Zyte is a visual web scraping tool. In this article I will put it head to head with Octoparse to see how these two tools compare (check here for another comparison between Octoparse and import.io).
Feature Comparison
| Feature | Octoparse | Zyte |
| Authoring environment | Desktop app for Windows (available for MAC with virtual machine) | Web based application |
|
Selecting elements |
Point-and-click, XPath |
Point-and-click, CSS selectors, XPath |
| Pagination | Click on pagination links or manually enter the Path (websites without “Next page” links) | Exclusively by exploration |
| Scraper logic | Variables, loops, conditionals, function calls (via RegEx, XPath) | Selecting and extracting only |
| Pop-ups, infinite scrolls, hover content, drop downs, tabs | Yes | With external libraries |
| Sign in to accounts | Yes | Yes |
| Entering into search boxes | Yes | No |
| Javascript, Ajax and dynamic content | Yes | Yes, when subscribed to Splash |
| Debugging | No | Visual debugger and server snapshots |
| Transforming data | Regex expressions | Partial annotations |
| Speed | Fast parallel execution | Fast parallel execution |
| Hosting | Hosted on cloud on Octoparse servers if subscribed to Octoparse plans or on local machine with free version | Hosted on cloud of ScrapingHub servers |
| IP Rotation | Included in the paid plans or manual IP proxy in the free plan | With Crawlera plan |
| Scheduling runs | With a premium Octoparse account | With a Scrapy Cloud plan |
| Cloud service | Yes | With a Scrapy Cloud plan |
| Data export | CSV, Excel, Txt, Databases, API | CSV, JSON, XML, API |
| Support | Professional support, tutorials, community support |
Community support |
Octoparse vs. Zyte
What can Octoparse do for you?
With its simple point-and-click UI, extracting data with Octoparse can be rather easy. Octoparse, a visual web scraper, works by mimicking human browsing behaviors and can be instructed to interact with the website in various ways, thus allowing scraping dynamic and more complex websites.
Some of the more advanced features worth mentioning include scraping behind a login, select the different options from a dropdown menu, searched based extraction as well as dealing with infinite scrolling, etc. Octoparse is also pretty neat by having a workflow showing all the different steps for any extraction task and I did find it useful for sorting out all the logic behind the extraction.
Furthermore, the built-in RegEx tool and XPath tool come in handy if one is looking to customize the data extracted.
Octoparse supports multi-step extractions and eventually combines the data together in one output. An extraction task can be set up quickly with only a few steps: open web page – select items – extract data – get data – export data.
For more detailed information you can check out Octoparse Tutorials.
What can Zyte do for you?
Making a crawler in Zyte is very similar to that in Octoparse. Like Octoparse, Zyte can automatically detect similar items on any page. Zyte will find items that are structured the same as the sample you have created and this step will continue until you either tell it to stop, reach the limit of your ScrapingHub plan or if the software finishes checking every page.
The way Zyte gets data can lead to unexpected or unwanted data. To make up for this issue, Zyte provides regular expressions to narrow down its search. Still, big sites like Amazon are hard to navigate this way. Check below for a simple example of how the Zyte crawler works.
What is the difference between Octoparse and Zyte?
As previously mentioned, Zyte can only get data from pages that have the exact same layout, but going between search results and more detailed product description pages is not possible. Zyte can’t interact with dropdown menus, pop-up windows, infinite scrolling pages, or pagination unless you use external libraries. It can’t deal with captcha, which is quite common for most web pages. And you would not know which pages Zyte gets its data from as the scraper can’t be controlled with any regular expressions. As for transforming the data into regular expressions or modifying the XPath, there are no tools available for you will need to master XPath and regular expression if you want to explore more on Zyte.
According to my test, there’s no difference in the extraction speed of a Zyte scraper running on Scrapinghub cloud and an Octoparse crawler running on my local machine. However, with the Octoparse cloud service which enables extraction in the cloud, running an extraction can be faster than that on Zyte.
Cost Comparison
There’s no doubt that Octoparse has overwhelming advantages. Both Zyte and Octoparse provide free versions, but their pricing structures are quite different.
Zyte’s Pricing
Zyte’s pricing depends on the number of ScrapingHub cloud units you purchase, and the use of extra libraries in ScrapingHub. Buying additional ScrapingHub cloud units will make your crawl faster. Also, if you buy one cloud unit, you can save your data for 120 days on the cloud.
ScrapingHub cloud unit price is $9 each. Check below for details.
