If you’ve dealt with text-based data before, you may be no stranger to how a messy dataset can make your life miserable. The fact that most of the world’s data come in nonstructural form is an ugly truth to be known sooner or later. In this post, we will talk about what Regex (regular expression) is, and how can you use Regex to match HTML tags in web scraping.
What Is the Regular Expression (Regex)
“A regular expression (sometimes called a rational expression) is a sequence of characters that define a search pattern, mainly for use in pattern matching with strings, or string matching, i.e. “find and replace”- like operations. The concept arose in the 1950s when the American mathematician Stephen Kleene formalized the description of a regular language and came into common use with the Unix text-processing utility ed (a line editor for the Unix operating system), an editor, and grep (a command-line utility for searching plain-text data sets for lines matching a regular expression), a filter (a computer program or subroutine to process a stream, producing another stream).” This is an excerpt from Wikipedia used to define regular expression.
As obscure as it sounds, the concept is actually quite easy to understand. Say that you want to find a certain movie on Netflix, you’d probably search with the title of the Movie or even part of the title. Netflix’s search engine would then go on to look for any movie with titles matching what you’ve input into the search box and show you a list of search results that matches your search keywords. Likewise, regular expressions are like the words you’ve used to search for the movie that you want to find.
Essentially, regular expressions are text patterns that you can use to match elements or replace elements throughout strings of text. Regex can be more powerful than you think because of how incredibly flexible it is for cleansing text-based data.
What You Can Do with Regex
In short, regular expressions can be used to match HTML tags and extract the data in HTML documents.
Common Regex Use Cases
Regular expressions are helpful for matching common text patterns, such as emails, phone numbers, zip codes, etc.
HTML is practically made up of strings, and what makes regular expression so powerful is, that a regular expression can match different strings. Admittedly, using regular expressions for parsing HTML can often lead to mistakes like missing closing tags, mismatching some tags, etc. Programmers are more likely to use other HTML parsers like PHP Query, Beautiful Soup, html5lib-Python, etc. However, if you want to quickly match HTML tags, you can use this incredibly convenient tool to identify patterns in HTML documents. Every programmer or anyone who wants to extract web data is strongly recommended to learn about regular expressions for how this tool can greatly improve work efficiency and productivity.
Examples of Regex to match HTML tags
- Regular expressions for matching HTML tags:
<(.)>.?|<(.) />
<(\S?)[^>]>.?|<.*?/>
- Regular expression to match all TD tags:
<td\s*.*>\s*.*<\/td>
- Regular expression to match <img src=”test.gif”/>:
<[a-zA-Z]+(\s+[a-zA-Z]+\s*=\s*(“([^”])”|'([^’])’))\s/>
We can match a variety of HTML tags by using such a regular expression and therefore easily extract data in HTML documents.
You can also check this Regular Expressions Cheat Sheet to have a quick reference for Regex.
Also, here are some popular online Regex testing and debugging tools to help generate or verify the right expressions:
Octoparse: Free Regex Tool Use in Web Scraping
If you need to scrape and reformat web data at the same time, try Octoparse, the best web scraping tool, which also works as a free Regex tool for you to match HTML tags when scraping.

Turn website data into structured Excel, CSV, Google Sheets, and your database directly.
Scrape data easily with auto-detecting functions, no coding skills are required.
Preset scraping templates for hot websites to get data in clicks.
Never get blocked with IP proxies and advanced API.
Cloud service to schedule data scraping at any time you want.
Octoparse Regex tool is a built-in tool that offers a handy way to generate Regular Expressions automatically by setting up various criteria. When knowing little about how to create a regular expression syntax, the Regex tool would be especially helpful. It helps to match out and replace characters in a field value to refine the extracted data directly.
