layouts and structures after some time. As a result, we have to debug and adjust the crawler accordingly. A free web crawler like Octoparse or data crawler templates is more practical for beginners with less effort.




