It’s pretty easy to get an URL from any website. Control+C and Control+V, done! But what if you need to gather hundreds and thousands of URLs for a website? I don’t think we would love to do the copy-paste over and over again. In this case, a URL scraper is necessary.
How to Build A URL/Link Scraper
In this article, I would love to show you how to build a URL scraper within minutes without coding. Everyone can nail it down after reading through the whole article.
Basics
Step 1: Install Octoparse on your computer.
In this case, I will use the Octoparse to present how to build a URL scraper. If you want to follow up on this lesson, simply download the Octoparse.
Step 2: Prepare Octoparse Scraping 101.
Before using a new tool, it’s better to be familiar with its working logic. Thus, if you’re new to Octoparse, please go check how Octoparse works in general.
Step 3: Choose one of the following methods to build a URL Scraper.
Method 1: Click on the image to extract the URL directly
Method 2: Scrape the source code and reformat
Let’s get started!!
Method 1: Click on the image to extract the URL directly
In this case, I will show you how to scrape the laptop image URLs on BestBuy. Simply search “Laptop” on BestBuy, you could get the URL (https://www.bestbuy.com/site/searchpage.jsp?st=laptop&_dyncharset=UTF-8&_dynSessConf=&id=pcat17071&type=page&sc=Global&cp=1&nrp=&sp=&qp=&list=n&af=true&iht=y&usc=All+Categories&ks=960&keys=keys) of the search result.
1) Open Octoparse on your computer. Then click to enter “Advanced Mode”
2) Simply copy and past the Bestbuy URL, you have into the website box. Then, click the “Save URL” bottom. With the above steps, you could have the website opened in the Octoparse built-in browser.
3) Generally speaking, we need the image URLs from all pages or as many as possible. Is that difficult? Of course not when you use Octoparse.
After clicking “>” on the website in Octoparse, you can see some options on the Action Tips penal. These options are generated automatically by Octoparse Algorithm.
Then, simply create a loop item by clicking the “Loop click next page”
Now, the loop is created in the workflow.
4) Now, we can click on the image to extract the URL directly.
Click on two of the images on the webpage, helping Octoparse to recognize the IMG field. Once Octoparse success recognizes the image successfully, we are able to see the “IMG” element display on the bottom of the Action Tips penal.
Then, just follow the tips to click “Extract the Image URL in loop”.
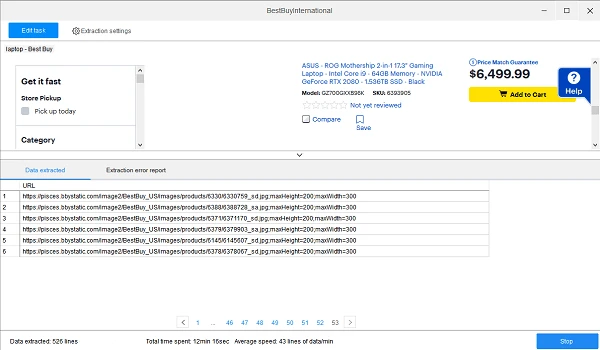
5) With the above 4 steps, we have created a URL scraper in Octoparse. The final step is to extract the image URLs.
Click “Start extraction” – “Local extraction”, then Octoparse starts to gather the Image URLs.
Method 2: Scrape the source code and reformat
To demonstrate this method, I would like to show you how to gather the image URLs on bing.com. The target URL is :
1) Open the target website in Octoparse, which is similar to what we did previously.
2) After having the target URL opened in Octoparse’s built-in browser, we simply need to click on the page randomly. Then, we click “<<” and select “HTML” on the bottom of the Action Tips penal.
Then, we can simply select “extract outer HTML of the selected element” to get the source code of the whole website. The whole HTML is displayed in the Data Customization Area.
Go back to the website, on your own browser, and press Ctrl + Shift + I, you can see the HTML of the website. If you’re careful enough, you can easily figure out the shared features of the image URLs. They start with “https://” and end with “” id=”. Once we get this, we can easily to pick the image URLs out of the sources code by using the Octoparse tool, called “Reformat”
3) Let’s go back to Octoparse! Click the highlighted icon on the Data Customization Area.
Then, we have 4 options for us to further customize the data we selected. In this case, what we need to do is to “Refine extracted data”.
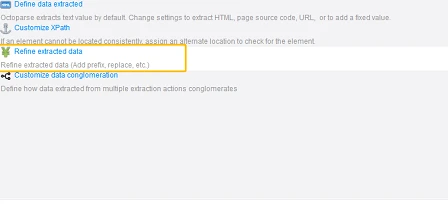
Click “Add step” and we can see the reformat options. Choose “Match with Regular Expression”. Click “Try RegEx Tool”.
Then, simply fill in the blanks, telling Octoparse what data format you want. Octoparse will automatically generate the RexEx and help pick out the information you need.
After some clicks, we can see all the URLs on the page appear on the left bottom box.
4) Now, we can extract the data with the URL scraper we built just now!
Are these two methods of building a URL scraper easy for you? Anyway, just do it and you will know! If there is any problem you encounter when creating the URL scraper, you’re so welcome to contact support at support@octoparse.com
Besides, although the methods are about building an image URL scraper, you could extend that to create a video URL scraper or an email scraper according to your needs. The logic of creating a URL scraper is the same!




