While the information explosion provides us with an opportunity to select from a wide range of resources, it has also given rise to concern over how to cut through the noise and focus on the specific topics and trends that matter to us. To that end, you might have chosen to follow your favorite blogs and news sites in an RSS reader. But when you come upon a site without a full-text RSS option, what do you do?
In this article, we will introduce to you some easy-to-use article scrapers to download blogs and news (e.g. a Medium Scraper). We will guide you through the setup of a custom article scraper that can quickly, efficiently, and reproducibly collect all the articles you need, whatever their length may be.
3 Recommend Article Scrapers
Narrowing down the best article scrapers in the market is no easy task when there are so many different options to choose from. The important thing to remember is that there is no single best choice—only the best software to suit your data needs, which depends on your budget, UI preference, scraping frequencies, and experience level.
The good news is that whether you’re a beginner looking to set up your first scraping task, or a seasoned data miner looking to upgrade your scraping experience, there’s most certainly a tool out there for you.
We’ve tested over ten web scraping tools, and below you’ll find our recommendations for the best three in the market for article scraping. These picks were selected not only based on their article scraping feature set but also their overall performance.
1. Octoparse
Octoparse is the best article scraping tool that allows you to extract data from multiple websites with no code involvement. It can mimic human browsing behavior and scrape articles and posts from any website within minutes.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
- Point-and-click Interface: Octoparse comes with a user-friendly UI. It allows you to interact with your favorite new sites in its built-in browser with point-and-click actions. Therefore, it’s easier to master than most scraping tools.
- Advanced Features: Octoparse has lots of powerful features to help you overcome hurdles to article scraping. For example, if you want to scrape articles from Medium, Octoparse can easily deal with challenges like login issues, keyword searches, infinite scrolling, and many more.
- Cross-Platform: As a client-based freeware, Octoparse supports both Windows and Mac, you can simply download and install Octoparse from its official website and try out some of the ready-to-use templates for article scraping. Visit its help center for tutorials if you decide to build a custom web crawler on your own.
- Acceleration & Scheduling: Octoparse comes with a boost mode which greatly improves the speed of article scraping both on local devices and in the cloud. If you want up-to-date articles or publications fast and easy, Octoparse won’t let you down. The crawlers in Octoparse can also be scheduled to run hourly, daily, or weekly to get articles delivered regularly either on your local machine or using its cloud-based platform.
- Customer Service: The Octoparse team also delivers great customer support and is dedicated to helping you with all kinds of data needs. If SaaS is not your thing, they also have a managed service that offers a one-stop solution for all your data needs.
Octoparse also provides online article scraper, which allows you to extract article data without downloading anything and no-coding. Click on the link below to have a try.
https://www.octoparse.com/template/smart-article-scraper
2. WebHarvy
WebHarvy is another client-based article scraping software that requires Windows operating system to run. It can be used to scrape article directories and press releases from PR websites.
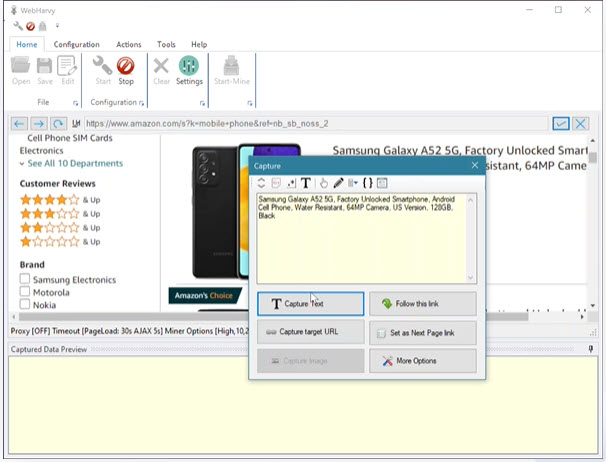
- Simple Explainer Series You can check the explainer videos on WebHarvy’s official website on how to create a task to scrape the title, author name, published date, keywords, and body text of an article. If you are new to web scraping, they might be a good starting point.
- Evaluation Verison It’s highly recommended that you download and try their evaluation version and check the basic demonstration videos to start your data journey. It is very easy to use and also supports proxies and scheduled scraping. If it can satisfy your data needs, you can purchase a single-user license of WebHarvy for just $139. You get free support and free updates for a period of 1 year.
3. ScrapeBox – Article Scraper Addon
As one of the most powerful and popular SEO tools, ScrapeBox has an Article Scraper addon that allows you to harvest thousands of articles from a number of popular article directories.
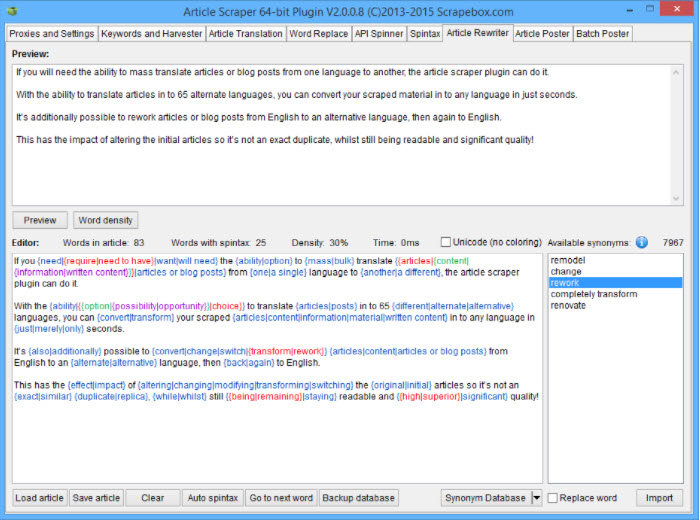
- Lightweight Add-on As a lightweight aadd-on the article scraper add-on of ScrapeBox features (1) proxy support, (2) multi-threading for fast article retrieval, (3) the ability to set how many articles to scrape before stopping, and (4) articles can be saved in ANSI, UTF-8, or Unicode format so articles in any language can be harvested.