In Octoparse, there are two ways to access the Regex tool:
Method 1: Within Octoparse Clean Data options
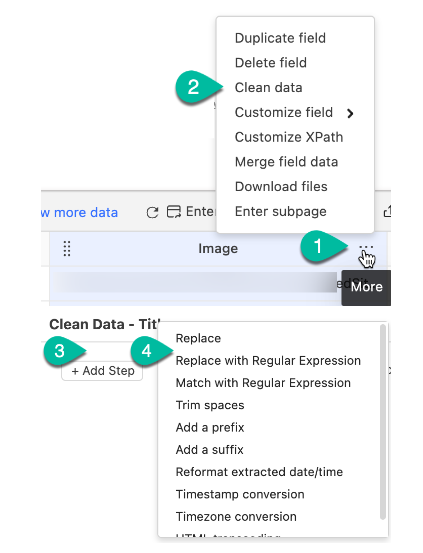
- Select the data field you want to customize
- Click “…” and choose “Clean Data“
- Click “Add step”
- Choose “Replace with Regular Expression” or “Match with regular expression”
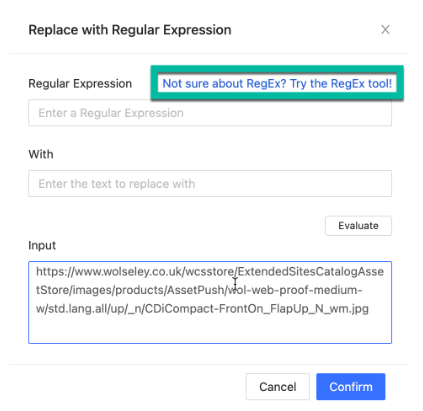
- Click “Not sure about RegEx? Try the RegEx tool!“
Method 2: From the Sidebar Navigation
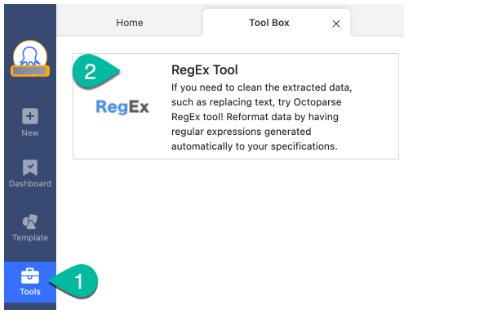
- Select the “Tool Box” icon from the bottom of the sidebar navigation
- Click “RegEx Tool”
In the following 2 cases, you will find out how the Regex tool works in Octoparse.
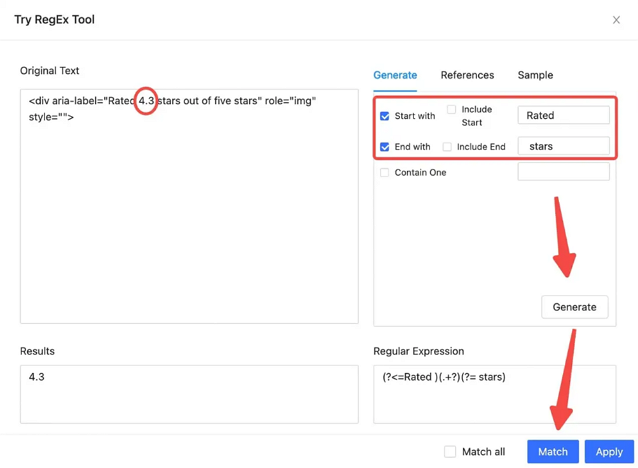
Case 1: Using nearby characters to locate the text
If you want to get the rating information from the HTML below, you can use Octoparse’s Regex tool to match the elements by using nearby “Start with” and “End with” characters.
<div aria-label=”Rated 4.3 stars out of five stars” role=”img”>
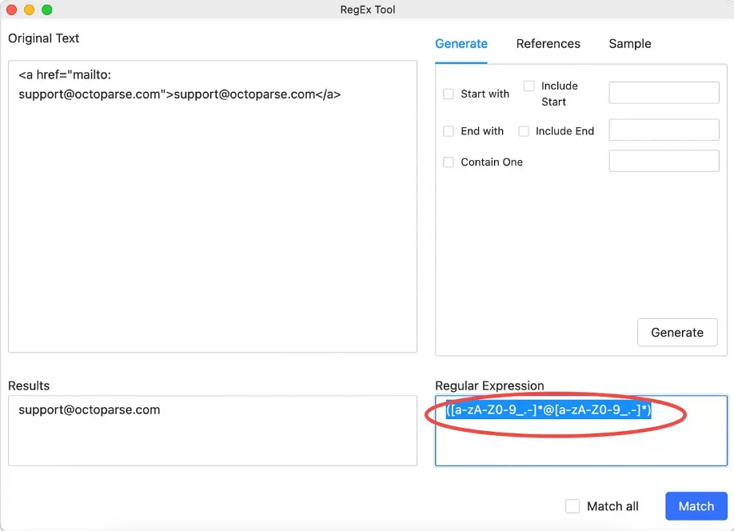
Case 2: Write Regex to extract specific info (like email, websites, etc.)
If you want to extract emails from the source code (especially for some URLs sharing different structures), you can use the Regex below directly to match the email. You can test and debug your regular expressions right away with the tool.
([a-zA-Z0-9_.-]@[a-zA-Z0-9_.-])
If you still have any questions about using Regex in Octoparse when web scraping, you can read the user guide about Octoparse Regular Expression Tool to learn more details.




