Web scraping is the technique to get web content for our own use. It is widely used in all industries. For freelance writers, they may extract online articles for topic research. For businesses of all sizes, they extract data from websites to proceed with business analysis. Here are some tips on how to get content from websites.
For programmers or developers, using python is the most common way to build a web scraper/crawler to extract web content. But for most people who do not have coding skills, it would be better to use some web content extractors to get specific content from web pages. Although there are various web scraping tools in the marketplace nowadays, we recommend you to try Octoparse and you will be surprised by its powerful functions.
An Introduction to Octoparse Content Extractor
Octoparse is a web scraping tool to capture web data at scale. With Octoparse, you can interact with any element on a webpage and design your own data extraction workflow. It allows in-depth customization of your own task to meet all your needs. On the other hand, it also provides over 100 built-in template scrapers and easily gets data from Google Maps, Amazon, eBay, etc. Octoparse offers different crawling subscription plans. The free plan is good enough for basic scraping/crawling needs and the paid plan is good for those who require advanced features. If you are not ready to pay, you are always welcome to try it out first by enrolling in our 14-day free trial and enjoying all the paid features.
From there, you can use Octoparse’s Cloud-based service and run your tasks on the Cloud Platform, enabling data crawling at a much higher speed. Moreover, you can automate your data scraping and use Octoparse’s anonymous proxy feature. That means your task will rotate through tons of different IPs, which will prevent you from being blocked by certain websites. Octoparse also provides an API to connect your system to your scraped data in real-time. You can either import the Octoparse data into your own database or use the API to require access to your account’s data. After you finish configuring your task, you can export data into various formats for further uses.
6 Ways to Extract Contents from Webpage Without Coding
1. Extract content from the dynamic web page
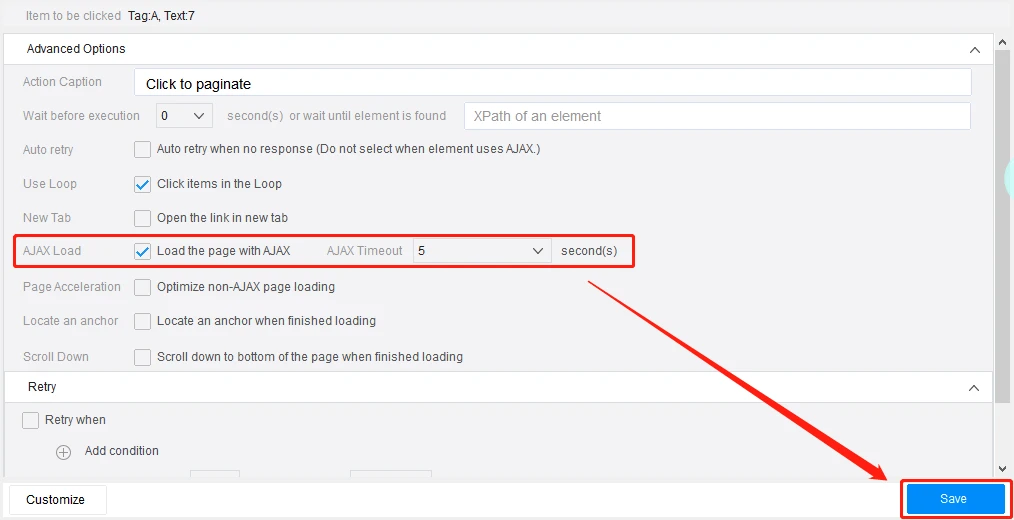
Web pages can be either static or dynamic. It’s often the case that the web content you want to extract would change throughout the day. It is often the case that the website will apply AJAX technique. Ajax allows the webpage to send and receive data from the background without interfering with the webpage display. In this case, you can check the AJAX option to allow Octoparse to extract content from dynamic web pages.
2. Extract content that is hidden from the web page
Have you ever wanted to get specific data from a website but the content would appear after you trigger a link or hover the mouse pointer over? For example, some contact information on craigslist.org will appear after you click the Reply button.
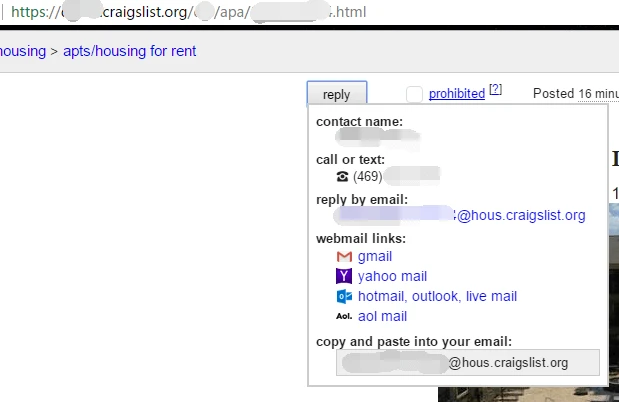
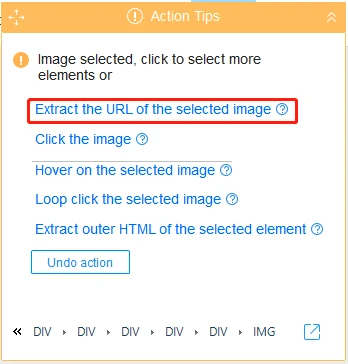
In fact, such hidden content could be found in the HTML source code of this web page. Octoparse can extract the text between the source code. It’s easy to use the “Click Item” command or a “Cursor over” command under the “Action Tip” Panel to achieve the action of extraction.
3. Extract content from the web page with infinite scrolling
You may also notice some messages are only uploaded once you scroll to the bottom of the web page like Twitter. This is because the websites apply infinite scroll. Infinite scroll usually accompanies AJAX or JavaScript to make the requests happen as you reach the end of the webpage. In this case, you can set the AJAX timeout, select the scrolling method and scrolling times to customize how you want the robot to extract the content.
4. Extract hyperlinks from the web page
A normal website will contain at least one hyperlink and if you want to extract all the links from one web page, you can use Octoparse to help you extract all URLs of the whole website.
5. Extract text from the web page
If you want to extract the content place between HTML tags such as <DIV> tag or <SPAN> tag. Octoparse enables you to extract all the text between the source code.
6. Extract images from the web page
With the Octoparse 8.5.4 new version, it could download the image while scraping now. You can download all sorts of files including not only the images, but also videos, documents and other formats. All the downloaded files will be saved to a local folder of your choice. Document downloads in jpg, png, gif, doc, pdf, ppt, txt, xls, and zip formats are currently supported.
Octoparse can extract anything displayed on the web page, and export to structured formats like Excel, CSV, HTML, TXT and other databases. Octoparse is a powerful web scraping tool without a prior tech background. If you are looking for a one-stop data solution, Octoparse also provides a web data service. Therefore, try Octoparse if you have the need of web scraping and let it help you to do the scraping work.