Big Data is all around us. As everyone is aware, there are unbelievable amount of data available on the Internet – most of all data is unstructured data, useful and obscure. It’s impossible to find only one little piece of information among the data ocean without search engines. So how do the search engines gather and organize data for us? The answer is web crawlers, programs that crawl through the Internet in an automated way and get the information that requested. The process is called web crawling(known as web scraping and spidering).
Web crawlers can help your business to get large volume of data such as government data, manufacturing data, healthcare data, education data, media data, etc. from the web for your further uses. And now the question is, how to catch crawlers’ attention in the right way?
For most big companies they prefer to hire some web crawler specialists or a company to build their web crawler for the continued need for data. Excellent web crawler specialists can pull specific data from numerous websites with dynamic content using JavaScript, AJAX, jquery and etc and respect all websites’ terms of use.
For individuals, they will more likely to look for tools to glean the information from the web. Some of them are building a web crawler in Python (scrapy or pyspider), Java, C, C++, C#, PHP, NodeJS or any other languages. Some of them who don’t have coding experience will buy some web crawling tools to gather the data by learning the tools.
Obviously, it’s unrealistic for individuals to build a development team on a limited budget and you need to calculate the cost-effectiveness of a ready-made web crawler before making a purchase. To add Insult to Injury, more and more websites implement effective anti-scraping measures (such as entering CAPTCHA, requiring login) to prevent web crawlers.
So, for individuals, how to make a web crawler to collect information from the web legally?
As the saying goes, “Demand determines supply”. To make a simple web crawler, I will introduce a powerful yet easy-to-use web crawling tool. Anyone (even for someone who is not a techie guy) can easily use it to make a web crawler to pull the information from websites.
User-friendly Web Crawler – Octoparse
Free software
Free download Octoparse client for Windows before making a web crawler.
Visual operation panel
The point-&-click UI and the Workflow Designer visualize a process of making a crawler.
No coding needed. What you click on the web page will generate the crawler automatically.
Advanced crawling options
For techie guys, Octoparse offers several advanced options which can help to scrape dynamic web pages or websites that implement anti-scraping techniques.
Use the data you crawled
Export the crawled data to CSV, Excel, HTML, Text or use Octoparse API to link the data to your machine.
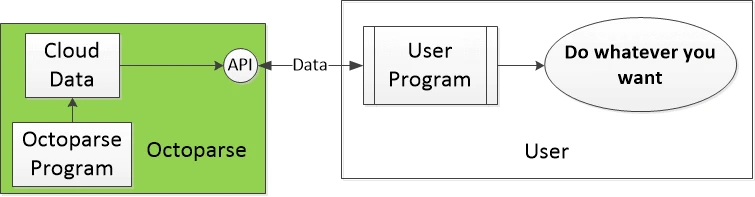
Cloud servers to collect large volumes of data
To collect large amounts of data within a short time, you need to use their cloud servers to gather the data day and night. It could be scheduled or continuously crawled to get fresh data (real-time data).
IP rotation
To avoid your IP from being blocked, Octoparse provides many rotating IP address proxy servers for their paying users.
Would you like to learn more? Check out the tutorials and try to make a web crawler now!




