Every minute, 500 hours of video are uploaded to YouTube. Hidden in those millions of comments and engagement metrics is pure gold—customer insights, competitor strategies, and market trends that most businesses never tap into.
I discovered this firsthand when I scraped 198 YouTube comments to predict pandemic behavior patterns.
In this article, I use two of my own examples to demonstrate the power of a YouTube Channel Crawler to extract valuable data for analysis, without the need for technical skills:
- Export YouTube comments to find out the responses to a video and add percentages to my findings
- Creating a content plan to grow my YouTube channel
How could extracting and analyzing the data from a YouTube channel benefit you?
What Does It Mean to “Crawl YouTube”?
YouTube Channel Crawler copies what’s in a channel (user comments, engagement numbers, and metadata of videos such as titles, tags, and descriptions). This data can be used for various purposes, such as competitor research, opinion mining, or SEO analysis.
When Would You Use a YouTube Crawler?
Let’s say you plan to conduct market research on 500 YouTubers to find out the best candidates for affiliate marketing.
With a tight budget, you could do the tedious thing and manually copy and paste the YouTubers’ information page by page, or you could instead do the smart thing and use a web scraping tool like Octoparse. The tool simplifies things by extracting all the information you need from the web pages spontaneously and putting it into a well-structured spreadsheet, such as a CSV file with columns for video title, view count, comment text, timestamp, and engagement rate—ready for pivot table analysis.
What would have taken you days to manually complete, can be done in seconds with a Crawler.
And the best part is that you don’t need to be a programmer to do it; with a tool, you can:
- Say goodbye to manually copying and pasting
- Gather data from multiple sources
- Scrape needed data in a well-structured format
YouTube Crawlers: My Non-Tech Story
You should know that I am not technical. Although I know nothing about programming, I still manage to take advantage of both web crawling and web scraping with a tool like Octoparse, in order to build my YouTube crawler.
You don’t need to be a coder to perform a YouTube channel crawling project. If you have the source, you can get the data!
Why I Built a Youtube Comment Scraper
Reason #1: Satisfy My Own Personal Curiosity
I am new to data mining. I wanted to know how people would spend their Thanksgiving Day in the strange year of 2020. The questions I was asking myself were, “Will people still gather? Or are they fearful of the pandemic and plan to stay home instead?”
So. Curiosity intact, I took to YouTube to find out how people would react to videos that gave warnings of Thanksgiving celebrations under Covid-19. With the help of Octoparse, I built a YouTube Comment Scraper to crawl a total of 198 comments from 4 videos and did a bit of study on the issue.
In summary, this is what I found by performing a YouTube Channel Crawl:
“As we categorized people’s reactions to the Covid-19 warnings about Thanksgiving celebratory meetings, 10.7% of people agreed on the severity of the pandemic and stated that they would take precautions, while 61.4% of the people making comments blamed overreactions or mocked the press for “building up this fraud’.”
This is a great example of YouTube Channel Crawling; I could satisfy my curiosity about what people were saying, and attribute a percentage to those taking the precautions seriously, and those who were not, and I could understand why.
Do you need to study a competitor or product? You can see from my own example that web crawling is a fantastic way to study customers or competitors.
If you are looking to build your own YouTube Channel Crawler from scratch, Octoparse is a good fit for you. You may be interested in the below video tutorial. (this video was made years before so it just showcases the use of Octoaprse 7, while you can find your way out in Octoparse 8 as well)
Reason #2: I Analyzed My Own YouTube Channel With a Web Crawler
I run my own YouTube Channel, and one day I ran across this channel comparison website and found that my peers were definitely surpassing me in both views and subscriptions. I hadn’t uploaded new videos for some time. But if I wanted to grow my YouTube Channel, I realized I would need to figure out what kind of content I should produce in order to win some of my competitor’s traffic.
My Plan of Action
First things first, I needed to come up with a plan of action. I found a great resource about doing keyword research for YouTube SEO, so I used that article to create an action plan:
Step 1: Crawl down video information of my channel
Step 2: Sort out the tags I have covered, filter with views
Step 3: Crawl down video information of my competitors
Step 4: Analyze the channel data and find the gap for my future content creation
The Data I Used For Analysis
To show you what I did, I will use the Octoparse YouTube Channel as an example.
