Information explodes in the 21st century. News is presented with tags or under categories to prevent readers from being swallowed by irrelevant information. Text classification in NLP comes to the rescue.
To meet this end, a news aggregator shall not only gather up-to-date news feeds but also put them under the right tag.
With loads of news churning out every day, we need an automated solution – web scraping and machine learning. Or else, coping with voluminous information is just impossible for a human.
This blog is to introduce some automated methods to build a news aggregator.
- News data scraping
- Automated updates
- Sort them into categories
News Aggregators
What’s a news aggregator website?
According to Wikipedia, a news aggregator is “client software or a web application that aggregates syndicated web content such as online newspapers, blogs, podcasts, and video blogs (vlogs) in one location for easy viewing”. RSS reader is a classic example.
News aggregators have evolved from as early as 1999 if we regard RSS as a start.
A news aggregator now takes new forms such as Google News, Feedly, and Flipboard. Sophisticated features have been developed to give the audience a better user experience.
However, news classification is the primary that no news aggregator would ignore.
How to Scrape News from the Web
First, an aggregator website shall have the capacity to aggregate. Therefore, the first question to be answered is this:
How to extract news from different sources efficiently?
Typically, there are 3 ways to get web data easily:
- API
- Web scraping
- Find a Data service
Sometimes, people may resort to data providers for web data, but this is not practical if you are running a news aggregator. News is changing fast and coming up on a large scale. We need a faster, more cost-efficient solution.
API
API stands for Application Programming Interface. It is access offered by the host and with the API connected, information granted can be acquired directly from the client or application.
Still confused? Try this API in plain English.
When you shall use API to extract news for your aggregator website? Here is a checklist:
- You are an experienced developer, able to handle API connections and maintain them.
- The news source offers API service to the public.
- The API offers the news feeds you need for your website.
- You are not gathering data from a load of sources.
Not all sources offer an API and in most cases, an API offers only limited information to the public.
As each API is offered by different providers, ways of connecting to them differ. If you are sourcing data from 50 publications, you shall build a data pipeline 50 times and maintain them in the future.
That’s a lot. Of course, if you have a development team devoted to data collection, it could be an option.
Web Scraping
Unlike APIs, web scraping gathers data from the HTML file.
Since you are getting data written in the HTML source code, you are not restricted by the host, and mostly what you can see in the browser, you can get through web scraping.
This is essential for a news aggregator – get the news!
I won’t go into anything like web scraping Python or Node.js. To be honest, they are beyond my reach. Writing scripts to scrape web data requires strong skills and effort in both the creation and maintenance of scrapers. What I want to share is a no-code way of getting data through web scraping.
That is to use a no-code web scraping tool like Octoparse. It helps make the scraper creation process much easier and frees us from many challenges we must face if we do this on our own.
The thing is you should invest 1 or 2 weeks in learning its interface and workflow so that you can start to build yourself web scrapers. For a news aggregator website, data has to be updated frequently. Features like task scheduling for automated data scraping, and integration into the database can save your day.
Sign up here for the 14-day trial and Octoparse’s support team will escort you throughout the journey.
News/Text Classification with NLP
“Text classification – the procedure of designating predefined labels for text – is an essential and significant task in many Natural Language Processing(NLP) applications.”
—— A Survey on Text Classification: From Shallow to Deep Learning [2020]
Shallow Learning: from Manual to Automated
In the early stage, the news was sorted manually. Publishers would scan through leaps of news and articles with bare eyes, pick out the qualified, and put them into designated categories.
Manual work is unnecessarily slow and error-prone. As machine learning and NLP evolves, more automated solutions are available for publishers to classify the news.
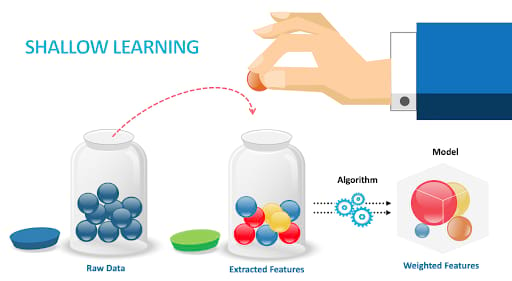
From the 1960s to the 2010s, shallow learning dominated the text classification models, such as Naive Bayes(NB), and K-nearest neighbor(KNN). Features have to be defined by the data scientists and when this is done perfectly, the algorithm will help predict the categories of the news based on such features.
Note: By Christopher Bishop, a feature is known as an individual measurable property or characteristic of a phenomenon being observed.
Deep Learning Methods
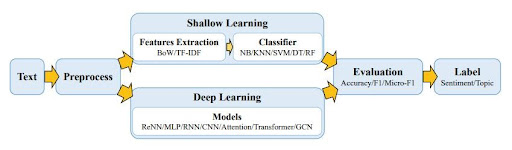
Since the 2010s, deep learning models have prevailed (such as CNN, GCN, and ReNN) and they are now more widely applied to classify text in NLP applications than shallow learning models.
Why is that?
Deep learning models’ main distinguishing difference from that shallow learning is those deep learning methods are capable of feature learning, deriving their features directly from data, while shallow learning relies on humans to define.
Deep learning methods are not destined to outperform shallow learning models. You may choose a method that fits your datasets and this could depend on how you want the texts to be classified.
Is Content/News Curation Legal
This is a serious question. No one wants to create a website at the expense of breaking the law and going to jail. And this is a complex one to answer as well. Here are some thoughts to be shared, and if you are concerned with the legality issue, consult your legal counsel when you have your business model decided.
- Take a look at GDPR.
This is the data protection law implemented by the EU. You should be cautious when you are scraping any personal data of EU residents.
“‘Personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person;”
If you are scraping the personal data of EU citizens, better make sure you have got a lawful reason for doing so, for example, with consent granted, or a contract signed. Or else, you are doing it for the public interest.
- Check if you are compliant with U.S. Copyright Law.
If you are scraping data that is owned by a U.S. citizen or entity, pay attention to the fair use of the data. There are four aspects mentioned in the law:
- Purpose and character of the use, including whether the use is commercial or is for nonprofit educational purposes.
- Nature of the copyrighted work: Using a more creative or imaginative work (such as a novel, movie, or song) is less likely to support fair use than using a factual work (such as a technical article or news item).
- Amount and substantiality of the portion used about the copyrighted work as a whole.
- Effect of the use upon the potential market for or value of the copyrighted work.
Some web scraping projects are in the gray area and it is not easy to get a yes or no answer to the question. There are many factors relating to legality and if you are interested, some real cases in history can bring you more insights into this issue.
Conclusions
Starting a business takes a load of effort, of course. While it is accessible when you have been equipped with some basic knowledge and ways to do it. Building up a news aggregator website, you can get started with web scraping for data extraction and NLP techniques for data processing.
In the end, Octoparse will always have you covered for any web data needs. If you want to try the magic of web scraping, download Octoparse here. The 14-day trial is also available for you to check if our service is suitable.