Web scraping is an invaluable tool for gathering large amounts of data from websites, and Octoparse is one of the leading platforms that simplifies this process. Whether you are gathering product data for an eCommerce website, extracting contact details from a directory, or analyzing competitors, Octoparse can help you organize and automate your web scraping process.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
In this article, we will dive into what a task in Octoparse is and how it works. By the end, you’ll understand how to set up a task and how it can simplify your data extraction process.
What Is a Task in Octoparse
A task in Octoparse refers to a specific scraping operation that you configure in the Octoparse tool. It represents the entire workflow that defines the data extraction process, including the target website, data points to be scraped, actions to perform, and how you want to export the collected data.
A task in Octoparse acts as the main blueprint for scraping: it contains instructions for how to navigate a website, locate specific elements (such as text, links, or images), and store or export the data you want to collect.
Tasks are the backbone of any scraping project in Octoparse, and understanding how to create and manage tasks is key to successfully automating your data collection.
2 Ways to Set a Task in Octoparse
Here are 2 ways to build a web scraping task in Octoparse, you can learn the features of them and choose the one more suitable for you. A detailed tutorial about the Octoparse Task can also be found in Octoparse’s Help Center.
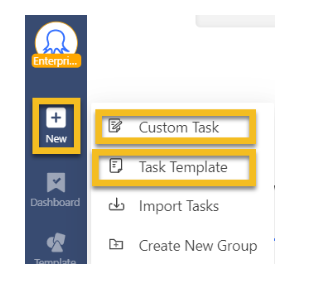
Custom Task: Build a crawler by yourself (no-coding)
With Custom Task, you’ll get to customize your own scraping task in any way you like, such as searching with keywords, logging into your account, clicking through a dropdown, and much more. Simply put, Custom Task is all you need to scrape data from any website.
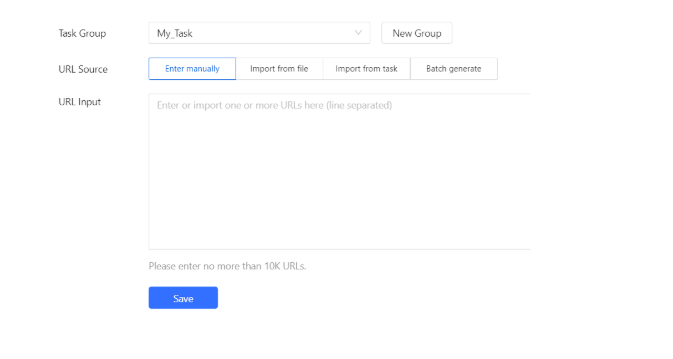
Step-by-step to create a task in Octoparse
Step 1: Start a New Task
Open Octoparse and click on “New Task”. Enter the URL of the website you want to scrape.
Step 2: Define the Data
Use the point-and-click interface to select the data fields you want to scrape. This might include product names, descriptions, pricing, and more. Once selected, Octoparse will automatically identify similar elements across the page.
Step 3: Set Up Pagination and Actions
If the data spans multiple pages (such as product listings), set up pagination rules to scrape data across all pages.
Step 4: Configure Export Settings
Choose how you want the data to be exported. You can select between CSV, Excel, JSON, or save the data directly to the cloud.
Step 5: Run Your Task
Finally, click Run to start your task. You can choose to run the task locally or in the cloud, depending on your preference. Cloud-based tasks run faster and don’t require your computer to stay on.
Tips for Task Management
You can modify the task name by clicking the textbox above the workflow panel, or click the edit button to rename a saved task.

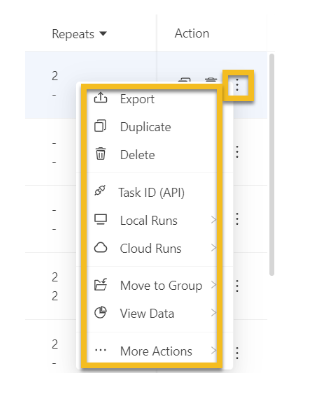
Here are more actions for your task:
- Duplicate – Replicate task
- Delete – Delete a task
- Export – Export the task file. The task file can be saved on your device or submitted to the support team for troubleshooting.
- Task ID (API) – ID for the task. Can be utilized in API requests.
- Local Run – Options for Local Run: Start/ Stop, or Schedule
- Cloud Run – Options for Cloud Run: Start/ Stop, Schedule, or Cloud Run History
- Move to Group – Relocate the task to a different group.
- View Data – View the Cloud or Local data
- More Actions – Edit, Rename, or Task Settings
Task Template: Preset data for popular websites
Task Template provides a large number of pre-set scraping templates for some of the most popular websites. These tasks are pre-built so you’ll only need to input certain variables, such as the search term and the target page URL, to fetch a pre-defined set of data from the particular website.
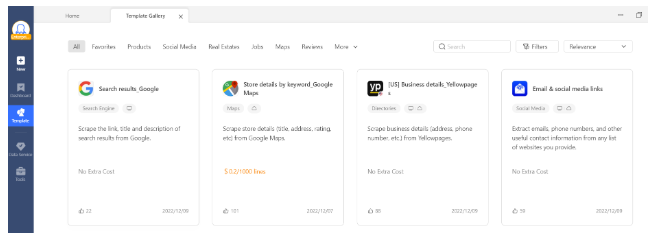
These templates are very easy to use. Just search the keyword, preview the data sample the template provides, and enter the parameters it asked if you’re satisfied with the data. Your data can be scraped and exported quickly.
Online templates to scrape data without download
Now, Octoparse also provides online data scraping templates so that you don’t need to download and install any application on your device. Just visit the Octoparse Templates and choose the template you need. Or, you can try the Contact Details Scraper online from the link below.
https://www.octoparse.com/template/contact-details-scraper
Final Thoughts
In summary, a task in Octoparse is the backbone of your web scraping operations. By automating the entire process—from data extraction to export—you can save valuable time and improve the efficiency of your data collection projects. Whether you are scraping product prices, reviews, or market research data, tasks in Octoparse provide a flexible and easy-to-use solution to achieve your goals.
With Octoparse, you don’t just automate the mundane — you unlock the power of data. Start creating your tasks today and let Octoparse handle the heavy lifting!