- Keyword-based Filter Also there’s the option to automatically remove links and email addresses from articles, and the ability to save articles into keyword-based subfolders so that when harvesting articles for numerous keywords simultaneously, all your articles are categorized.
- Advanced Plugin ScrapeBox also offers an advanced Article Scraper Plugin that can post articles, spin articles, translate articles, and much more.
There are also many other web scraping tools for article data scraping, you can read about the top 10 article scrapers to find more.
Example: Scrape Articles from a Medium Publication
To better explain how an article scraper works, we will scrape data from articles from the Towards Data Science Medium publication using Octoparse. Make sure to download the latest version of Octoparse before getting started.
Use the link below to follow through:
https://medium.com/towards-data-science
Step 1: Open target Medium webpage in Octoparse
Every workflow in Octoparse starts by entering a web page to start with. Simply enter the sample URL into the search bar on the home screen and wait for the webpage to render.
Step 2: Customize article scraping with page scroll
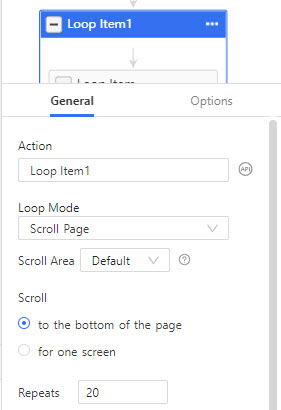
Medium is designed to load content dynamically with its infinite scroll pattern. So we need to add a loop item in the workflow section. In the general tab for the loop item, set loop mode to scroll the page, and repeat scrolling to the bottom of the page 20 times.
Step 3: Scrape data from the article list page
Before collecting the content of each article, we need to collect some metadata from the list page. Click on the first article block in the list and choose Select sub-elements > Select All > Extract data to collect the data from the article list. Rename the data fields and delete unwanted ones, which leaves us with the author, title, description, tag, and length of the articles.
In addition, we can capture the article URLs using the XPath locator.
- Click add a custom field in the Data Preview section and select Capture data on the webpage
- Tick Relative XPath and input //a[@aria-label=”Post Preview Title”]
- Save and Run the parent task to get the first batch of data (it takes a few minutes)
Step 4: Use the URL list for a second task to scrape full text
Next, we need to create a child task with the URLs from the last data run.
- Go back to the Octoparse home screen, click + New, and select Advanced Mode
- For the Input URLs, select import from the task and locate the URL data field of the first task
- Add an Extract data action in the URLs loop
- Click add a custom field in the Data Preview section and select Capture data on the webpage.
- Tick Absolute XPath and input //article to locate the whole article
Step 5: Run the task to get the second batch of data
Finally, save the workflow you created after checking all preview data. Click on the Run button to start scraping article data from Medium quickly. The scraped data can be saved as Excel, CSV, or Google Sheets files, and save to your database directly.
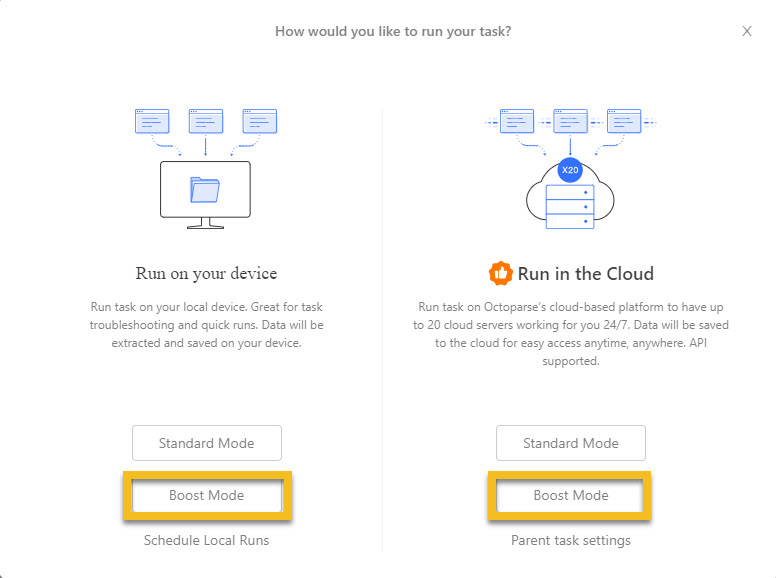
You might have noticed that we have divided the task into two subtasks. It is intended to increase the scraping speed of the whole project. If you are dealing with a complicated project, it is recommended that you split it into subtasks and run them in Octoparse’s cloud-based platform for higher speed. You can also schedule your tasks to run hourly, daily, or weekly and get data delivered to you regularly.
Final Thoughts
Now, you have learned the example of scraping article data from Medium with the best article scraper – Octoparse. You can get article data from other content sites with the similar steps above. Or, you can find easy online data scraping templates from Octoparse official sites that ask for non-coding skills.




