Web scraping, also referred to as data extraction, is the process of using software to extract data from online websites. News web scraping is used to automatically gather news stories, blog posts, articles, and related stuff from online sources. This advanced technique is widely used, primarily due to its potency in retrieving a large amount of data in a short time. This article breaks down what news and articles are web scraping and its significance; explores the legal aspects and provides a simple tutorial on how to scrape news and articles effectively.
What is News and Article Web Scraping
Web scraping for news and articles begins with the collection of page URLs where the required data is located. Then, use a web scraping tool or script to retrieve the desired content and store it for future use. This process enables news agencies, journalists, researchers, and businesses to stay updated with the latest information; quickly monitor numerous news sources, track competitors, and even provide data for machine learning algorithms.
News and Article Websites Suitable for Data Scraping
Because they are updated frequently with content that is time-sensitive, news websites are among the most frequently scraped websites. Global news sources including CNN, The New York Times, and The Washington Post are among them. Also, specialized news platforms such as Bloomberg for finance news. These sites provide a wide range of data from local to international news.
Article websites provide in-depth knowledge about specific domains. For instance, editorial and opinion pieces from sites like Medium, as well as informative articles from Digital Journal. Scraping article websites proves beneficial for content curation, competitive analysis, or gaining industry-specific knowledge.
Importance of Web Scraping for Articles and News
In the fast-speed digital world, staying updated with the latest information is significant. Web scraping represents an important transformation in accessing and using online news and content with its ability to automate and simplify news and article collection.
News aggregation: Web scraping plays a critical role in consolidating online news and articles from various sources onto a single platform for convenient access. Web scraping achieves all of this automatically, saving time compared to the laborious process of manually locating, compiling, and organizing items from numerous news websites. For journalists, researchers, or anyone else who wants to stay up to date on global events, it is very helpful and time-saving.
Academic research: A lot of information from published works and web publications is frequently needed by researchers. Researchers can more accurately and efficiently retrieve data from particular articles pertaining to their study issue by employing web scraping techniques. Web scraping can also help identify patterns, trends, and connections between various research topics or sectors, which may lead to the discovery of new research avenues.
Sentiment analysis: Sentiment analysis extracts, measures, and identifies data from a variety of sources using natural language processing techniques. In this process, web scraping is a dependable way to gather the necessary data, particularly when it comes to customer reviews, social network feeds, or news items. Automating the process allows for the acquisition of more precise public sentiment data regarding the companies, products, or events. Companies can use the gathered data to manage their brand reputation, anticipate industry trends, make data-driven decisions, and better understand consumer experiences.
The Legality of Scraping Data from News and Article Sites
Since it frequently depends on a variety of criteria, the legality of scraping data from news and article websites can be a complicated matter. Web scraping is seen differently in different jurisdictions, and the rules that control it might range greatly. Web scraping is generally accepted to be lawful, although it may be illegal if it breaches terms of service, infringes upon copyrights, or allows unauthorized access to specified data.
Some news and article websites explicitly deny web scraping in their terms of service. In such cases, defying these terms can potentially lead to legal consequences. By contrast, if information is publicly available and scraping doesn’t infringe upon any terms or conditions, it’s typically considered within legal bounds. Remember, it’s always critical to respect privacy norms and obtain consent if needed while web scraping.
How to Scrape News and Article Websites Without Coding
Don’t worry if your technical expertise or knowledge of Python programming isn’t top-notch. Octoparse is here to ease your web scraping needs. Featuring a rich array of thousands of features, it can facilitate the scraping of news from almost any site quickly, even without the requirement of Python or technical skills.
Octoparse comes in both a free and premium version, offering plenty of comprehensive features. It boasts the capability of scraping multiple news sites swiftly. But how exactly to utilize it for website scraping?
Step 1: Enter url(s) from News and Article site
Simply copy and paste the desired URL(s) into the search bar in Octoparse. Click the “Start” button, a new task will be initiated and the corresponding web page will load within Octoparse’s built-in browser.
Step 2: Create a workflow and select wanted data fields
Wait until the page completes loading, then click “Auto-detect webpage data” in the Tips panel. Octoparse will scan the page and highlight extractable data for you. You can edit detected data fields and remove unnecessary fields at the bottom. Click “Create workflow” once you’ve selected all the desired data. The workflow will show up on the right-hand side.
Step 3: Run the task and export scraped data
Once you’ve reviewed all the details, you can proceed by clicking on the “Run” button. Then you have the option to either run the task on your own device or use Octoparse’s cloud servers. After the process is fully complete, you can move the collected data to local files such as Excel or a database like Google Sheets for further use.