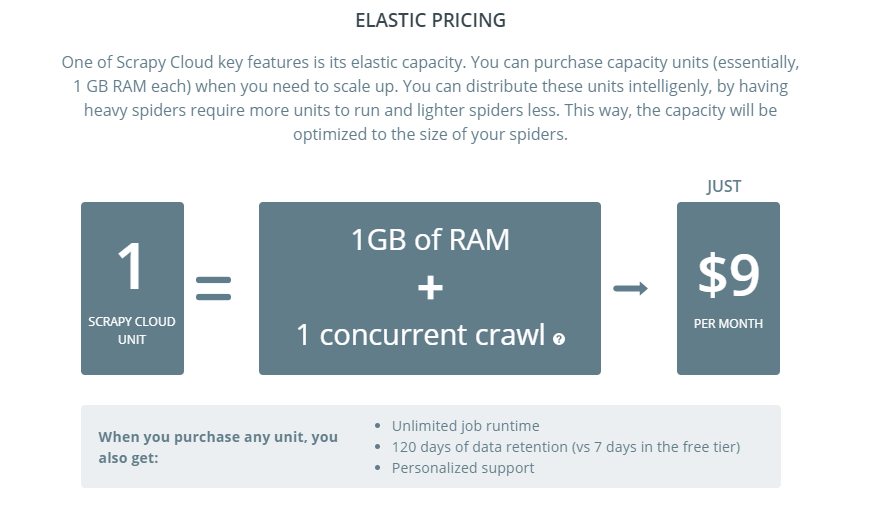
ScrapingHub Cloud
If you want to make full use of Zyte, you need to subscribe to ScrapingHub’s other paid services, IP rotation service Crawlera and JavaScript friendly browser Splash. Crawlera’s paid plans ranging from $25/month to $500/month are limited by the number of monthly requests and concurrent requests, while Splash’s plans ranging from $25/month to $100/month are based on the different speed.
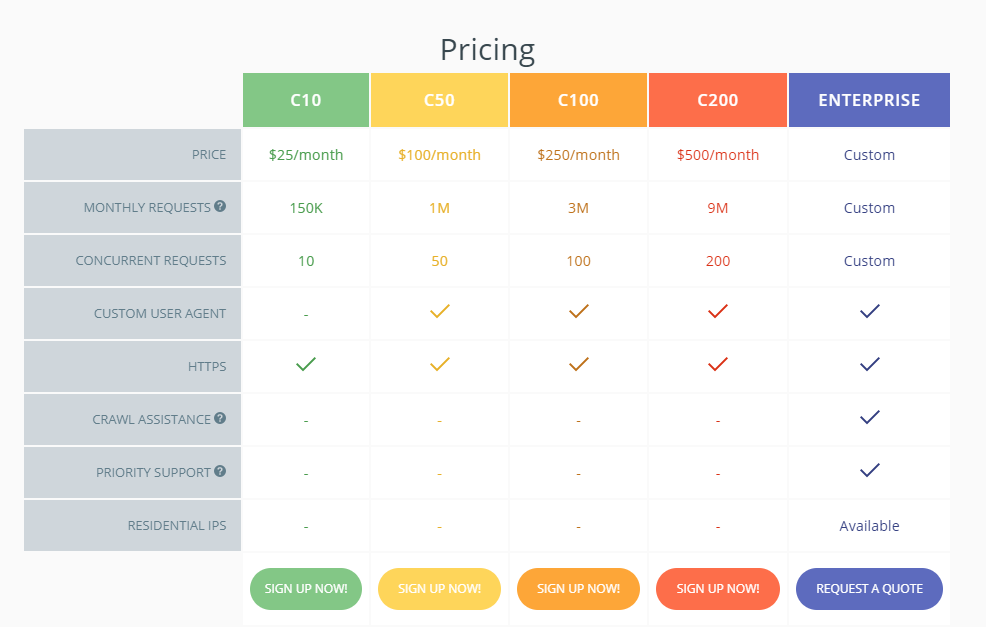
Crawlera Monthly Plans
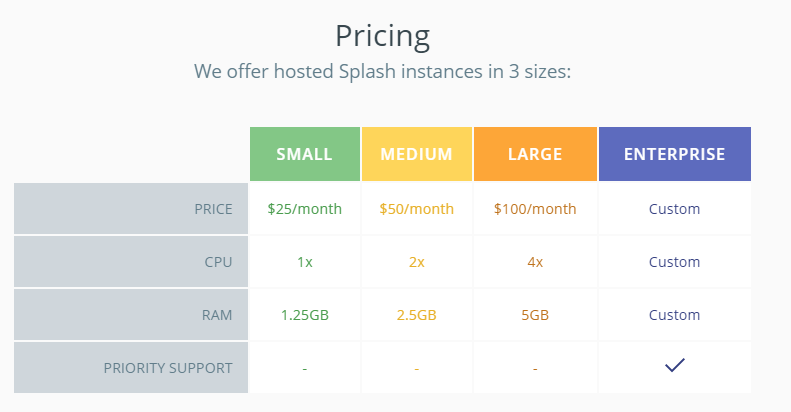
Splash Monthly Plans
Octoparse’s Pricing
Unlike Zyte, which is similar to infrastructure-as-a-service(IAAS), Octoparse offers more conventional software-as-a-service (SAAS) packages with free, basic, standard and professional plans. Price ranges from $19/month to $249/month with three different kinds of subscriptions including monthly, quarterly and annual. Please see a summary of Octoparse’s pricing plans below.