This is the data I used in my research and analysis:
- Video titles
- Video details (tags, views, descriptions, comments, publishing dates)
This is the information I got from crawling this particular page:
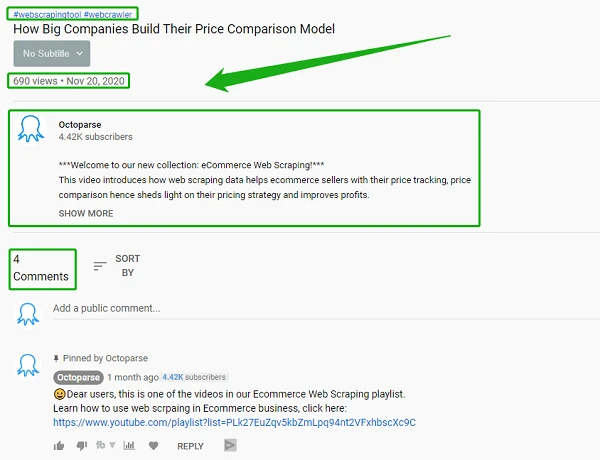
By analyzing the data that Octoparse crawled for me, I could effectively create a content plan that my viewers would value because all my content would be based on the information they provided via comments and so on.
Instead of thumb-sucking content topics, because I used the Octoparse Web Crawler, my plan was totally data-backed, which guided me through the creation process and helped me keep my momentum.
Get Your Own YouTube Channel Crawler
So you could do it the long way and spend hours collecting data by hand, or you could simply use Octoparse to do it for you within a few minutes.
We’ll be smart and use Octoparse, so you can see just how easy it is to do your own web crawling:
- Go to the system and set up a new task.
- Enter the URL of the target website.
- Create a list of items to be extracted.
- If you want, you can now rename the fields to those of your choice.
- Run the task.
- Check the extracted data.
- Export the data to Excel or another program.
Easy peasy.
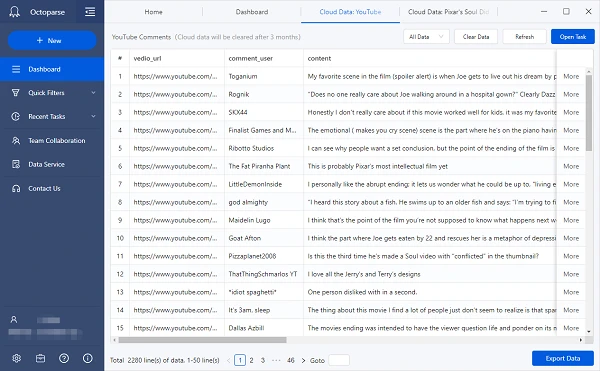
Or, you can try the Octoparse online data scraping template to extract YouTube channel data directly without downloading anything. Just click the YouTube Channel Scraper below and enter the asked parameters directly.
https://www.octoparse.com/template/youtube-channel-scraper
Conclusion
Octoparse makes web scraping easy. Businesses use data to make better decisions because data does not lie!
The kind of information you can get from Octoparse YouTube Channel Crawler will provide you with what you need to get the edge over your competitors. Using data to make decisions is just smart.
Getting the information you need to make brilliant decisions backed by data needn’t be hard; Octoparse understands non-tech users and as such, offers a plethora of resources to help non-tech folks do tech stuff.
FAQs about YouTube Channel Crawler
- How do YouTube channel crawlers extract detailed analytics data from channels?
YouTube channel crawlers scan YouTube’s HTML to identify and extract data patterns — video titles, views, likes, comments, and metadata, etc. They collect target data points per video automatically, then export to CSV or Excel for engagement rate analysis, identifying creators, content strategies, and so on. What takes days manually happens in minutes with tools like Octoparse, which can process entire channels without coding knowledge.
- What are the key differences between free and premium YouTube crawler tools?
Free tools: Data extraction quantity limit, basic data only, break frequently, banned easily, and no advanced function (proxy rotation, cloud operation, bypass CAPTCHA, etc.)
Premium tools: Unlimited videos, cloud-based 24/7 crawling, auto-scheduling, sentiment analysis, and 99% uptime even during YouTube updates. Premium tools can extract data from hundreds of videos in under an hour—work that would take days manually.
- How can I use YouTube crawlers to find influencers within a specific niche or location?
Crawl successful niche channels to extract their “Related Channels” networks. Analyze comment sections for active micro-influencers. For locations, use keywords like “[City] vlogger” and filter by location mentions in descriptions. Pro tip: Nano-influencers (1-10K followers) achieve 7-8% engagement rates vs 1.7% for mega influencers, often delivering 20% higher conversion rates at much lower costs.
- Why are API-based crawlers more scalable for large-scale YouTube data extraction?
API-based YouTube scraping tools excel at scale through direct access to structured data endpoints, eliminating the need to parse HTML pages. They offer programmatic control with defined rate limits, reducing blocking risks while operating within YouTube’s official framework. The machine-readable JSON responses integrate seamlessly with data pipelines, and standardized error handling ensures reliability.
- What are the main challenges when scraping YouTube channel data at scale?
Top challenges: Anti-bot measures (CAPTCHAs, IP blocks), dynamic content loading, data inconsistency across regions, volume management (100K videos = 10GB data), and frequent YouTube updates. Octoparse solves these with rotating proxies, headless browsers, auto-login, automatically bypassing CAPTCHA and auto-detection—maintaining 98% uptime while others break.