The Guardian, people all across the world can obtain a great deal of information from the British daily newspaper. Since its establishment in 1821, it has gained a reputation for having the highest standards of journalistic ethics and providing in-depth reporting on a variety of topics, including politics, international affairs, culture, and sports. The Guardian adopted the digital age and used its extensive web platform to increase its global reach. It is renowned for its narrative style that is truthful and its dedication to social justice, which makes it the best source for readers looking for accurate information, well-rounded viewpoints, and perceptive insights.
Why Scrape Data from The Guardian
The Guardian is a reputable news organization that is extensively used for a number of important reasons and is renowned for its accurate and impartial reporting. Let’s examine each of them in more detail one by one.
Content Aggregation
Scraping The Guardian is valuable for the purpose of content aggregation. The newspaper offers an extensive range of high-quality articles, rich in depth and perspective. By aggregating this content, users can create a centralized repository of information on a variety of subjects. Aggregation also allows for easy comparison and contrast of The Guardian’s reporting with other sources, enabling a broad view of world events and a deeper understanding of specified topics.
Marketing Research
For research purposes, data scraping The Guardian can provide a wealth of reliable information. Researchers can compile articles relevant to their study, offering a well-informed viewpoint and creating a sturdy foundation for thorough investigation. The Guardian’s commitment to balance and objectivity, as well as its consistent focus on significant issues, makes it an excellent primary or secondary source for scholarly research and professional studies.
Sentiment Analysis
Sentiment analysis is the process of determining the emotional tone behind a series of words and understanding the attitudes, opinions, and emotions of the people writing them. The Guardian’s vast array of articles offer a goldmine of data for this purpose. With its wide scope of coverage on diverse topics and its global audience base, sentiment analysis on the newspaper’s content can provide valuable insights into public sentiment on a range of issues and trends.
Important Considerations Before Scraping the Guardian
Given the various benefits of web scraping, it’s critical to understand some important considerations before embarking on the process. Pivotal among these is respect for privacy and adherence to legal norms. Web scraping should align with the data privacy norms of the jurisdiction it’s being conducted in. It should not infringe upon personal data unless explicitly permitted. Furthermore, the website’s terms of service must be respected. Some websites prohibit scraping in their terms of use and violating them could lead to legal repercussions. Lastly, it is important to respect the site’s robots.txt file. The file is used by websites to guide how search engines and crawlers should interact with the site. Ignoring these guidelines can lead to your IP being blocked or other negative impacts, interfering with the web scraping process.
Tip: Welcome to check out more sources about the legality of web scraping as needed.
Methods for Web Scraping The Guardian
Coding Method: Python
Web scraping of The Guardian necessitates specific tools designed to extract data from websites swiftly and accurately. Python libraries, like Beautiful Soup and Scrapy, are two such pivotal tools. Beautiful Soup allows for parsing HTML or XML documents into a readable tree structure, enabling users to navigate, search, and modify the parse tree, while Scrapy aids in creating robust and scalable crawling programs. Additionally, Selenium is another beneficial tool as it can deal with Javascript on the Website, which static scrapers might overlook. Feel free to check out the source for a more detailed guide on how to do web scraping using Python.
Non coding Method: Octoparse
For those who prefer a less code-intensive approach, software applications like Octoparse might be more appropriate. Its user-friendly interfaces allow for extracting data from the Guardian through simple point-and-click commands efficiently. Moreover, employing proxies or VPNs for Mac could prevent IP bans during extensive scraping scenarios, especially for scraping the Guardian. Choosing the right toolset for web scraping would largely depend on the user’s technical proficiency and the scope of their scraping requirements.