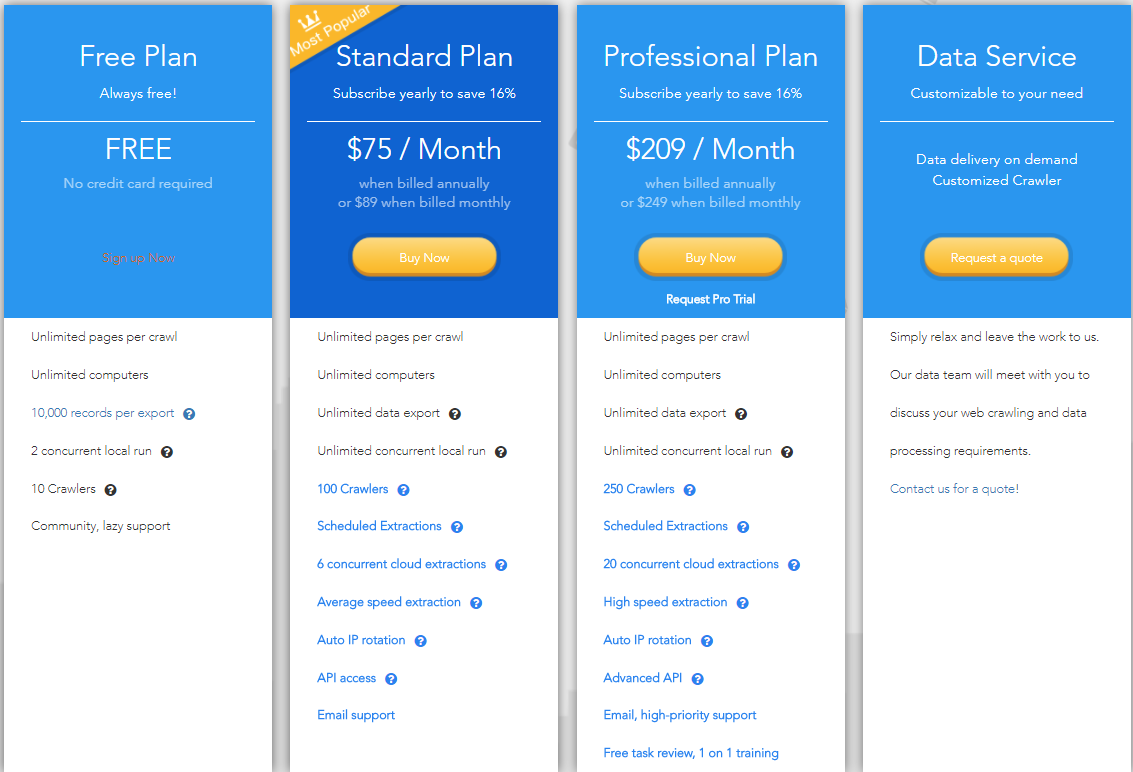
Octoparse Pricing
Both Octoparse and Zyte provide custom solutions if you need a more customized web scraping plan. They both also provide data service for data on demand.
Conclusion
While Zyte needs to work with other platforms of Scrapinghub at a higher level, Octoparse has most of the features bundled together for easier implementation. For entry-level users, Octoparse offers the same level of web scraping power and scale as Zyte in a much easier-to-use package. It’s not difficult to start an Octoparse crawler or Zyte scraper, but it would take you quite a while if you want to explore more.
I wanted this comparison to be as fair as possible. However, since Zyte is an open-source project while Octoparse is a UI tool, I can’t help if my bias for Octoparse may have lead to some unfair criticism of Zyte. If you find something wrong with the information above or if you are an experienced Zyte user, please contact me here. Thank you.




