Pagination is a widely used technique in web design that splits content into various pages, thus presenting large datasets in a much more easily digestible manner for web surfers.
There are a lot of pagination methods employed by different web developers, such as numbered pagination, infinite scrolling, pagination with a “Load More” button, etc.
Although pagination is generally believed to improve user experience, the bad news is that it makes web scraping more difficult.
If you’re trying to scrape data from a website and are facing a dilemma about how to tackle pagination for web scraping, we have you covered.
Octoparse, an automatic web scraping tool, supports dealing with websites of various pagination structures. Now we are going to illustrate the various approaches for how to deal with different kinds of pagination with Octoparse.
How to Deal with Different Types of Website Pagination
1. Pagination with the next button
What is Pagination with the Next Button

Clicking on the next button to paginate is perhaps one of the most commonly used methods for pagination, making it easy for visitors to traverse through pages on the website. It is very simple to handle this kind of pagination for web scraping in Octoparse.
How to Deal with Website Pagination with the Next Button with Octoparse
No matter if it is the next button shown in the form of the word – “Next” or just a right arrow – “>”, you only need to build a pagination loop to keep clicking on the button after scraping is done with the current page. You can also use Octoparse auto-detect if you want quick results.
📖 Check Our Step-by-Step Tutorial on Dealing with Pagination with the “Next” Button.
2. Numbered Pagination without the “Next” Button
What is Numbered Pagination without the “Next” Button

As you can see in the picture above, the approach for this particular kind of pagination is very similar to that with the next button. If you want to build a pagination loop, keep clicking the next page number down the line. However, since this one you won’t be clicking on a static element, locating the next page number precisely is critical.
How to Deal with Numbered Pagination without the “Next” Button with Octoparse
Octoparse uses XPath (XML Path Language, which uses “path like” syntax to identify and navigate nodes in an XML document) for locating any elements. So the key point here is to modify the XPath of the pagination loop to make sure it will always locate the next page number as soon as the current page’s been fully scraped.
📖 Check Our Step-by-Step Tutorial on Dealing with Numbered Pagination without the “Next” Button.
3. Infinite Scrolling
What is Infinite Scrolling
Infinite-scrolling, also known as “endless scrolling” is a technique used most often by websites with JavaScript or AJAX to load additional content dynamically as users scroll down to the bottom of the webpage.
Instead of using “previous/next” pagination buttons, many websites are turning to infinite scrolling, saving people from having to click through the many pages.
Infinitive scrolling is typically used by websites with a large amount of data to display such as social media platforms like Facebook and Twitter.
How to Deal with Infinite Scrolling with Octoparse
Octoparse deals with infinitive scrolling by mimicking the scrolling behavior. Depending on the amount of content you want to load, simply set up the appropriate scroll time and scroll method, you will have the page scrolled automatically.
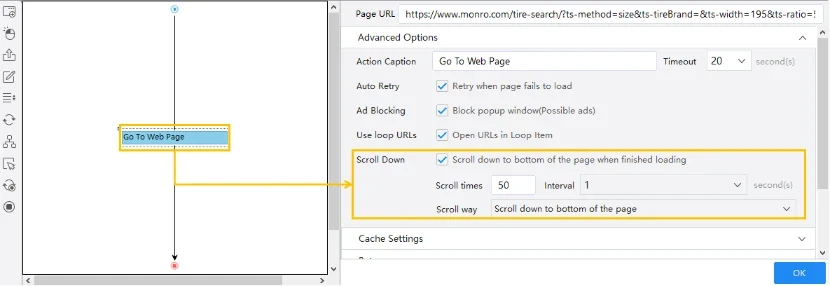
📖 Check Our Step-by-Step Tutorial on Dealing with Infinite Scrolling.
4. The “Load More” Button
What is the “Load More” Button
Load more button kind of navigation is another popular alternative to infinite scrolling. In this case, you would have a specific button, like “Load More”, to trigger the content loading with AJAX as you reach the bottom of the page.
How to deal with the “Load More” Button with Octoparse
Octoparse deals with the “Load More” button with a pagination loop, which is the same as how we deal with the “Next” button, by clicking on one single button repeatedly.
The difference though is that with the “Load More” button, we need to have the pagination loop run until the load button disappears before proceeding to the next step.
Once all the desired content gets loaded, the scraping process is as easy as scraping a single page.
📖 Check Our Step-by-Step Tutorial on Dealing with Pagination with a “Load More” Button.
How to Create a Data Collection Task with Pagination in Octoparse
Now that you have learned four types of website pagination and the ways to handle them with Octoparse. Let’s put them into practice.
Here I’ll show you two ways to scrape page with pagination by clicking on the “next” button, taking Amazon search page for “sunglass” as an example.
1. Use Octoparse’s Auto-Detect (Recommended)
- Paste your target URL into Octoparse (e.g. Amazon search page for “sunglass”).
- In the Tips panel, choose “Auto-detect web page data”.

- Click “Check” to let Octoparse identify elements—including the Next button. The chosen button will be highlighted.
- If the wrong element is detected:
- Click “Edit” Shown in the Tips panel
- Manually pick the correct “Next” pagination button in the target page.
- If you want to scrape more pages, you can click “paginate to scrape more pages”
- Uncheck “Add a page scroll” if it’s not needed.

- Click “Create workflow” in the Tips panel.
- In the workflow, select “Pagination” → “Click to paginate” to test the behavior. If Octoparse moves to the next page correctly, your pagination is set.
2. Manually Set up Pagination
- Click the actual Next button on the webpage manually.
- In the Tips panel, choose “Loop click next page”, or if absent, use “Loop click”.

- Test pagination the same way as in Method 1:
- If it fails:
- Ensure the correct button is selected.
- Add a delay in Advanced Options if the site takes time to load.
- If the page is dynamic, use “Scroll to load data” before the click action.
Conclusion
Pagination reduces page complexity and improves the readability of web content, yet it needs to be tackled using various approaches, whichever that creates maximum efficiency. If we fail to deal with pagination properly, it will result in missing data and a waste of time. By making good use of a web scraping tool like Octoparse, you can avoid the complexities of web scraping!