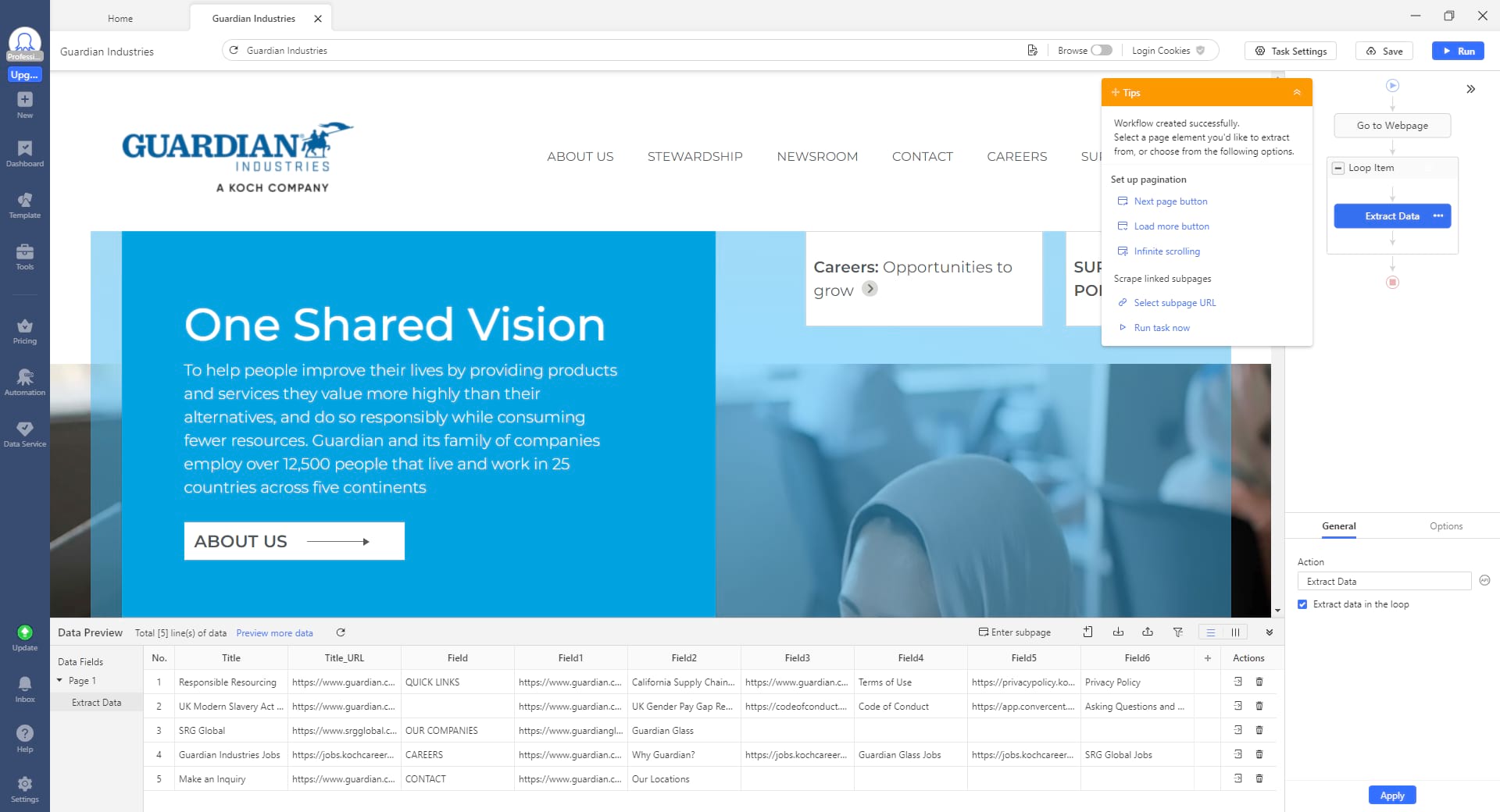
Step-by-Step guide on Setting up the Guardian Scraper
Step 1: Create a new task for scraping the Guardian data
Get ready for the url from the Guardian that you want to scrape data from, copy and paste it into the search bar on Octoparse. Then click “Start” to create a new scraping task.
Step 2: Auto-detect the Guardian data
After the Guardian web page finishes loading in the built-in browser, you can use the auto detect feature to scrape all the Guardian data you want. Click “Auto-detect webpage data” in the Tips panel, then Octoparse will scan the page and predict the data you would like to extract. It will highlight all detected data inside the browser.
When you make sure you’ve selected all the needed data, click “Create the workflow”. Next, a workflow will be auto-generated on the right-hand side that shows the process of data scraping. Click on each step on the chart to check if it works properly, and add or remove any unwanted steps. Meanwhile, you can edit the data fields, like renaming them or deleting unwanted data, directly in the data preview section.
Step 3: Run and export the Guardian data
Once you’ve double-checked all the collected data, click on the Run button. Choose to run your scraping task on your local devices or in the Cloud. When the scraping process is completed, export the Guardian data to Excel or Google Sheets for further use.
Octoparse also provides template presets for news and article scraping. It’s even an easier way to scrape news data. Since the workflow is preset, you can only type in the necessary parameters to launch the scraper directly. You can find the templates and preview the data samples.
wrap up
The Guardian stands as a veritable goldmine of information, recognized for its high-quality journalism and comprehensive breadth of topics. It provides invaluable material for various applications, from content aggregation, conducting wide-ranging research, to sentiment analysis. Web scraping serves as a potent tool to harness this wealth of data effectively.
However, one must bear in mind crucial considerations regarding respect for privacy and the site’s specific terms of service. To effectively scrape The Guardian’s extensive resources, several tools, both code-based like Python libraries and user-friendly interfaces such as Octoparse can be utilized. Understanding and selecting suitable scraping tools caters to individual technical competencies and specific project needs, hence ensuring an efficient and effective scraping experience.