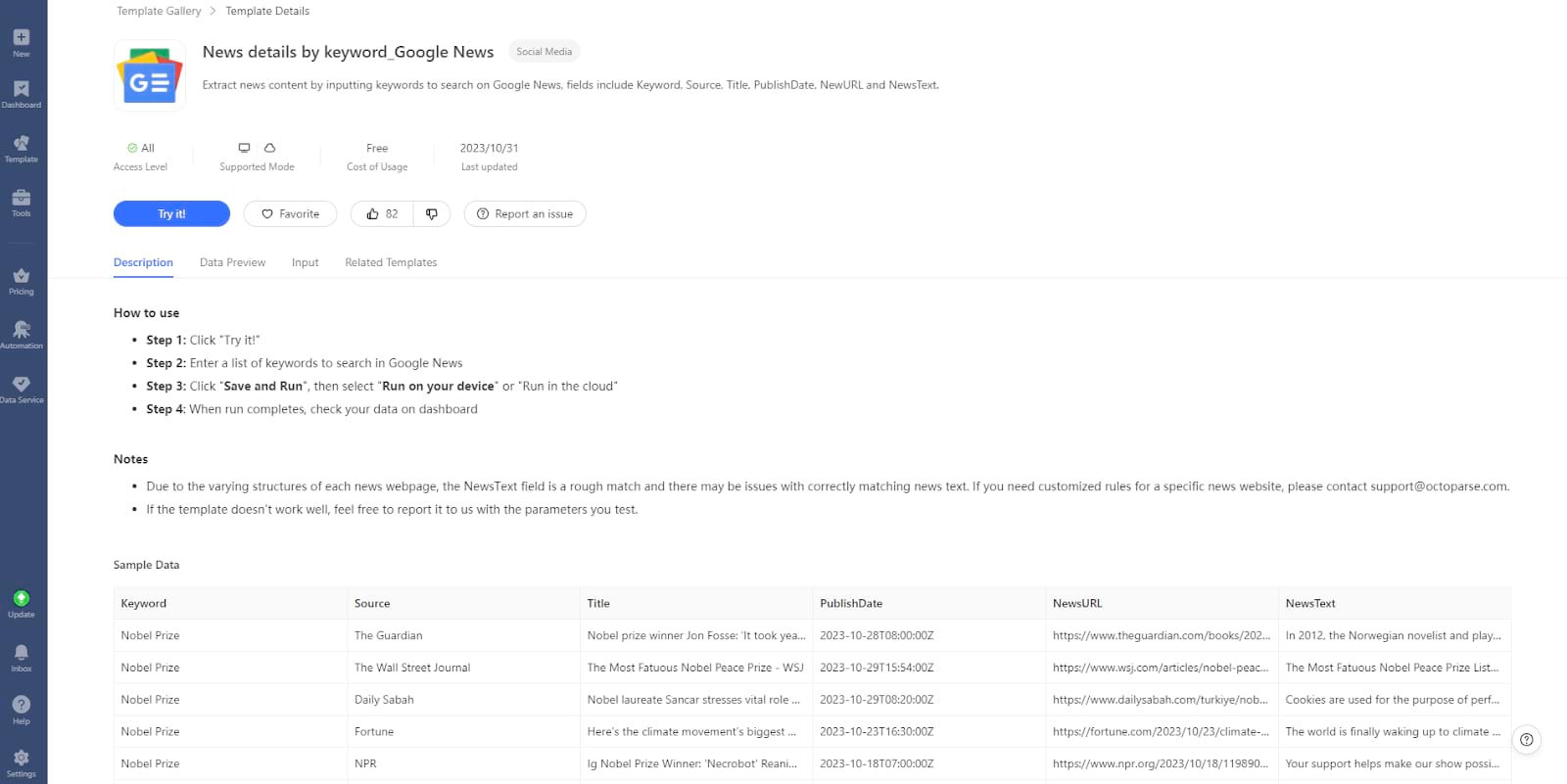
By the way, it’s always worth checking first if there’s a pre-built template that works for you, in which case you’ll only need to fill in a few parameters to scrape the data you need. If none of the templates match your needs and you don’t want to create your own scraper, email us your project details and requirements. We’re here to assist!
Wrap up
News scraping serves as an efficient method to aggregate important information on global headlines without intensive research. Octoparse stands out as an excellent tool that facilitates rapid data extraction from news websites and helps to collect useful news and article data to boost the business. So, what’s stopping you? Simply download Octoparse software and begin your journey of seamless articles and news websites scraping!




